我深知作为一个IT行业职场菜鸟的不易,此处省略3千字。最近有些时间,想通过捕获大量的资源作为了解和学习入门。我知道大量的理论不能助于我成为开发经验,但是没有理论就相当于没有入门没有思路没有主导方向。我是零基础,我喜欢码字,我喜欢有思想的ctrl+c 和 ctrl+v 。开始吧......好记性不如烂笔头,仅供学习增加印象使用。
转载 http://url.cn/5YQEVwR
说明:本篇文章主要讲解单台机器架构开始,然后会遇到那些瓶颈,哪些坑,如何解决等,是一个典型的LNMP架构的网站架构演变。
故事是这样的: 有一天我突发奇想创建了一个站点,基于 LNMP 架构,起初只有我自己访问,后来因为我点儿正,访问量越来越大,所以最终导致下面说的架构演变。
一、单台机器
单台机器是因为只是一个小网站,访问量一天也没有多少UV(100以内) 所以用一台1核1G内存的机器就够了,机器上安装的是CentOs 系统,然后搭建了nginx+php+fpm+mysql 环境。
二、两台机器
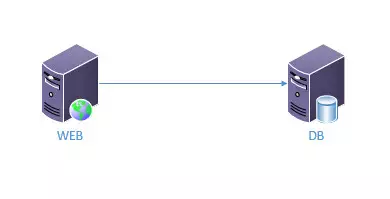
访问量越来越大,日UV突破5000, 单台机器不够,本可以增加机器 配置变成4核8G,但是考虑到还要换机器,所以直接添置一台数据库服务器单独跑 MySQL服务。
web服务器:主要跑 nginx+php-fpm
db服务器:主要跑mysql
文件服务器: 主要存放静态资源(这里没有用到)
三、增加memcached

访问量持续增加,UV上万了,DB 服务器和 WEB 服务器压力越来越大,这时候我们需要加一个缓存来缓解 DB 服务器的压力。
同样是两台机器,只不过 Web机器配置需要升级了,原来的1核1G内存不够用了,不仅要加 CPU 还要加内存,因为在 Web 上我们需要运行 memcached 服务,同时 PHP 也需要安装memcache 扩展。
memcache适用场景 参考出处 https://www.cnblogs.com/yaqiangyinsi/p/6116064.html
通常在电子商务系统中在网站的左侧会是商品的分类,中间是商品搜索结果的列表,可以查看商品信息和商家的基本信息和相关商家的信誉度信息。
一般的做法是:
多次从数据库中查询全站的商品分类--->>递归形成你所需的分类tree--->>进入处理数据------->>显示到页面上
memcached的做法:
1、第一次显示的时候:判断memcached缓存中是否有该分类如果不存在执行SQL查询,然后放进memcached中,然后显示到界面
2、第二次显示的时候:判断memcached缓存中是否有该分类如果存在直接读取memcached缓存,然后显示到界面
3、若遇到更新的数据,找到memcached中与之对应的key值删除它,重新插入memcached缓存中。
四、增加Web服务器,MySQL主从分布
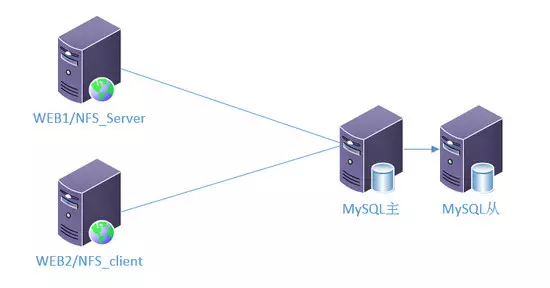
说明: 访问量又扩大了,UV到了5W,数据库服务器因为一开始配置就挺高,所以没有压力,但是 Web 服务器负载有点高了,在高峰期可以感觉到网站访问变慢。
所以,这时候不得不考虑要加一台 Web 服务器。
另外,数据库是单点,如果磁盘损坏,可能会带来意想不到的后果,所以我们有必要加一台从 DB 服务器,作为数据备份用。
在这里,两台 Web 服务器并没有做负载均衡。主要是为了节省资源,暂时先不去购买服务器做负载均衡。
1、我们使用 DNS 轮询的方法来把用户的请求分发到两台机器上,但这种该架构有个问题,一旦一台 Web 机器宕机,将会有一半的用户访问不到业务。
2、还有一个问题 我们也需要考虑到,如何保证 Web 服务器上的数据一致,比如用户可能会上传图片到 Web 服务器上,假如他上传到了 Web1 上,那 WEB2 是不存在这个图片的。
所以我们需要做一个共享存储让 Web1 和 Web2 同时可以访问,所以在这里我把 WEB1 的一个目录使用 NFS 共享出来,让 Web2 去挂载。
3、还有一个问题 就是memcached服务如何分配,在这里,我是把 memcaced 服务分别安装到两台 Web 上的,自己用自己的 memcached 服务。
分析以上操作
(1) DNS 轮询 参考出处 https://yq.aliyun.com/articles/43118 资源
说明:大多域名注册商都支持多条A记录的解析,其实这就是DNS轮询,DNS服务器将解析请求按照A记录的顺序,逐一分配到不同的IP上,这样就完成了简单的负载均衡。
优点
1、无成本,因为往往域名注册商的这种解析都是免费的;
2、 部署方便 除了网络拓扑的简单扩增,新增的Web服务器只要增加一个公网IP即可。
缺点
1、健康检查,如果某台服务器宕机,DNS服务器是无法知晓的,仍旧会将访问分配到此服务器。修改DNS记录全部生效起码要3-4小时,甚至更久;
2、分配不均,如果几台Web服务器之间的配置不同,能够承受的压力也就不同,但是DNS解析分配的访问却是均匀分配的。
其实DNS也是有分配算法的,可以根据当前连接较少的分配、可以设置Rate权重分配等等,只是目前绝大多数的DNS服务器都不支持;
3、会话保持,如果是需要身份验证的网站,在不修改软件构架的情况下,这点是比较致命的,因为DNS解析无法将验证用户的访问持久分配到同一服务器。
虽然有一定的本地DNS缓存,但是很难保证在用户访问期间,本地DNS不过期,而重新查询服务器并指向新的服务器,那么原服务器保存的用户信息是无法被带到新服务器的,
而且可能要求被重新认证身份,来回切换时间长了各台服务器都保存有用户不同的信息,对服务器资源也是一种浪费。
(2)NFS 共享
NFS原理详解可参考 http://blog.51cto.com/atong/1343950
NFS(Network File System)即网络文件系统,是FreeBSD支持的文件系统中的一种,它允许网络中的计算机之间通过TCP/IP网络共享资源。
在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。
好处
1、节省本地存储空间,将常用的数据存放在一台NFS服务器上且可以通过网络访问,那么本地终端将可以减少自身存储空间的使用。
2、 用户不需要在网络中的每个机器上都建有Home目录,Home目录可以放在NFS服务器上且可以在网络上被访问使用。
3、 一些存储设备如软驱、CDROM和Zip(一种高储存密度的磁盘驱动器与磁盘)等都可以在网络上被别的机器使用。这可以减少整个网络上可移动介质设备的数量。
思路:也可以单独搞一台服务器存放文件资源
(3) memcache 问题
memcache 和 mysql的 同步问题? 参考 https://www.cnblogs.com/phpstudy2015-6/p/6683170.html
1、mysql的触发器
2、mysql memcached UDF(User Defined Functions 用户自定义函数)
mysql memcached UDF 其实就是通过libmemcached来使用memcache的一系列函数,
通过这些函数,你能 对memcache进行get, set, cas, append, prepend, delete, increment, decrement objects操作,
如果我们通过mysql trigger来使用这些函数,那么就能通过mysql更好的,更自动的管理memcache!
多台服务器memcache的同步问题?
思路:增加一个中间的webservice来提供多线程并行操作,统一处理license memcache的增减
可参考:http://blog.csdn.net/cd18333612683/article/details/52269012
https://www.tuicool.com/articles/rIraimb
http://zhengdl126.iteye.com/blog/420539
memcache 共享session的问题?
可参考: http://blog.csdn.net/iktz_cn/article/details/50074513
http://blog.csdn.net/xluren/article/details/16951247
五、MySQL读写分离
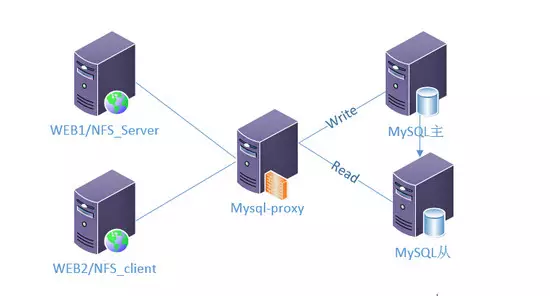
说明:访问量持续上升,UV已到了数十万。网站在高峰期总是会卡顿那么一段时间。
经排查,发现在 MySQL 服务器上有很多慢查询,经过各种调优依然没有太明显效果,最后决定做读写分离。
方案:1、可以借助程序来实现,把所有的写操作指向到主 MySQL ,所有的读操作指向到从 MySQL(对于这种方案,机器数量和环境不用做任何调整,唯一要做的是程序代码要改一下)
2、可以借助 mysql-proxy 来实现,不用修改代码,节省开发成本,但需要增加一个角色。
mysql读写分离
mysql-proxy
可参考: http://blog.jobbole.com/94595/ http://blog.jobbole.com/94606/
https://www.cnblogs.com/tae44/p/4701226.html (实战)
http://heylinux.com/archives/1004.html (MySQL主从复制(Master-Slave)与读写分离(MySQL-Proxy)实践)
MySQL Proxy有一项强大功能是实现“读写分离”,基本原理是让主数据库处理写方面事务,让从库处理SELECT查询
Amoeba for MySQL是一款优秀的中间件软件,同样可以实现读写分离,负载均衡等功能,并且稳定性也高于MySQL Proxy
六、负载均衡

背景:两台 Web 服务器因为有一台配置比较老,因此在高峰期时,终究是没有能扛住而挂掉。结果影响了一半的用户访问不到网站了,这就是所谓的单点故障。
经过此次事故,我又开始修改架构,尽量避免单点故障,在 Web 前端设置了负载均衡设备,并且做了高可用。
原文:在这里我拿 Nginx 做了负载均衡器,并没有使用 LVS和HAProxy,我觉得 Nginx 更容易操作,更好控制。
为了节省成本,我并没有单独把 mysql-proxy 摘出来作为独立服务器,因为那样的话,也得为它考虑单点问题。
在这个架构中,其实还有一个缺陷,就是 NFS 服务端也是有风险的,更加保险的做法是单独搞一台服务器做NFS服务。
七、继续扩展
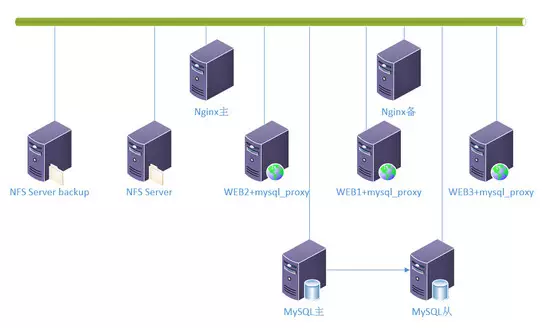
原文:UV上升到100万,两台 Web 服务器明显不够用了,而瓶颈并不在 MySQL 上。所以,只增加 Web,同时把 NFS 服务器单独摘出来,并做一个备用 NFS 服务器。
八、引入NoSQL
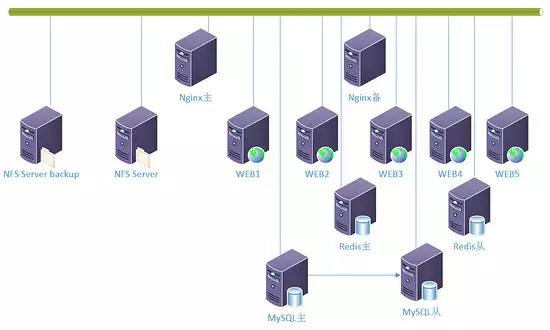
原文:UV近1000万,三台 Web 服务器也早已不够,增加到5台。而 MySQL 服务器压力逐渐变大,针对 MySQL 的慢查询,发现压力主要体现在个别 SQL 语句上,
该优化的已经优化到极致,对于这几个查询,其实是可以使用 NoSQL 的。 于是,把一些访问量大的数据存储到Redis,从而减少了对 MySQL 服务器的压力。
而 Redis 为了防止单点也做了主从。
可参考:http://blog.csdn.net/u011204847/article/details/51307044
九、总结
第一阶段
网站访问量日PV量级在1W以下。单台机器跑Web和DB,不需要做架构层调优(比如,不需要增加memcached缓存)。
此时,数据往往都是每日冷备份的,但有时候如果考虑数据安全性,会搭建一个MySQL主从。
第二阶段
网站访问量日PV达到几万。此时单台机器已经有点负载,需要我们把Web和DB分开,需要搭建memcached服务作为缓存。
也就是说,在这个阶段,我们还可以使用单台机器跑mysql去承担整个网站的数据存储和查询。如果做 MySQL 主从,目的也是为了数据安全性。
第三阶段
网站访问量日PV达到几十万。单台机器虽然也可以支撑,但是需要的机器配置要比之前的机器好很多。
如果经费允许,可以购买配置很高的机器来跑mysql服务,但是并不是说,配置翻倍,性能也翻倍,到了一定阶段配置增加已经不能带来性能的增加。
所以,此阶段,我们会想到做MySQL服务的集群,也就是说我们可以拿多台机器跑MySQL。
但是,MySQL集群和Web集群是不一样的,我们需要考虑数据的一致性,所以不能简单套用做Web集群的方式(lvs,nginx代理)。
可以做的架构是,MySQL主从,一主多从。为了保证架构的健壮和数据完整,主只能是一个,从可以是多个。
还有一个问题,我们需要想到,就是在前端Web层,我们的程序里面指定了MySQL机器的ip,那么当机器有多台时,程序里面如何去配置?Discuz其实有一个功能,支持MySQL读写分离。
即我们可以拿多台机器跑MySQL,其中一台写,其他多台是读,我们只需要把读和写的 IP 分别配置到程序中,程序自动会去区分机器。
当然,如果不使用 discuz 自带的配置,我们还可以引用一个软件叫做 mysql-proxy, 使用他来实现读写分离。它支持一主多从的模式。
第四阶段
网站访问量日PV到几百万。之前的一主多从模式已经遇到瓶颈,因为当网站访问量变大,读数据库的量也会越来越大,我们需要多加一些从进来,但是从的数量增加到数十台时,
由于主需要把bin-log全部分发到所有从上,那么这个过程本身就是一件很繁琐的事情,再加上频繁读取,势必会造成从上同步过来的数据有很大延迟。
所以,我们可以做一个优化,把MySQL原来的一主多从变为一主一从,然后从作为其他从的主,而前面的主只负责网站业务的写入,而后面的从不负责网站任何业务,只负责给其他从同步bin-log。
这样还可以继续多叠加几个从库。
第五阶段
网站访问量日PV到1千万的时候,我们发现,网站的写入量非常大,我们之前架构中只有一个主,这里的主已经成为瓶颈了。
所以,需要再近一步做出调整。比如,我们可以把业务分模块,把用户相关的单独分离出来,把权限、积分等也可以分离出来单独跑一个库,然后再做主从,也就是所谓的分库。
当然也可以换一个维度,把访问量或者写入量大的表单独分离出来,跑在一台服务器上,也可以把一个表分成多个小表。
这一步操作,涉及到一些程序上的改动,所以需要事先和开发同事做好沟通和设计。
总之,这一步要做的就是分库分表。
分库分表总结可参考:http://www.cnblogs.com/chy2055/p/5125245.html
十、小结
再往后发展,继续把大表分小表即可。 比如阿里淘宝网站的数据量是巨量的,他们的数据库全部都是 MySQL,
他们的 MySQL 架构就是遵循分库分表这个原则的,只不过他们划分规则会有很多维度,比如可以根据地域划分,可以根据买家、卖家划分,可以根据时间划分等。
附:本人尊重版权转至 http://url.cn/5YQEVwR