15.scrapy中selenium的应用
引入
- 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
今日详情
1.案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链进入国内对应的页面时,会发现当前页面展示的新闻数据是被动态加载出来的,如果直接通过程序对url进行请求,是获取不到动态加载出的新闻数据的。则就需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的新闻数据。
2.selenium在scrapy中使用的原理分析:
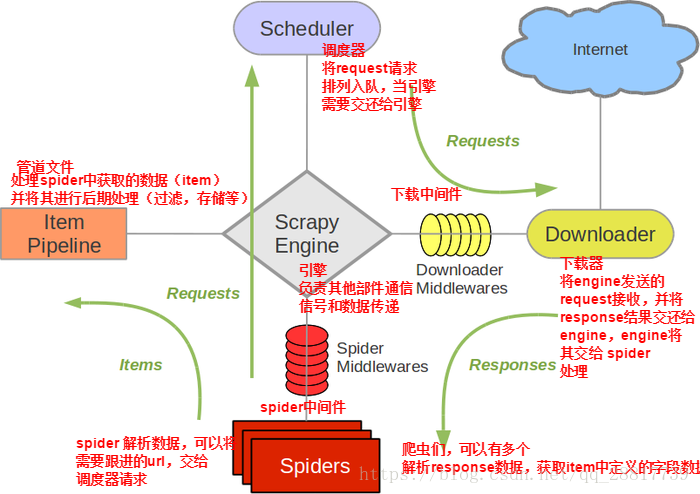
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3.selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
4.代码展示:
- 爬虫文件:
class WangyiSpider(RedisSpider):
name = 'wangyi'
#allowed_domains = ['www.xxxx.com']
start_urls = ['https://news.163.com']
def __init__(self):
#实例化一个浏览器对象(实例化一次)
self.bro = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver')
#必须在整个爬虫结束后,关闭浏览器
def closed(self,spider):
print('爬虫结束')
self.bro.quit()
- 中间件文件:
from scrapy.http import HtmlResponse
#参数介绍:
#拦截到响应对象(下载器传递给Spider的响应对象)
#request:响应对象对应的请求对象
#response:拦截到的响应对象
#spider:爬虫文件中对应的爬虫类的实例
def process_response(self, request, response, spider):
#响应对象中存储页面数据的篡改
if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']:
spider.bro.get(url=request.url)
js = 'window.scrollTo(0,document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间
#页面数据就是包含了动态加载出来的新闻数据对应的页面数据
page_text = spider.bro.page_source
#篡改响应对象
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
else:
return response- 配置文件:
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}任务并发执行是一个宏观概念,微观上是串行的。
Swing与AWT在事件模型处理上是一致的。
我们在学习JDBC的时候会过度到J2EE。
AWT是Java最早出现的图形界面,但很快就被Swing所取代。
在生成一个窗体的时候,点击窗体的右上角关闭按钮激发窗体事件的方法:窗体Frame为事件源,WindowsListener接口调用Windowsclosing()。
在java.util中有EventListener接口:所有事件监听者都要实现这个接口。
事件模型指的是对象之间进行通信的设计模式。
经验之谈:Swing的开发工作会非常的累,而且这项技术正在走向没落。避免从事有这种特征的工作。
重点掌握集合的四种操作:增加、删除、遍历、排序。
- 最新文章
-
rqnoj-329-刘翔!加油!-二维背包
解决小米手机无法收到开机广播的问题
手动建库时一个错误:Error accessing PRODUCT_USER_PROFILE
云原生应用程序
Spring Cloud
使用位图算法来优化签到历史存储空间占用
PHP实现图片(文件)上传
数据管理工具Flux、Redux、Vuex的区别
spring容器干掉if-else
Spring Boot从入门到实战:集成AOPLog来记录接口访问日志
- 热门文章
-
Libra 加密稳定币:Facebook的"野心"?
DatagramSocket(邮递员):对应数据报的Socket概念,不需要创建两个socket,不可使用输入输出流。
网络与分布式集群系统的区别:每个节点都是一台计算机,而不是各种计算机内部的功能设备。
class ObjectOutputStream也是过滤流,使节点流直接获得输出对象。
字节输入流:io包中的InputStream为所有字节输入流的父类。
ListFiles():返回Files类型数组,可以用getName()来访问到文件名。
Module 10:I/O流(java如何实现与外界数据的交流)
释放锁标记只有在Synchronized代码结束或者调用wait()。
线程因为未拿到锁标记而发生的阻塞不同于前面五个基本状态中的阻塞,称为锁池。
多线程的并发一般不是程序员决定,而是由容器决定。