什么是缓冲区Channel
之前讨论的所有channel都是不带缓冲区的,因此读取和写入都会被阻塞。创建一个带缓冲区的channel也是可能的,这种channel只有在缓冲区满后再写入或者读取一个空的channel时才会被阻塞。
创建一个带缓冲区的channel需要一个额外的参数容量来表明缓冲区大小:
ch := make(chan type, capacity)
上面代码中的 capacity 需要大于0,如果等于0的话则是之前学习的无缓冲区channel。
package main import ( "fmt" ) func main() { ch := make(chan string, 2) ch <- "naveen" ch <- "paul" fmt.Println(<- ch) fmt.Println(<- ch) }
上面的例子中,我们创建了一个容量为2的channel,所以在写入2个字符串之前的写操作不会被阻塞。然后分别在12、13行读取,程序输出如下:
root@ubuntu:~/go_learn/example.com/hello# ./hello
naveen
paul
package main import ( "fmt" ) func main() { ch := make(chan string, 2) ch <- "naveen" ch <- "paul" ch <- "dirk" fmt.Println(<- ch) fmt.Println(<- ch) }
fatal error: all goroutines are asleep - deadlock! goroutine 1 [chan send]: main.main() /root/go_learn/example.com/hello/hello.go:12 +0x80
package main import ( "fmt" ) func main() { ch := make(chan string, 2) ch <- "naveen" ch <- "paul" fmt.Println(<- ch) ch <- "dirk" fmt.Println(<- ch) fmt.Println(<- ch) }
root@ubuntu:~/go_learn/example.com/hello# ./hello
naveen
paul
dirk
一个例子
我们再来看一个例子,我们在并发执行的goroutine中进行写操作,然后在main goroutine中读取,这个例子帮助我们更好的理解缓冲区channel。
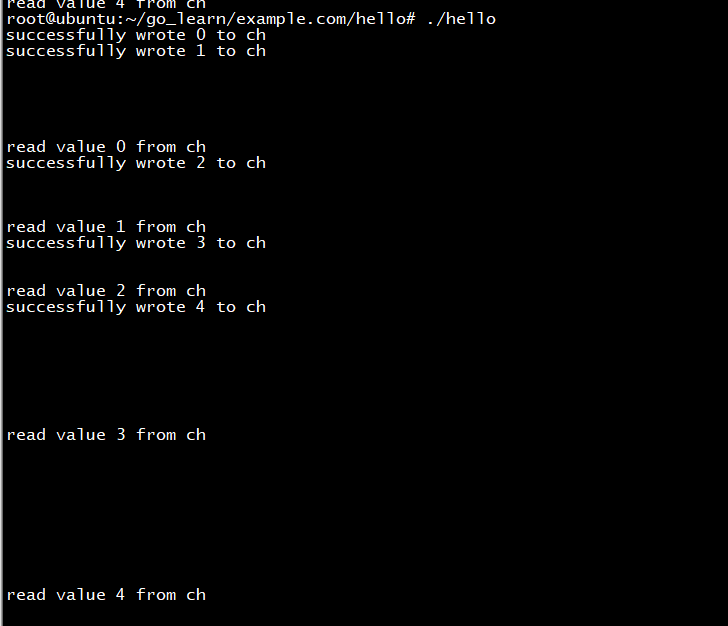
package main import ( "fmt" "time" ) func write(ch chan int) { for i := 0; i < 5; i++ { ch <- i fmt.Println("successfully wrote", i, "to ch") } close(ch) } func main() { ch := make(chan int, 2) go write(ch) time.Sleep(2 * time.Second) for v := range ch { fmt.Println("read value", v,"from ch") time.Sleep(2 * time.Second) } }
上面的代码,我们创建了一个容量是2的缓冲区channel,并把它作为参数传递给write函数,接下来sleep2秒钟。同时write函数并发的执行,在函数中使用for循环向ch写入0-4。由于容量是2,所以可以立即向channel中写入0和1,然后阻塞等待至少一个值被读取。所以程序会立即输出下面2行:
successfully wrote 0 to ch
successfully wrote 1 to ch
当main函数中sleep2秒后,进入for range循环中开始读取数据,然后继续sleep2秒钟。所以程序接下来会输出:
read value 0 from ch
successfully wrote 2 to ch
如此循环直到channel被关闭为止,程序最终输出结果如下:
root@ubuntu:~/go_learn/example.com/hello# ./hello successfully wrote 0 to ch successfully wrote 1 to ch read value 0 from ch successfully wrote 2 to ch read value 1 from ch successfully wrote 3 to ch read value 2 from ch successfully wrote 4 to ch read value 3 from ch read value 4 from ch
中间有sleep

长度和容量
容量是指一个有缓冲区的channel能够最多同时存储多少数据,这个值在使用make关键字用在创建channel时。而长度则是指当前channel中已经存放了多少个数据。我们看下面的代码:
package main import ( "fmt" ) func main() { ch := make(chan string, 3) ch <- "naveen" ch <- "paul" fmt.Println("capacity is", cap(ch)) fmt.Println("length is", len(ch)) fmt.Println("read value", <-ch) fmt.Println("new length is", len(ch)) }
上面的代码中我们创建了一个容量为3的channel,然后向里面写入2个字符串,因此现在channel的长度是2。接下来从channel中读取1个字符串,所以现在长度是1。程序输出如下:
./hello capacity is 3 length is 2 read value naveen new length is 1
WaitGroup
下一节我们将要介绍线程池(worker pools),为了更好的理解,我们需要先介绍WaitGroup,然后我们基于这个实现线程池。
WaitGroup用来等待一组goroutine都执行完毕,在这之前程序都会被阻塞。假设我们有3个goroutine,主程序会等待这3个goroutine都执行结束才会退出。不多说看代码:
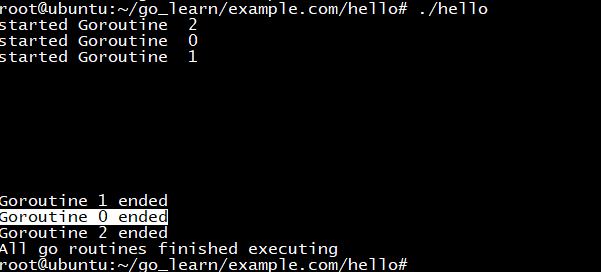
package main import ( "fmt" "sync" "time" ) func process(i int, wg *sync.WaitGroup) { fmt.Println("started Goroutine ", i) time.Sleep(2 * time.Second) fmt.Printf("Goroutine %d ended ", i) wg.Done() } func main() { no := 3 var wg sync.WaitGroup for i := 0; i < no; i++ { wg.Add(1) go process(i, &wg) } wg.Wait() fmt.Println("All go routines finished executing") }
WaitGroup是一种struct类型,我们在18行创建了一个默认值的WaitGroup,其内部是基于计数器实现的。我们调用Add方法并传递给其一个数字作为参数,计数器将增长传入参数的值。当调用Done方法,计数器将自减1。Wait方法阻塞goroutine直到计数器归零。
上面的代码中通过在循环中调用wg.Add(1)来使计数器变成3,同时启动3个goroutine,然后掉用wg.Wait()阻塞主goroutine,直到计数器归零。在函数process中,调用wg.Done()来减小计数器,一旦三个goroutine执行结束,wg.Done()将被执行3次,计数器归零,主goroutine解除阻塞。
传递wg的地址给goroutine是非常重要的!如果传递的不是地址,那么每个goroutine都将有一份拷贝,这样的话每个goroutine结束就不能通知到main函数了。
程序输出如下: