| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | <学习json的提取以及文件的读取写入,学会git,github使用以及对代码进行单元测试> |
| 学号 | <041801520> |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 120 |
| Estimate | 估计这个任务需要多少时间 | 120 | 180 |
| Development | 开发 | 30 | 60 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 30 |
| Design Spec | 生成设计文档 | 15 | 20 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| Design | 具体设计 | 15 | 15 |
| Coding | 具体编码 | 30 | 30 |
| Code Review | 代码复审 | 15 | 15 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | 15 | 15 |
| Test Report | 测试报告 | 15 | 15 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
解题思路及过程
在刚拿到这道题的时候是比较懵的,因为个人的基础比较差,所以看起来像天书。因为给的示例是python,所以我就开始了自学python之旅,花了四天左右每天高强度的在小破站学习之后大概掌握了python的语法,但是我发现我还是看不懂给的看起来稍微复杂的程序。
之后我便尝试从另一个角度开始解题,在群里看大佬天天在讨论什么解析json之后就开始去百度,然后顺利的提取了给的json数据,输出了几万行的字典,那时候我才感觉自己开始对题目有点理解了。
在解决最基础的前两个问题用比较复杂的代码解决后,我便遇到了困难,那就是命令行参数到底是啥,如何达到老师给的格式要求,这个困扰了我很久。花了一晚上的时间到处看博客,同学的代码,以及csdn上面查找资料,一开始感觉特别深奥难懂,一度想放弃。后来找到了一篇文章写得是getopt模块的使用,是相对比较简单的命令行参数的书写,包括短和长命令两种,解决了我的燃眉之急。
文章链接如下:
<https://blog.csdn.net/qq_34765864/article/details/81368754在大概写完代码之后,一直在cmd窗口里面按照给的格式运行,然后开始想的理所当然就是第一次初始化后面就不用打开文件,因此代码一直出错,无法得到正确结果,后来我尝试每次运行都打开运行,便得到正确答案,但是每次运行都要较久的时间。后来询问同学得知这个还有单线程多线程之分,开始继续自学了。
研究后发现python多线程并没有用,而我是因为数据丢失,导致的程序读取慢需要多次读取文件夹,后来我直接保存到一个新的json里面最后在主函数里面读取即可。
当我发现用getopt无法解决参数的顺序问题后我陷入沉思,后来重新在csdn找到了我能看懂的argparse模块的介绍。结合助教的代码,终于搞出了能用的命令行参数。
文章链接如下:
https://blog.csdn.net/yy_diego/article/details/82851661排除以上问题,总算写出一个能运行,且测试数据通过的代码。
代码解析流程图

主要代码展示及思路
对json文件夹解析并存入一个新的json文件中方便后续读取
def get_json(path_to_data):
file_list = os.listdir(path_to_data)
jsfile = open('js_data.json', 'w', encoding = 'utf-8')
for file in file_list:
new_file = path_to_data + '\' + file
data_file = open(new_file, 'r', encoding = 'utf-8')
for line in data_file:
data = json.loads(line)
jsfile.write(line)
jsfile.close()
return
对命令行参数的设置
parser = argparse.ArgumentParser()
parser.add_argument('-i', '--init', default = '')
parser.add_argument('-u', '--user', default = '')
parser.add_argument('-r', '--repo', default = '')
parser.add_argument('-e', '--event', default = '')
- 计算并输出最终数据的子程序
def get_result(jsdata_list, user, event, repo):
'''获取最终结果的函数'''
result = 0
i = 0
for jsdata in jsdata_list:
if len(user) != 0 and len(repo) == 0:
if user == jsdata['actor']['login'] and jsdata['type'] == event:
result += 1
else:
pass
elif len(user) == 0 and len(repo) != 0:
if repo == jsdata['repo']['name'] and jsdata['type'] == event:
result += 1
else:
pass
elif len(user) != 0 and len(repo) != 0:
if repo == jsdata['repo']['name'] and jsdata['type'] == event and user == jsdata['actor']['login']:
result += 1
else:
pass
print(result)
- 在本地输出示例
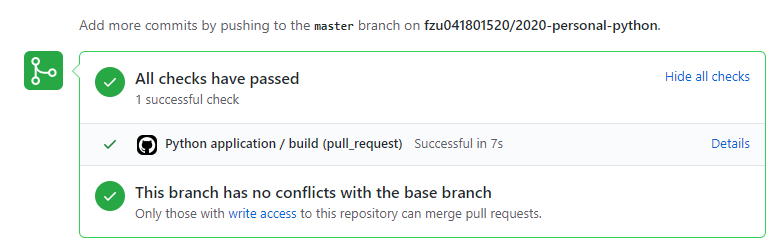
- Github运行测试
安装pytest
- 安装截图
- 检测版本

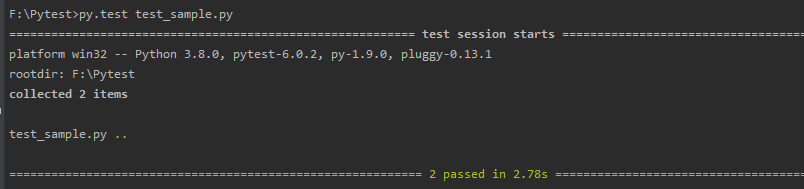
单元测试
- 用pytest对代码进行了单元测试,我进行了简单地数据检测,一个是检测json解析数据是否正确,一个是检测最后输出程序中判断是否争取,最终都通过了
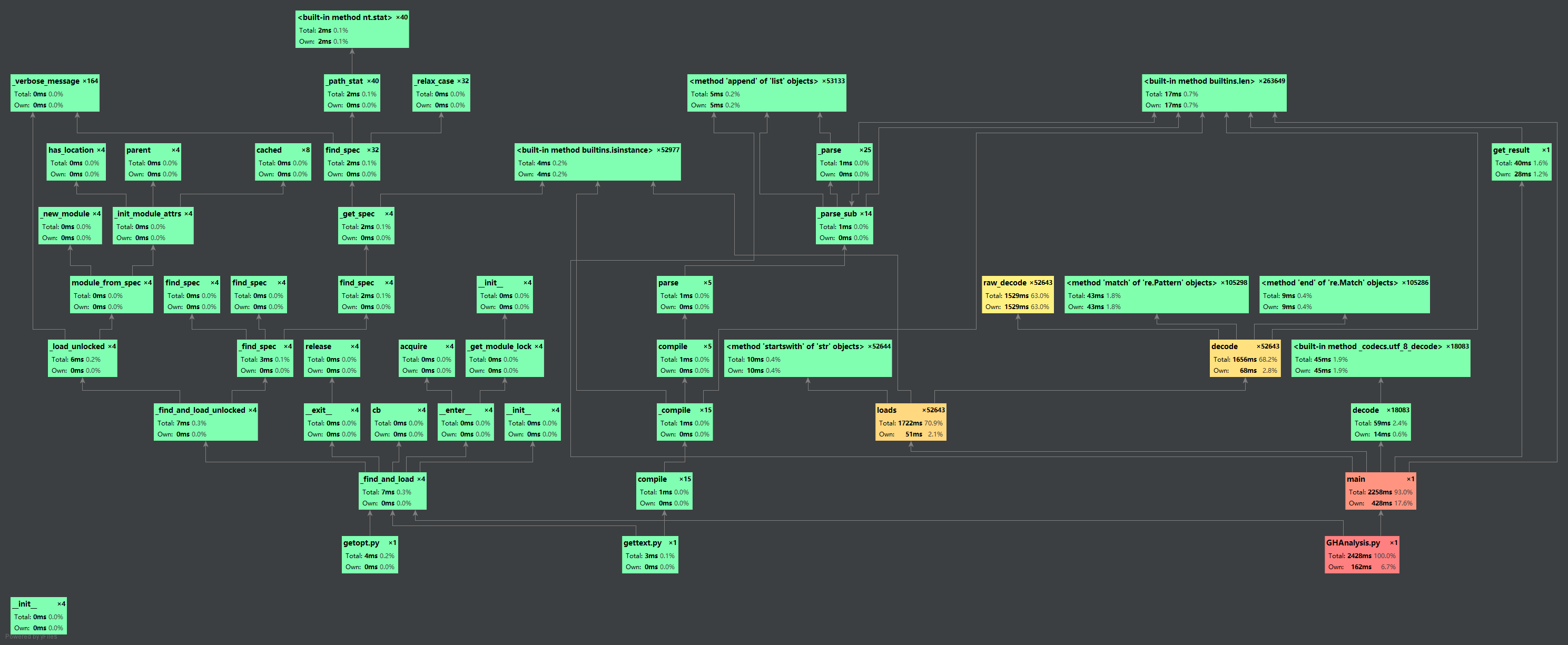
覆盖率及性能测试优化
- 对代码进行coverage测试,所有示例数据测试一遍然后进行整合,最后得出一个htmlcov文件夹,下面是测试截图
- 使用pychar自带的profile进行性能测试
总的来说运算时间还是过长,主要就是提取文件的时候没有进行关键数据提取的写入
- 形成的网状分析流程图

命令框测试输入截图如下

html覆盖率截图如下
代码规范
总结
- 这是一次艰难的完成编程作业的过程,对于自己来说不亚于开天辟地,从自学语言到学习Git使用到后面写代码并完善和debug都是一项浩大的工程。
- 总的来说学到了Github的一些使用,以及对python语言的掌握,对自己的提升还是比较大的。
- 最后是对代码进行单元测试,对我来说也是一项全新的任务,最后通过查找资料以及同学的帮助最后完成了单元测试的任务。
- 总算是磕磕绊绊完成了大部分的任务,虽然知道代码提升空间还很大,但是感觉暂时精力不够了,这次作业对于我这样基础不够好的人来说是一次不小的挑战,很庆幸自己完成了,学会了好多以前不曾接触过的东西,还是为自己感到欣慰。
代码优化想法
- 总的来说,代码的解析部分我想的过于简单,只是单纯提取文件夹中所有json数据合成一个新的json文件,因此在后续主函数的调用中是耗时较久的,如果在一开始解析的时候仅仅提取我要的数据部分那么应该能做到优化。
- 另一个是查找部分,在我第一点优化的基础上,形成一个字典的话,那么久用不着多次遍历,只需要在你形成的字典中查找便是,那样便是o(1)的时间复杂度。