今天在开始关于线程的互斥之前,先对另外一个定时器spring提供的qurtar的用法做一个简单的介绍,同时对比一下与java原生态提供的Timer的区别。
先上一个定时任务的配置吧,这是我们自己的项目中定时任务删除每个表记录的:
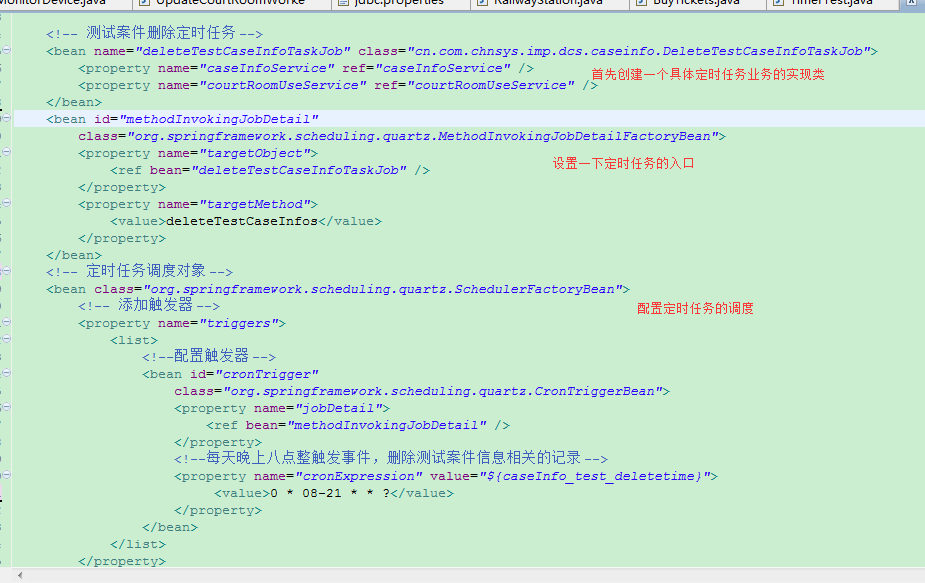
对于具体的任务的业务实现我们不说了,我就说一下quartor是如何调度的。在开始解读源码之前,我们先借用其他网友的观点对这个进行一个概要的介绍:
1. Java定时器没有持久化机制。这个在上一篇中看的TIMER的源码确实没有
2. Java定时器的日程管理不够灵活(只能设置开始时间、重复的间隔,设置特定的日期、时间等)//这点感同身受
3. Java定时器没有使用线程池(每个Java定时器使用一个线程)//想必在用timer是遇到了吧。
4. Java定时器没有切实的管理方案,你不得不自己完成存储、组织、恢复任务的措施
反正就是什么呢,Timer比较单一,如果是一些简单的任务可以使用,企业级的一半还是使用quartor。
好了 下面咱们开始quartot源码的读吧。
读源码之前需要增加一个知识点:
1.InitializingBean 与 afterPorpertiesSet()
关于在spring 容器初始化 bean 和销毁前所做的操作定义方式有三种:
第一种:通过@PostConstruct 和 @PreDestroy 方法 实现初始化和销毁bean之前进行的操作
第二种是:通过 在xml中定义init-method 和 destory-method方法
第三种是: 通过bean实现InitializingBean和 DisposableBean接口
Spirng的InitializingBean为bean提供了定义初始化方法的方式。InitializingBean是一个接口,它仅仅包含一个方法:afterPropertiesSet()。 在spring 初始化后,执行完所有属性设置方法(即setXxx)将自动调用 afterPropertiesSet(), 在配置文件中无须特别的配置, 但此方式增加了bean对spring 的依赖,应该尽量避免使用。
实现org.springframework.beans.factory.DisposableBean接口允许一个bean,可以在包含它的BeanFactory销毁的时候得到一个回调。DisposableBean也只指定了一个方法:
void destroy() throws Exception;
在我使用的这里使用的是第三种,这也就是为什么在我们的定时任务配置文件中看不到init-method的配置的源码。
好了这时候我们看源码,先看SchedulerFactoryBean来创建scheduler实例的类的定义

在这个定义中我们看到SchedulerFactoryBean是显现了initializingBean这个接口和DisposableBean接口,我们从上面的知识点中可以知道,在实现了initilizingBean这个接口的类中,会实现一个方法afterPropertiesSet()。执行这个方法是时机是spring在set所有属性完成后,
下面是借鉴的一个benzero的网友的内容:在我写这个博客的时候网上搜了一下,感觉这哥们写的真是好,我写的话并一定比人家的好,哈哈哈 好东西用来共享啦。但是要标明引自哪里,毕竟有版权啊。
具体来分析afterPropertiesSet()和start(),可以看出afterPropertiesSet()的核心步骤:
1. 实例化一个SchdulerFactory, 此处使用的是默认的StdSchedulerFactory.class
2. 通过Factory获取一个scheduler实例容器。
3. 配置/添加 对该容器指定的listener、jobs、triggers等,本质是将注入的上述属性配合到上步创建的Scheduler容器当中,比较简单,后续忽略介绍。
代码说明的截图:

start()择更为简单,直接启动上面创建的scheduler容器的实例,代码说明截图如下:其中有一个startupDelay的参数,即启动延时,默认都是为0的,一般也是需要即时启动的。

综上,可以看到quatz启动的大概步骤, 利用spring提供的两个回调接口, 分别在bean实例的构造和容器启动阶段实现了 Scheduler容器的构造 和 scheduler的启动。
当然理解架构只到此程度是远远不够的,上述部分的核心是通过Factory获取到一个scheduler实例,即createScheduler()方法,下一节对这个过程做出详细的说明。
第二节.scheduler容器获取(构造)过程
首先,createScheduler()之中的主流程调用树结构如下,其核心是在instantiate()完成的,外部的2层主要做了些读取配置和条件判断等。
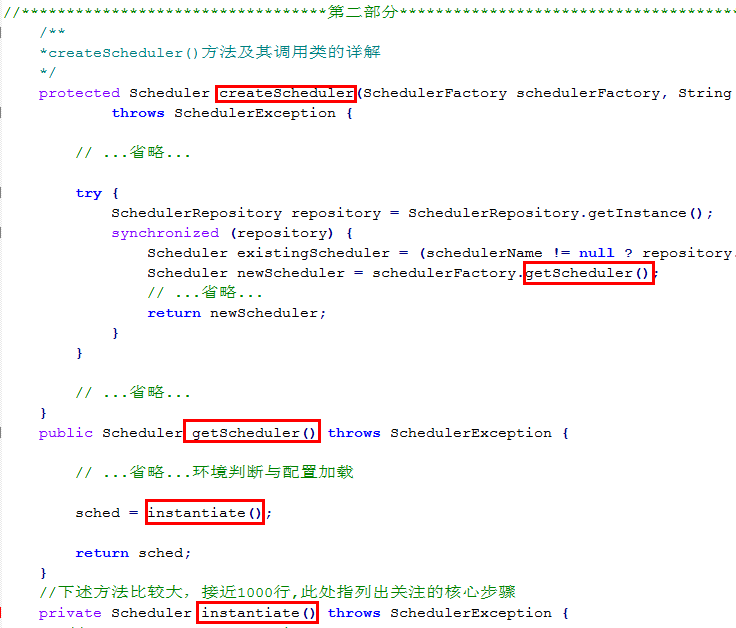
直接来看instantiate()的代码,类比较大且复杂,只列出核心行

1.创建了一个线程池,默认使用的是SimpleThreadPool, 代码中tp对象
2.创建了一个jobStore,默认使用的是RAMJobStore, 代码中的js对象
3.创建一个QuartzScheduler对象, 代码中的qs对象, 下图列出他的创建树。
大体上有4步,有2个关键点需要掌握
a.QuartzScheduler对象保存有QuartzSchedulerThread的引用,实际的调度工作基本上是由QuartzSchedulerThread这个对象做的. 当然实例化QuartzScheduler的目的主要也在于去实例化QuartzSchedulerThread。
b.QuartzSchedulerThread在构造函数中实例化,并一经创建就自启动,它是一个独立的线程,至于自启后做什么,在后面章节说明。下面是quartzScheduler的创建过程

4.创建了scheduler.
4.1. QuartzSchedulerResources 对象,代码中的rsrcs对象
Contains all of the resources,可以将其视为资源缓存对象,包含了所有定时模块的资源的引用。
4.2. Scheduler对象。 看源代码它的直接实例是StdScheduler,但实际StdScheduler中直接引用了QuartzScheduler(qs)且仅止于此,没有额外的动作。 简单的你可以认为这是一层封装。因此你可以认为真正在工作的其实就是QuartzScheduler或者说是 QuartzSchedulerThread
本节主要讲述了整个scheduler容器创建时的过程,以及4个重要的步骤节点。后续章节来分别详述这些核心步骤的具体创建和工作原理。
至此,通过SchedulerFactory构建Scheduler的过程已完成,可以总结为三个要点。
1. 创建线程池
2. 创建JobStore
3. 通过QuartzScheduler启动一个QuartzSchedulerThread
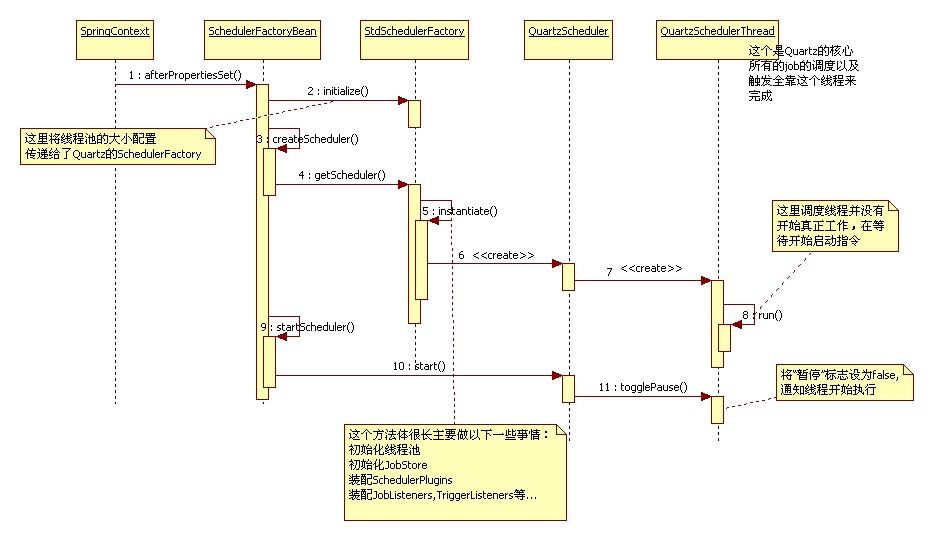
他们的关系如下图,最终返回的这是QuatzScheduler的引用。本图转自网络。

第三节. 对第二节的一个小结
通过对上节真个启动过程的源码解读,应该可以较为深入的理解spring 管理的Quatz的启动流程,网络上一张时序图可以作为很好的参考:
第四节.QuartzSchedulerThread是如何工作的。
在第二节中讲到启动是一个核心步骤就是创建QuartzSchedulerThread并启动它,因为它是继承自Thread的,因此我们可以跟踪它的run方法看它究竟做哪些工作

解析这个方法如下:
1. 方法体是一个无限循环,一直在等任务的出现,然后启动执行。
2. 刚被启动时,是在等pause信号量。 这个信号在何时改变了,也行你已经在上面时序图中看到了, 前面章节提到的start()的实现其本质的工作就是修改这个pause信号量。 使
QuartzSchedulerThread正式进入工作状态(虽然其构造时就被启动,但没有真正开始工作)。
3.总会从jobstore里找出下个应该执行的trigger任务(具体步骤后面解析),然后等待这一时刻到来。(通过不停的比较trigger的时间和当前系统时间)
4. 之后通过jobstore将其对应的jobdetail封装成一个runShell (具体步骤后面解析)
5. 将runShell交给线程池去执行,runInThread方法,下节会具体讲解。
6. 继续循环寻找下一个执行trigger,依次往复。
因此上面提到过其实在quartz里面,真正做实际工作的调度线程其实就是它。
第五节.SimpleThreadPool的介绍
总体来讲,SimpleThreadPool的实现很简单。
第2节介绍createScheduler过程时,提到第一个步骤便是创建一个线程池,该默认的线程池便是SimpleThreadPool. 跟踪源代码可见,最然构建tp实例时未做任何操作,但在实例之后,又调用了SimpleThreadPool.initialize(), 此方法相当于初始配置tp以及启用它。下面来分析源码
a.代码比较简单,注意一点是创建的线程是WorkerThread,因此看具体工作还需要追踪到WorkerThread里面。

B.WorkerThread是一个内部类,看下被启动是具体做什么工作(run方法)。
比较简单,“一直不停的在等待runable类型的事件的注入,一旦进来,就执行”。

本节和上节可以结合在一起归纳一下,QuartzSchedulerThread一直寻找可执行目标,找到后就交给SimpleThreadPool具体执行, 而相应的SimpleThreadPool的线程们也被设计成随时等待runnable事件的注入。举个通俗的例子,QuartzSchedulerThread就是青楼的老妈子,SimpleThreadPool
里的线程就是待接客的姑娘们,老妈子负责不断寻找/接待客人,然后将目标客户引给闲置的姑娘, 具体的接待工作由姑娘完成。
现在提出两个问题,“客人”是如何被找到的? “姑娘”是如何开始接待的? 在下节讨论。
6.RAMJobStore的介绍
JobStore负责保存所有配置到调度器里的工作数据:jobs,triggers,calendars等等,“RAM”顾名思义就是利用内存来持久化调度程序信息。这种作业存储类型最容易配置、构造和 运行,但是当应用程序停止运行时,所有调度信息将被丢失。RAMJobStore是spring+quatz默认的jobstore
在第4节中讲解QuartzSchedulerThread的工作原理中多次提到了jobStore,其中有一个步骤便是通过jobStore获取下一个应该执行的trigger,现在就来具体分析。
A. 利用jobStore获取下一个需要执行的trigger, 此处调用的是acquireNextTrigger()方法。 注意一点,在这步中一般情况下是先将第一个执行的trigger从treeset中删除,然后返回它。 treeset是按照触发是每个trigger最近一次应该执行的时间排序的。 大概原理是这样的,1.往队列添加trigger的时候,是以该trigger的下次触发时间来
确定它在treeset的顺序 2.要执行trigger时,是直接将trigger移出treeset. 3.在恰当的时刻,将该trigger按照第一步加入到treeset

B.上面的一点你可能会思考一个问题,这个trigger的下一次是怎么触发的(因为已经从timeTriggers队列里删除了)。
实际上在第四节的代码讲解中有一句注释的代码,当时没有提及,因这代码前后都有其他逻辑,所以是以注释的形式来展现的。 在此处说明比较合适。

此方法包含了如下操作, 当然包含了诸多其他内容,此处不展开说明:
根据当前的nextFireTime来实现自我更新, 然后将此trigger重新加入到timeTriggers。
而此方法的返回值bndle在C中详解。

C. 第四节讲到拿到Trigger的下一步是创建一个jobshell丢给线程池去执行。现在看看jobShell是如何创建的。
首先B中 triggerFired方法返回的bndle对象,它是TriggerFiredBundle类型,该类属性如下,实质上这些数据也是从jobStore那里引用过来的,封装成一个对象方便后续处理。
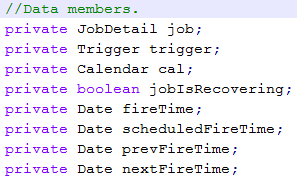
创建runshell的数据来源正是基于这个对象的。 创建runshell实例很简单,对实例的初始化过程主要是由JobRunShell.initialize()方法负责的。具体分析:

runShell创建并初始化之后,是被丢进ThreadPool中执行的,而执行过程就是线程调用runShell的run()方法, 大家可以具体查看,这里由于我整理的文档涉及
我们项目内容,省略掉这一部分。
文档至此,你应当比较全面的了解quatz的初始化过程以及调用机制
三. Spring+quatz的参考文档
以下参考文档分别从各方面侧重介绍了quatz,其中主要参考了《quartz学习笔记》
http://jinnianshilongnian.iteye.com/blog/1902886 详解spring事件驱动模型
http://www.cnblogs.com/yunxuange/archive/2012/08/28/2660141.html quatz 学习笔记
http://www.cnblogs.com/chanedi/p/4169510.html Quartz的线程池解析
http://blog.csdn.net/luccs624061082/article/details/39288275 Spring 之生命周期机制混合使用
http://www.cnblogs.com/langtianya/archive/2013/05/15/3079109.html quatz详解
http://seanhe.iteye.com/blog/691835 Spring对Quartz的封装实现简单分析及使用注意事项
文章部分引自 http://www.cnblogs.com/surprizeFuture/articles/4564293.html