概述
sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具。
导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
导出数据:从Hadoop的文件系统中导出数据到关系数据库
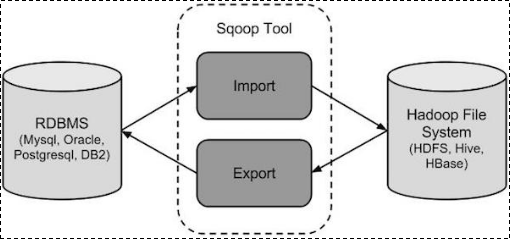
工作机制
将导入或导出命令翻译成mapreduce程序来实现
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制
sqoop实战及原理
sqoop安装
安装sqoop的前提是已经具备java和hadoop的环境
1.下载并解压
最新版下载地址http://ftp.wayne.edu/apache/sqoop/1.4.6/
2.修改配置文件
$ cd $SQOOP_HOME/conf
$ mv sqoop-env-template.sh sqoop-env.sh
打开sqoop-env.sh并编辑下面几行:
export HADOOP_COMMON_HOME=/home/hadoop/apps/hadoop-2.6.1/
export HADOOP_MAPRED_HOME=/home/hadoop/apps/hadoop-2.6.1/
export HIVE_HOME=/home/hadoop/apps/hive-1.2.1
3、加入mysql的jdbc驱动包
cp ~/app/hive/lib/mysql-connector-java-5.1.28.jar $SQOOP_HOME/lib/
4、验证启动
$ cd $SQOOP_HOME/bin
$ sqoop-version
预期的输出:
15/12/17 14:52:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
Sqoop 1.4.6 git commit id 5b34accaca7de251fc91161733f906af2eddbe83
Compiled by abe on Fri Aug 1 11:19:26 PDT 2015
到这里,整个Sqoop安装工作完成。
Sqoop的数据导入
“导入工具”导入单个表从RDBMS到HDFS。表中的每一行被视为HDFS的记录。所有记录都存储为文本文件的文本数据(或者Avro、sequence文件等二进制数据)
语法
下面的语法用于将数据导入HDFS。
|
$ sqoop import (generic-args) (import-args) |
导入表表数据到HDFS
下面的命令用于从MySQL数据库服务器中的emp表导入HDFS。
$bin/sqoop import
--connect jdbc:mysql://hdp-node-01:3306/test
--username root
--password root
--table emp
--m 1
m是启动reduce个数的的意思。
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据
$ $HADOOP_HOME/bin/hadoop fs -cat /user/hadoop/emp/part-m-00000
如果报错:

从错误信息中需要访问端口 10020 可以大概看出,DataNode 需要访问 MapReduce JobHistory Server,如果没有修改则用默认值:0.0.0.0:10020 。需要修改配置文件 mapred-site.xml :
[html] view plain copy <property> <name>mapreduce.jobhistory.address</name> <!-- 配置实际的主机名和端口--> <value>master:10020</value> </property>
并且启动MapReduce JobHistory Server服务:
在namenode上执行命令:
1.sbin/mr-jobhistory-daemon.sh start historyserver
导入关系表到HIVE
bin/sqoop import --connect jdbc:mysql://hdp-node-01:3306/test --username root --password root --table emp --hive-import --m 1
导入到HDFS指定目录
在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。
以下是指定目标目录选项的Sqoop导入命令的语法。
|
--target-dir <new or exist directory in HDFS> |
下面的命令是用来导入emp_add表数据到'/queryresult'目录。
bin/sqoop import
--connect jdbc:mysql://hdp-node-01:3306/test
--username root
--password root
--target-dir /queryresult
--table emp --m 1
下面的命令是用来验证 /queryresult 目录中 emp_add表导入的数据形式。
|
$HADOOP_HOME/bin/hadoop fs -cat /queryresult/part-m-* |
它会用逗号(,)分隔emp_add表的数据和字段。
|
1201, 288A, vgiri, jublee 1202, 108I, aoc, sec-bad 1203, 144Z, pgutta, hyd 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad |
导入表数据子集
我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
where子句的语法如下。
|
--where <condition> |
下面的命令用来导入emp_add表数据的子集。子集查询检索员工ID和地址,居住城市为:Secunderabad
bin/sqoop import
--connect jdbc:mysql://hdp-node-01:3306/test
--username root
--password root
--where "city ='sec-bad'"
--target-dir /wherequery
--table emp_add --m 1
按需导入
bin/sqoop import
--connect jdbc:mysql://hdp-node-01:3306/test
--username root
--password root
--target-dir /wherequery2
--query 'select id,name,deg from emp WHERE id>1207 and $CONDITIONS'
--split-by id
--fields-terminated-by ' '
--m 1
下面的命令用来验证数据从emp_add表导入/wherequery目录
|
$HADOOP_HOME/bin/hadoop fs -cat /wherequery/part-m-* |
增量导入
增量导入是仅导入新添加的表中的行的技术。
它需要添加‘incremental’, ‘check-column’, 和 ‘last-value’选项来执行增量导入。
下面的语法用于Sqoop导入命令增量选项。+
--incremental <mode> --check-column <column name> --last value <last check column value>
假设新添加的数据转换成emp表如下:
1206, satish p, grp des, 20000, GR
下面的命令用于在EMP表执行增量导入。
bin/sqoop import
--connect jdbc:mysql://hdp-node-01:3306/test
--username root
--password root
--table emp --m 1
--incremental append
--check-column id
--last-value 1208
Sqoop的数据导出
将数据从HDFS导出到RDBMS数据库
导出前,目标表必须存在于目标数据库中。
- 默认操作是从将文件中的数据使用INSERT语句插入到表中
- 更新模式下,是生成UPDATE语句更新表数据
语法
以下是export命令语法。
|
$ sqoop export (generic-args) (export-args) |
数据是在HDFS 中“EMP/”目录的emp_data文件中。所述emp_data如下:
|
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR |
1、首先需要手动创建mysql中的目标表
|
$ mysql mysql> USE db; mysql> CREATE TABLE employee ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT, dept VARCHAR(10)); |
然后执行导出命令
|
bin/sqoop export --connect jdbc:mysql://hdp-node-01:3306/test --username root --password root --table employee --export-dir /user/hadoop/emp/ |
验证表mysql命令行。
|
mysql>select * from employee; 如果给定的数据存储成功,那么可以找到数据在如下的employee表。 +------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | kalil | php dev | 30000 | AC | | 1204 | prasanth | php dev | 30000 | AC | | 1205 | kranthi | admin | 20000 | TP | | 1206 | satish p | grp des | 20000 | GR | +------+--------------+-------------+-------------------+--------+ |