1.可重入锁
如果锁具备可重入性,则称作为可重入锁。
==========================================
这种情况出现在多任务系统当中,在任务执行期间捕捉到信号并对其进行处理时,进程正在执行的指令序列就被信号处理程序临时中断。如果从信号处理程序返回,则继续执行进程断点处的正常指令序列,从重新恢复到断点重新执行的过程中,函数所依赖的环境没有发生改变,就说这个函数是可重入的,反之就是不可重入的。
众所周知,在进程中断期间,系统会保存和恢复进程的上下文,然而恢复的上下文仅限于返回地址,cpu寄存器等之类的少量上下文,而函数内部使用的诸如全局或静态变量,buffer等并不在保护之列,所以如果这些值在函数被中断期间发生了改变,那么当函数回到断点继续执行时,其结果就不可预料了。打个比方,比如malloc,将如一个进程此时正在执行malloc分配堆空间,此时程序捕捉到信号发生中断,执行信号处理程序中恰好也有一个malloc,这样就会对进程的环境造成破坏,因为malloc通常为它所分配的存储区维护一个链接表,插入执行信号处理函数时,进程可能正在对这张表进行操作,而信号处理函数的调用刚好覆盖了进程的操作,造成错误。
满足下面条件之一的多数是不可重入函数:
(1)使用了静态数据结构;
(2)调用了malloc或free;
(3)调用了标准I/O函数;标准io库很多实现都以不可重入的方式使用全局数据结构。
(4)进行了浮点运算.许多的处理器/编译器中,浮点一般都是不可重入的 (浮点运算大多使用协处理器或者软件模拟来实现)。
1) 信号处理程序A内外都调用了同一个不可重入函数B;B在执行期间被信号打断,进入A (A中调用了B),完事之后返回B被中断点继续执行,这时B函数的环境可能改变,其结果就不可预料了。
2) 多线程共享进程内部的资源,如果两个线程A,B调用同一个不可重入函数F,A线程进入F后,线程调度,切换到B,B也执行了F,那么当再次切换到线程A时,其调用F的结果也是不可预料的。
在信号处理程序中即使调用可重入函数也有问题要注意。作为一个通用的规则,当在信号处理程序中调用可重入函数时,应当在其前保存errno,并在其后恢复errno。(因为每个线程只有一个errno变量,信号处理函数可能会修改其值,要了解经常被捕捉到的信号是SIGCHLD,其信号处理程序通常要调用一种wait函数,而各种wait函数都能改变errno。)
可重入函数列表:
_exit()、 access()、alarm()、cfgetispeed()、cfgetospeed()、cfsetispeed()、cfsetospeed ()、chdir()、chmod()、chown()、close()、creat()、dup()、dup2()、execle()、 execve()、fcntl()、fork()、fpathconf ()、fstat()、fsync()、getegid()、 geteuid()、getgid()、getgroups()、getpgrp()、getpid()、getppid()、getuid()、 kill()、link()、lseek()、mkdir()、mkfifo()、 open()、pathconf()、pause()、pipe()、raise()、read()、rename()、rmdir()、setgid ()、setpgid()、setsid()、setuid()、 sigaction()、sigaddset()、sigdelset()、sigemptyset()、sigfillset()、 sigismember()、signal()、sigpending()、sigprocmask()、sigsuspend()、sleep()、 stat()、sysconf()、tcdrain()、tcflow()、tcflush()、tcgetattr()、tcgetpgrp()、 tcsendbreak()、tcsetattr()、tcsetpgrp()、time()、times()、 umask()、uname()、unlink()、utime()、wait()、waitpid()、write()。
书上关于信号处理程序中调用不可重入函数的例子:
#include <stdlib.h>
#include <stdio.h>
#include <pwd.h>
static void func(int signo)
{
struct passwd *rootptr;
if( ( rootptr = getpwnam( "root" ) ) == NULL )
{
err_sys( "getpwnam error" );
}
signal(SIGALRM,func);
alarm(1);
}
int main(int argc, char** argv)
{
signal(SIGALRM,func);
alarm(1);
for(;;)
{
if( ( ptr = getpwnam("sar") ) == NULL )
{
err_sys( "getpwnam error" );
}
}
return 0;
}
signal了一个SIGALRM,而后设置一个定时器,在for函数运行期间的某个时刻,也许就是在getpwnam函数运行期间,相应信号发生中断,进入信号处理函数func,在运行func期间又收到alarm发出的信号,getpwnam可能再次中断,这样就很容易发生不可预料的问题。
==========================================
像synchronized和ReentrantLock都是可重入锁,可重入性在我看来实际上表明了锁的分配机制:
基于线程的分配,而不是基于方法调用的分配。
举个简单的例子,当一个线程执行到某个synchronized方法时,比如说method1,而在method1中会调用另外一个synchronized方法method2,
此时线程不必重新去申请锁,而是可以直接执行方法method2。

class MyClass {
public synchronized void method1() {
method2();
}
public synchronized void method2() {
}
}
上述代码中的两个方法method1和method2都用synchronized修饰了,
假如某一时刻,线程A执行到了method1,此时线程A获取了这个对象的锁,而由于method2也是synchronized方法,假如synchronized不具备可重入性,此时线程A需要重新申请锁。
但是这就会造成一个问题,因为线程A已经持有了该对象的锁,而又在申请获取该对象的锁,这样就会线程A一直等待永远不会获取到的锁。
而由于synchronized和ReentrantLock都具备可重入性,所以不会发生上述现象。《可重入锁》
2.可中断锁
可中断锁:顾名思义,就是可以相应中断的锁。
在Java中,synchronized就不是可中断锁,而Lock是可中断锁。
如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。
在前面演示lockInterruptibly()的用法时已经体现了Lock的可中断性。
3.公平锁
公平锁即尽量以请求锁的顺序来获取锁。比如同是有多个线程在等待一个锁,当这个锁被释放时,等待时间最久的线程(最先请求的线程)会获得该所,这种就是公平锁。
非公平锁即无法保证锁的获取是按照请求锁的顺序进行的。这样就可能导致某个或者一些线程永远获取不到锁。
在Java中,synchronized就是非公平锁,它无法保证等待的线程获取锁的顺序。
而对于ReentrantLock和ReentrantReadWriteLock,它默认情况下是非公平锁,但是可以设置为公平锁。这一点由构造函数可知:
1
2 public ReentrantLock() {
3 sync = new NonfairSync();
4 }
5
6
7 public ReentrantLock(boolean fair) {
8 sync = (fair)? new FairSync() : new NonfairSync();
9 }
在ReentrantLock中定义了2个静态内部类,一个是NotFairSync,一个是FairSync,分别用来实现非公平锁和公平锁。
我们可以在创建ReentrantLock对象时,通过知道布尔参数来决定使用 非公平锁 还是公平锁
如果参数为true表示为公平锁,为fasle为非公平锁。默认情况下,如果使用无参构造器,则是非公平锁
另外在ReentrantLock类中定义了很多方法,比如:
isFair() //判断锁是否是公平锁
isLocked() //判断锁是否被任何线程获取了
isHeldByCurrentThread() //判断锁是否被当前线程获取了
hasQueuedThreads() //判断是否有线程在等待该锁
在ReentrantReadWriteLock中也有类似的方法,同样也可以设置为公平锁和非公平锁。
不过要记住,ReentrantReadWriteLock并未实现Lock接口,它实现的是ReadWriteLock接口。
4.读写锁
读写锁将对一个资源(比如文件)的访问分成了2个锁,一个读锁和一个写锁。
正因为有了读写锁,才使得多个线程之间的读操作不会发生冲突。
ReadWriteLock就是读写锁,它是一个接口,ReentrantReadWriteLock实现了这个接口。
可以通过readLock()获取读锁,通过writeLock()获取写锁。
CLH队列锁
CLH锁即Craig, Landin, and Hagersten (CLH) locks,CLH锁是一个自旋锁,能确保无饥饿性,提供先来先服务的公平性。
CLH锁也是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
Memory Access)非一致存储访问,将CPU分为CPU模块,每个CPU模块由多个CPU组成,并且具有独立的本地内存、I/O槽口等,模块之间可以通过互联模块相互访问,访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致存储访问NUMA的由来。NUMA优点是可以较好地解决原来SMP系统的扩展问题,缺点是由于访问远地内存的延时远远超过本地内存,因此当CPU数量增加时,系统性能无法线性增加。
CLH算法实现

locked域为false,此时线程A获取到了锁。

public class CLHLock implements Lock { AtomicReference<QNode> tail = new AtomicReference<QNode>(new QNode()); ThreadLocal<QNode> myPred; ThreadLocal<QNode> myNode; public CLHLock() { tail = new AtomicReference<QNode>(new QNode()); myNode = new ThreadLocal<QNode>() { protected QNode initialValue() { return new QNode(); } }; myPred = new ThreadLocal<QNode>() { protected QNode initialValue() { return null; } }; } @Override public void lock() { QNode qnode = myNode.get(); qnode.locked = true; QNode pred = tail.getAndSet(qnode); myPred.set(pred); while (pred.locked) { } } @Override public void unlock() { QNode qnode = myNode.get(); qnode.locked = false; myNode.set(myPred.get()); } }
从代码中可以看出lock方法中有一个while循环,这 是在等待前趋结点的locked域变为false,这是一个自旋等待的过程。unlock方法很简单,只需要将自己的locked域设置为false即可。
CLH优缺点
自旋锁(Spin lock)
自旋锁是指当一个线程尝试获取某个锁时,如果该锁已被其他线程占用,就一直循环检测锁是否被释放,而不是进入线程挂起或睡眠状态。
自旋锁适用于锁保护的临界区很小的情况,临界区很小的话,锁占用的时间就很短。
简单的实现
package com.dxz.sync3; import java.util.concurrent.atomic.AtomicReference; public class SpinLock { private AtomicReference<Thread> owner = new AtomicReference<Thread>(); public void lock() { Thread currentThread = Thread.currentThread(); // 如果锁未被占用,则设置当前线程为锁的拥有者 while (owner.compareAndSet(null, currentThread)) { } } public void unlock() { Thread currentThread = Thread.currentThread(); // 只有锁的拥有者才能释放锁 owner.compareAndSet(currentThread, null); } }
SimpleSpinLock里有一个owner属性持有锁当前拥有者的线程的引用,如果该引用为null,则表示锁未被占用,不为null则被占用。

这里用AtomicReference是为了使用它的原子性的compareAndSet方法(CAS操作),解决了多线程并发操作导致数据不一致的问题,确保其他线程可以看到锁的真实状态。
缺点
- CAS操作需要硬件的配合;
- 保证各个CPU的缓存(L1、L2、L3、跨CPU Socket、主存)的数据一致性,通讯开销很大,在多处理器系统上更严重;
- 没法保证公平性,不保证等待进程/线程按照FIFO顺序获得锁。
Ticket Lock
Ticket Lock 是为了解决上面的公平性问题,类似于现实中银行柜台的排队叫号:锁拥有一个服务号,表示正在服务的线程,还有一个排队号;每个线程尝试获取锁之前先拿一个排队号,然后不断轮询锁的当前服务号是否是自己的排队号,如果是,则表示自己拥有了锁,不是则继续轮询。
当线程释放锁时,将服务号加1,这样下一个线程看到这个变化,就退出自旋。
简单的实现
缺点
Ticket Lock 虽然解决了公平性的问题,但是多处理器系统上,每个进程/线程占用的处理器都在读写同一个变量serviceNum ,每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
下面介绍的CLH锁和MCS锁都是为了解决这个问题的。
MCS 来自于其发明人名字的首字母: John Mellor-Crummey和Michael Scott。
CLH的发明人是:Craig,Landin and Hagersten。
CLH锁
CLH锁也是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
package com.dxz.sync3; import java.util.concurrent.atomic.AtomicInteger; public class TicketLock { private AtomicInteger serviceNum = new AtomicInteger(); // 服务号 private AtomicInteger ticketNum = new AtomicInteger(); // 排队号 public int lock() { // 首先原子性地获得一个排队号 int myTicketNum = ticketNum.getAndIncrement(); // 只要当前服务号不是自己的就不断轮询 while (serviceNum.get() != myTicketNum) { } return myTicketNum; } public void unlock(int myTicket) { // 只有当前线程拥有者才能释放锁 int next = myTicket + 1; serviceNum.compareAndSet(myTicket, next); } }
MCS锁
MCS Spinlock 是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,直接前驱负责通知其结束自旋,从而极大地减少了不必要的处理器缓存同步的次数,降低了总线和内存的开销。
package com.dxz.sync3; import java.util.concurrent.atomic.AtomicReferenceFieldUpdater; public class MCSLock { public static class MCSNode { MCSNode next; boolean isLocked = true; // 默认是在等待锁 } volatile MCSNode queue;// 指向最后一个申请锁的MCSNode private static final AtomicReferenceFieldUpdater<MCSLock, MCSNode> UPDATER = AtomicReferenceFieldUpdater .newUpdater(MCSLock.class, MCSNode.class, "queue"); public void lock(MCSNode currentThreadMcsNode) { MCSNode predecessor = UPDATER.getAndSet(this, currentThreadMcsNode);// step // 1 if (predecessor != null) { predecessor.next = currentThreadMcsNode;// step 2 while (currentThreadMcsNode.isLocked) {// step 3 } } } public void unlock(MCSNode currentThreadMcsNode) { if (UPDATER.get(this) == currentThreadMcsNode) {// 锁拥有者进行释放锁才有意义 if (currentThreadMcsNode.next == null) {// 检查是否有人排在自己后面 if (UPDATER.compareAndSet(this, currentThreadMcsNode, null)) {// step // 4 // compareAndSet返回true表示确实没有人排在自己后面 return; } else { // 突然有人排在自己后面了,可能还不知道是谁,下面是等待后续者 // 这里之所以要忙等是因为:step 1执行完后,step 2可能还没执行完 while (currentThreadMcsNode.next == null) { // step 5 } } } currentThreadMcsNode.next.isLocked = false; currentThreadMcsNode.next = null;// for GC } } }
下图是CLH锁和MCS锁队列图示: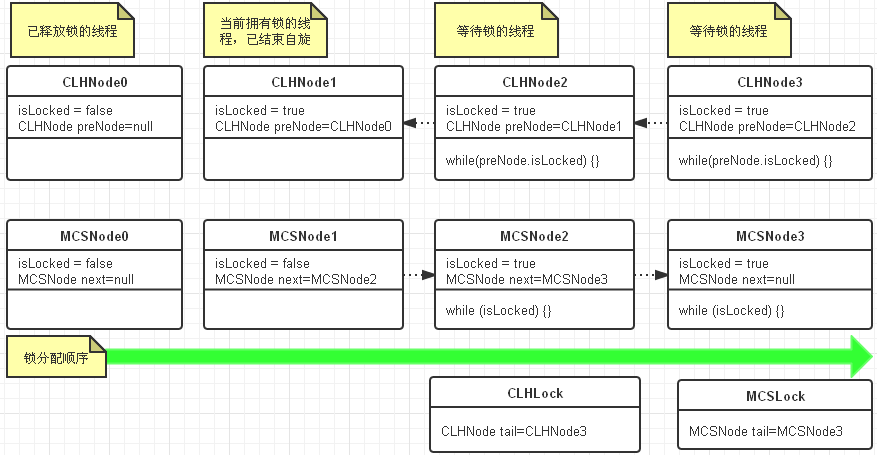
差异:
- 从代码实现来看,CLH比MCS要简单得多。
- 从自旋的条件来看,CLH是在前驱节点的属性上自旋,而MCS是在本地属性变量上自旋
- 从链表队列来看,CLH的队列是隐式的,CLHNode并不实际持有下一个节点;MCS的队列是物理存在的。
- CLH锁释放时只需要改变自己的属性,MCS锁释放则需要改变后继节点的属性。
注意:这里实现的锁(自旋锁、排队自旋锁、MCS锁、CLH锁)都是独占的,且不能重入的。