背景
最近很多大四学生问我毕业设计如何选题
“你觉得图书管理系统怎么样?”
“导师不让做这个,说太简单”
“那你觉得二手交易平台怎么样?”
“导师说没新意,都有咸鱼了你做这个有什么意思?要新颖的”
“那你觉得个人博客平台的搭建怎么样?”
“啥是博客?”
“emmmm……在线售票怎么样?”
“导师说今年不让选xx管理系统,这些都太简单”

“那你觉得做人脸识别或者垃圾自动分类怎么样”
“导师说这些太难了,我肯定做不出来”

于是,我一气之下,爬取了学校的毕设题目,也顺便学学爬虫。
效果
爬取学校教学平台上所有的毕设题目,保存到本地数据库中

思路
获取要爬取页面的url,爬取数据,发现返回的是HTML,利用jsoup做HTML的解析,从中找出需要的部分,保存进数据库。
jsoup是用来解析HTML的,具体使用可以参考官网文档:https://jsoup.org/
代码准备
-
依赖(jar包)
解析HTML需要用到jsoup,数据库操作用dbutils,数据库连接池c3p0,数据库驱动
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.5.5</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
</dependency>
-
建表
想要保存序号,题目,学院,导师四个信息

-
代码
- 实体类 Project

- 数据库操作类 DataUtil

- 爬取主类
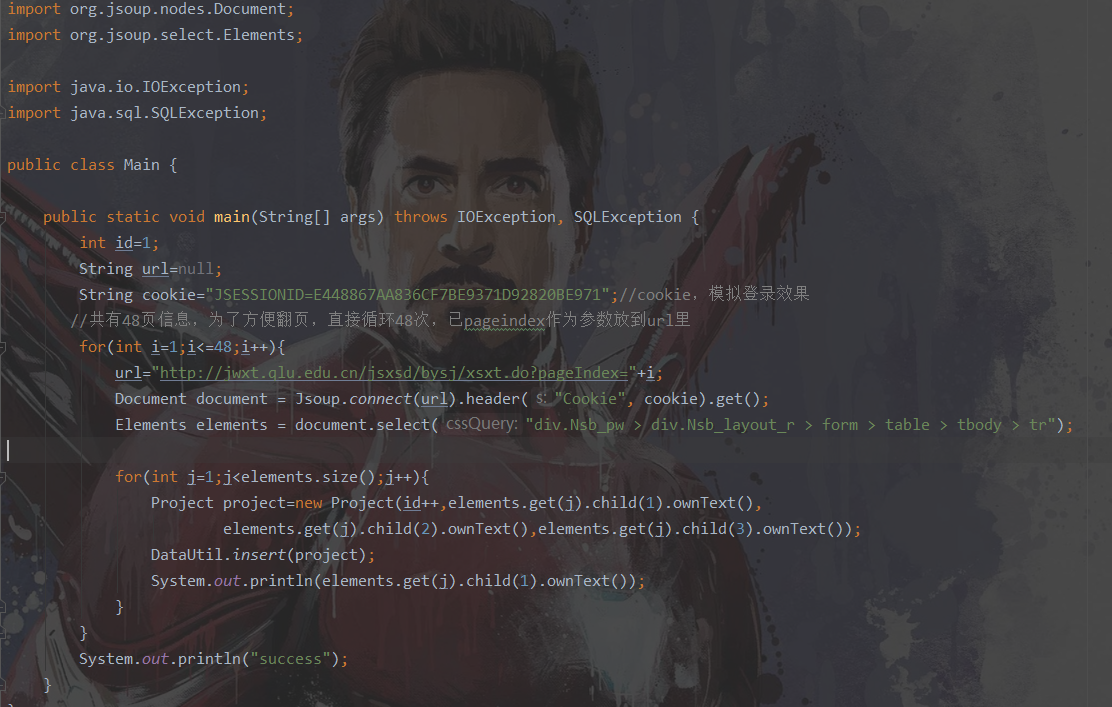
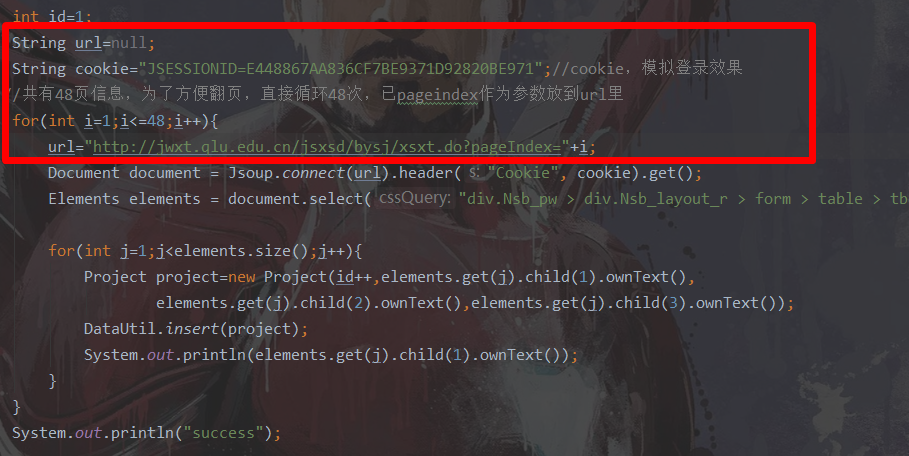
java爬虫过程解析
进入学校的教务系统,找到了所有毕设题目

按下f12,查看网络信息

从上图可以得到我们要访问的url,同时我们要拿到cookie信息,因为只有登录后才能进来这个url,所以我们先用浏览器登录上,然后复制当前cookie信息,通过代码访问url时附上该登录信息。
Document document = Jsoup.connect(url).header("Cookie", cookie).get();
上面代码中,url和cookie自行传入

通过调试模式查看得知,访问该url时,返回的不是json数据而是直接返回了HTML,因此我们需要去解析该页面,从中找出我们想要的数据部分
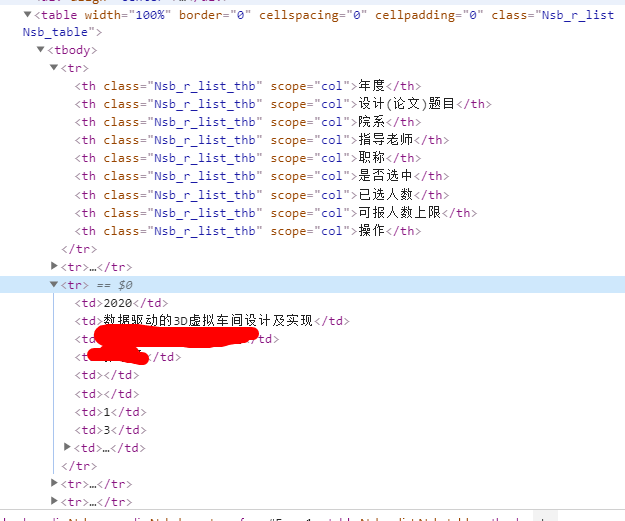
首先,先定位表格所在的位置,找到他的嵌套关系,直接看源码的嵌套关系如下图红色,也可以直接从浏览器的下方看到我点中的tr标签的嵌套顺序如下图蓝色

接着通过select方法,我们可以根据css选择器和标签类型一步步定位到我们要的部分
Elements elements = document.select("div.Nsb_pw > div.Nsb_layout_r > form > table > tbody > tr");
最后遍历elements,拿到其中的元素赋值给project对象,然后进行保存。这里我是定位到了标签,也就是说elements返回的是所有的tr标签元素。因此,拿到的elements其实相当于一个集合,里面的每一个元素,是一个tr标签及其内部全部内容。
elements.child(int index)方法,是得到其子元素,也就是说td标签
接着调用ownText()方法得到该元素的文本内容。
for(int j=1;j<elements.size();j++){
Project project=new Project(id++,elements.get(j).child(1).ownText(),elements.get(j).child(2).ownText(),elements.get(j).child(3).ownText());
DataUtil.insert(project);
System.out.println(elements.get(j).child(1).ownText());
}
下面是表格的源码,看完源码就可以理解我为什么要这么写了。第一个tr表示表格标题,所以跳过;我们只想得到题目,学院,导师的信息,因此调用child方法时传参分别为1,2,3
如何解决分页问题
系统用了分页,每次访问时默认都返回的是第一页的十条数据,通过查看源码我发现,下一页按钮对应的是一个js方法,于是我百度找了好久,想通过代码去执行“下一页”功能的那个js方法。
就在此时,我发现了页面保存的参数

哦?既然有当前页码数,那是否意味着我在url后面加上这个参数就可以访问到任意页面的数据,于是我试了一下用以下url:http://jwxt.qlu.edu.cn/jsxsd/bysj/xsxt.do?pageIndex=15
我擦,真的访问到了第十五页。那还百度个屁啊。于是就有了这段代码,循环搞定url