一、并集
Union因为要进行重复值扫描,所以效率低。如果合并没有刻意要删除重复行,那么就使用Union All 两个要联合的SQL语句 字段个数必须一样,而且字段类型要“相容”(一致);
如果我们需要将两个select语句的结果作为一个整体显示出来,我们就需要用到union或者union all关键字。union(或称为联合)的作用是将多个结果合并在一起显示出来。
union和union all的区别是,union会自动压缩多个结果集合中的重复结果,而union all则将所有的结果全部显示出来,不管是不是重复。
- Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
- Union All:对两个结果集进行并集操作,包括重复行,不进行排序;性能高;
- Intersect:对两个结果集进行交集操作,不包括重复行,同时进行默认规则的排序;(MySQL不支持)
- Minus:对两个结果集进行差操作,不包括重复行,同时进行默认规则的排序。性能高;(MySQL不支持)
-
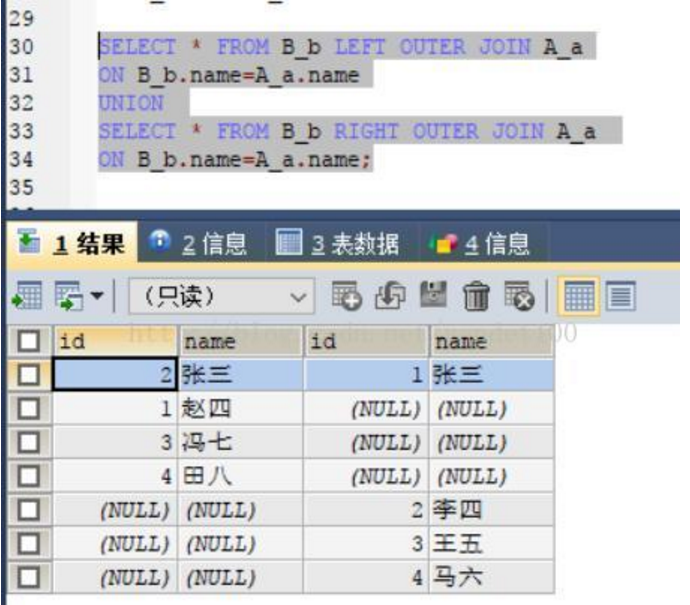
Full Outer Join:全连接,数据库join的用法很简单,今天发现mysql居然不支持全连接。解决方法:left join union right join
可以在最后一个结果集中指定Order by子句改变排序方式。
例如:
select employee_id,job_id from employees
union
select employee_id,job_id from job_history
以上将两个表的结果联合在一起。这两个例子会将两个select语句的结果中的重复值进行压缩,也就是结果的数据并不是两条结果的条数的和。如果希望即使重复的结果显示出来可以使用union all,例如:
2.在oracle的scott用户中有表emp
select * from emp where deptno >= 20
union all
select * from emp where deptno <= 30
这里的结果就有很多重复值了。
有关union和union all关键字需要注意的问题是:
union 和 union all都可以将多个结果集合并,而不仅仅是两个,你可以将多个结果集串起来。
使用union和union all必须保证各个select 集合的结果有相同个数的列,并且每个列的类型是一样的。但列名则不一定需要相同,oracle会将第一个结果的列名作为结果集的列名。例如下面是一个例子:
select empno,ename from emp
union
select deptno,dname from dept
我们没有必要在每一个select结果集中使用order by子句来进行排序,我们可以在最后使用一条order by来对整个结果进行排序。例如:
select empno,ename from emp
union
select deptno,dname from dept
order by ename;
二、差集
MySQL没有交集Intersect、差集Except的实现,一般差集可以通过in和not in来解决。小量数据还可以,但数据量大了效率就很低了。
示例说明:
创建表:
CREATE TABLE `tt1` ( `id` INT(11) NOT NULL, `name` VARCHAR(20) DEFAULT NULL, `age` INT(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=INNODB DEFAULT CHARSET=utf8; CREATE TABLE `tt2` ( `id` INT(11) NOT NULL, `name` VARCHAR(20) DEFAULT NULL, `age` INT(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=INNODB DEFAULT CHARSET=utf8; INSERT INTO tt1 VALUES(1,'小王',10); INSERT INTO tt1 VALUES(2,'小宋',20); INSERT INTO tt1 VALUES(3,'小白',30); INSERT INTO tt1 VALUES(4,'hello',40); INSERT INTO tt2 VALUES(1,'小王',10); INSERT INTO tt2 VALUES(2,'小宋',22); INSERT INTO tt2 VALUES(3,'小肖',31); INSERT INTO tt2 VALUES(4,'hello',40);
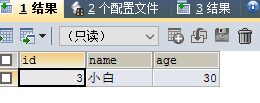
差集:
SELECT tt1.* FROM tt1 WHERE NAME NOT IN (SELECT NAME FROM tt2);
或者 SELECT tt1.id, tt1.name, tt1.age FROM tt1 LEFT JOIN tt2 ON tt1.id = tt2.id WHERE tt1.name != tt2.name;
三、交集
MySQL没有交集Intersect、差集Except的实现,一般交集可以通过HAVING来解决。
示例:
SELECT id, NAME, age, COUNT(*) FROM (SELECT id, NAME, age FROM tt1 UNION ALL SELECT id, NAME, age FROM tt2 ) a GROUP BY id, NAME, age HAVING COUNT(*) > 1

四、full outer join全连接两个表
如图: