通常我们在做CTR预估的时候,预估值会与真是的CTR有偏差,这种偏差可能来自于负采样,可能是因为模型的问题。
CTR预估值与真实值有偏差,并不会影响AUC指标和排序,但是实际使用中往往需要CTR的预估值不仅仅是做到有序,即正样本排在负样本前面,而且需要保证有一定的区分度。这涉及到一个概念保序和保距。
假设我们有这么一个序列 牛 500KG,羊100KG,兔子 5kg,我们有一个模型,输入这些动物之后,根据体重排序,并且出一个体重的预估值。
我们模型如果只是采用AUC这个指标的话,那么我们模型输出 牛 100kg 羊 20 kg, 兔子1kg,这样的结果AUC是没问题的,但是这只是做到了保序,但是他们之间的差值变小了,没有做到保距。
在实际业务中,比如我们有这么一些广告,A的实际点击率是10%,B的实际点击率是5%,C的实际点击率是1%,但是A B C的点击收益分别是2,5,10,如果我们的模型没有做到保距,那么输出的预估值是5%,1%,0.5%,这样的话AUC的排序指标是满足了,但是实际收益并不是最优的。
因此需要对CTR进行校准,是的CTR距离真实值越近越好。
对于CTR校准的方法,我了解的大概有这么两种,一种是基于负采样的采用比例来进行校准,参考的论文是14年facebook的论文《Practical Lessons from Predicting Clicks on Ads at Facebook》
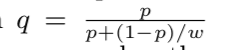
其中P是预估值,q是校准后的值,w是负样本的采样比例
推导的方式,就是假设p拟合的是采样后的训练集的点击率,q是未抽样前的数据集的点击率,然后根据对应关系可以推导。
如果是逻辑回归其实也可以推导出是对偏置项的一个修正。
另外一个是保序回归,保序回归
关于保序回归的具体做法可以参考这篇文章http://vividfree.github.io/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/2015/12/15/model-calibration-for-logistic-regression-in-rare-events-data
实验的结果: 两种CTR校准的方式对于AUC都没有影响,保序回归的话存在的问题是分桶数量的设置,要保证每个桶的真是CTR是可信的。对于负采样两种都能够比较好的将预估值校准到真实值。不过具体线上效果如何还没有测试。