
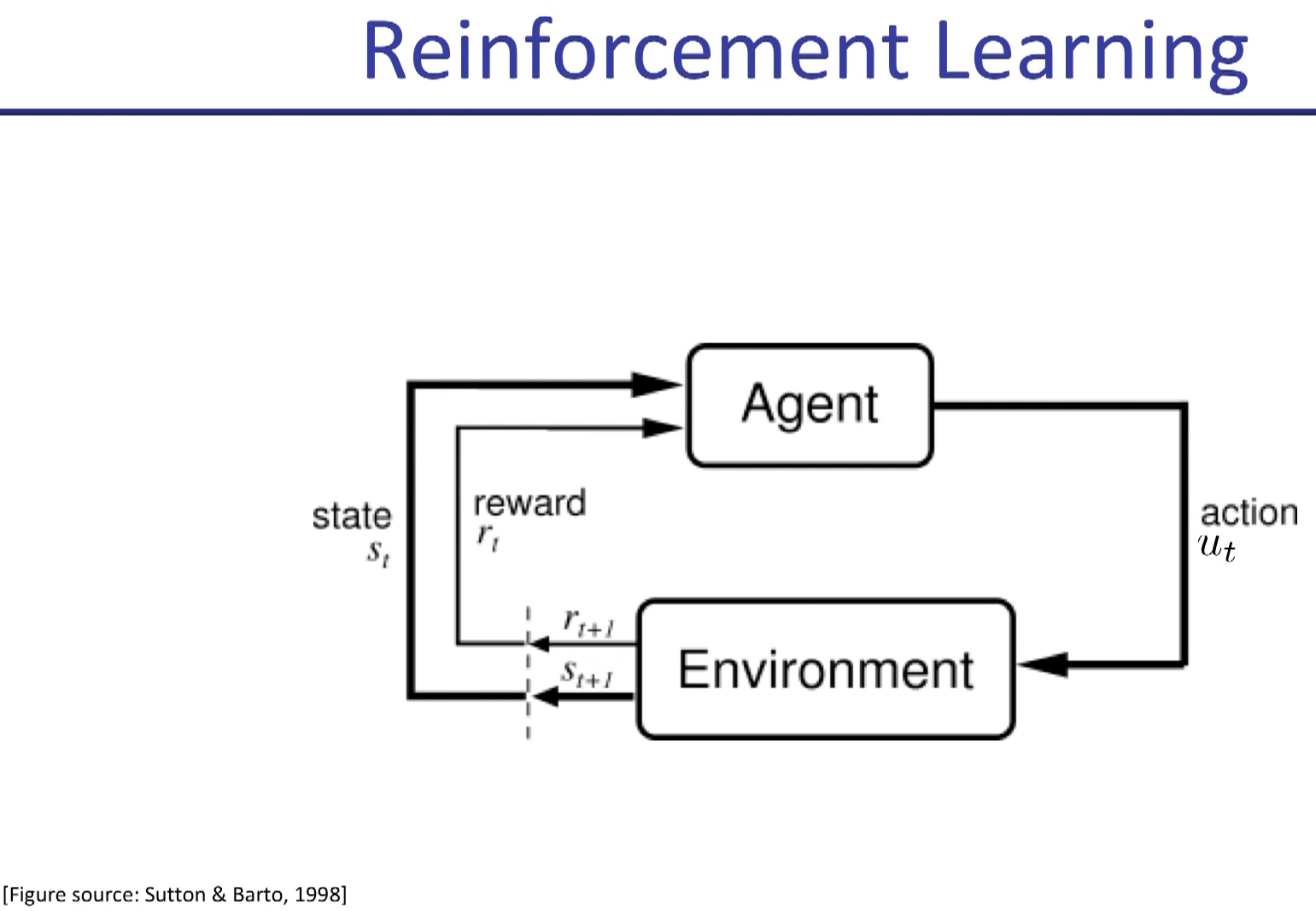
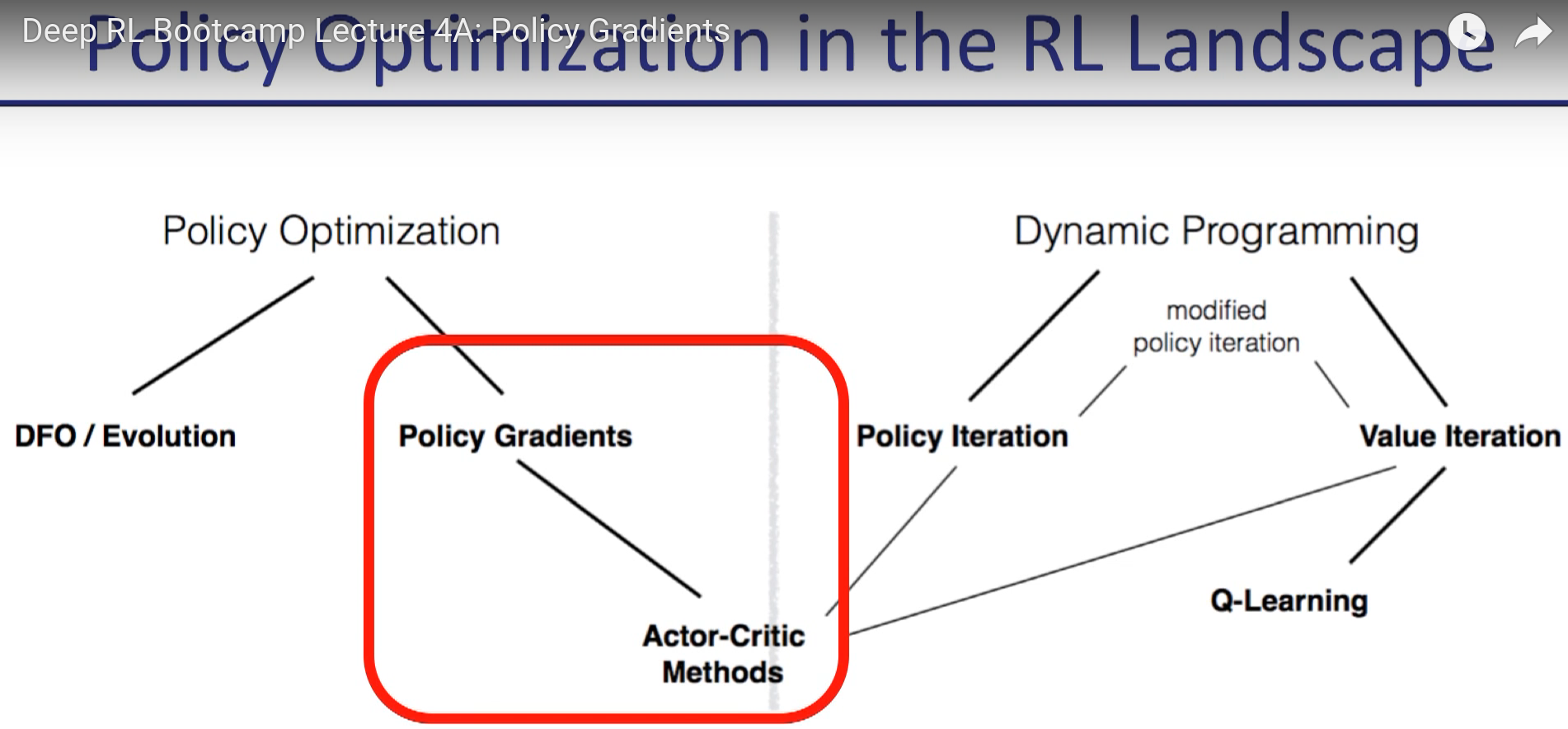
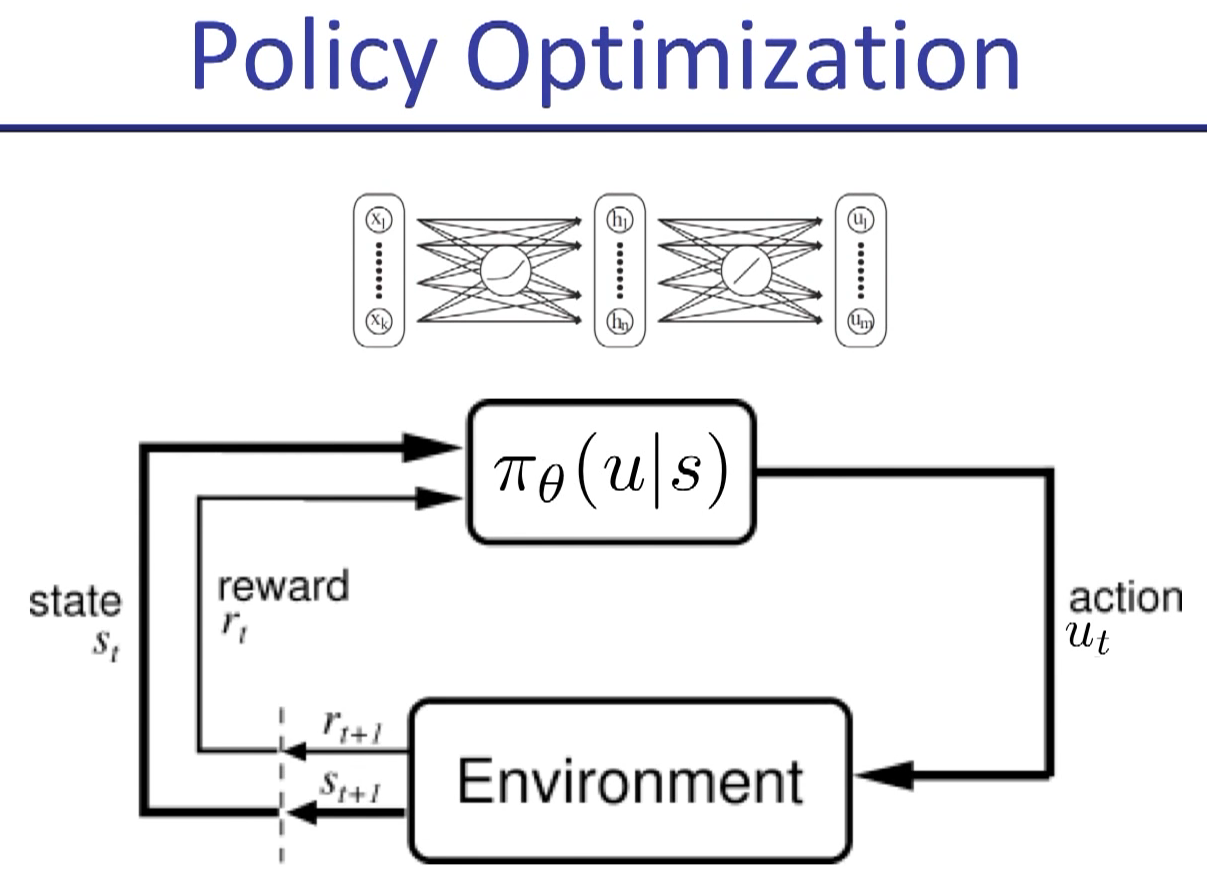
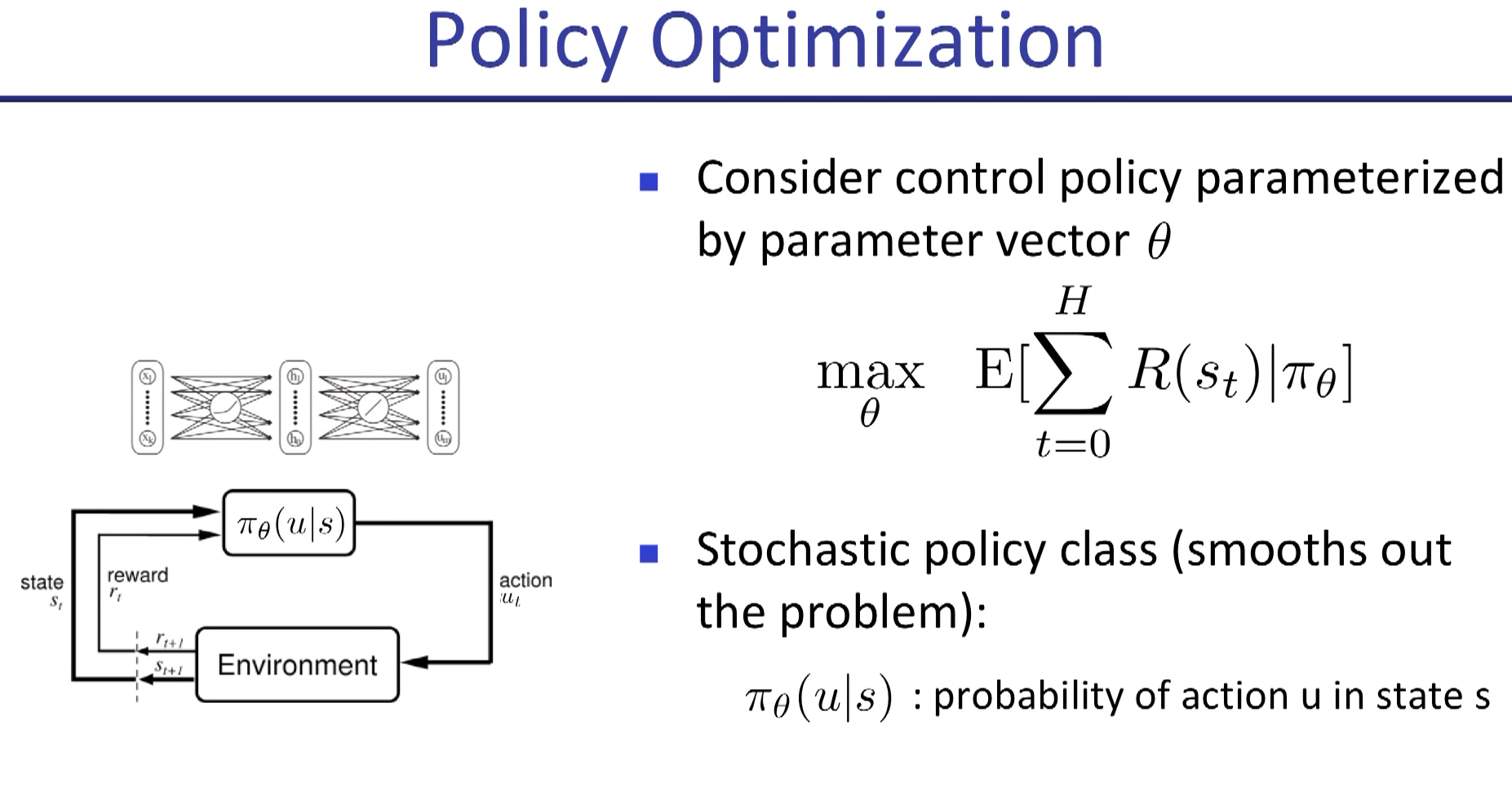

in policy gradient, "a" is replaced by "u" usually.
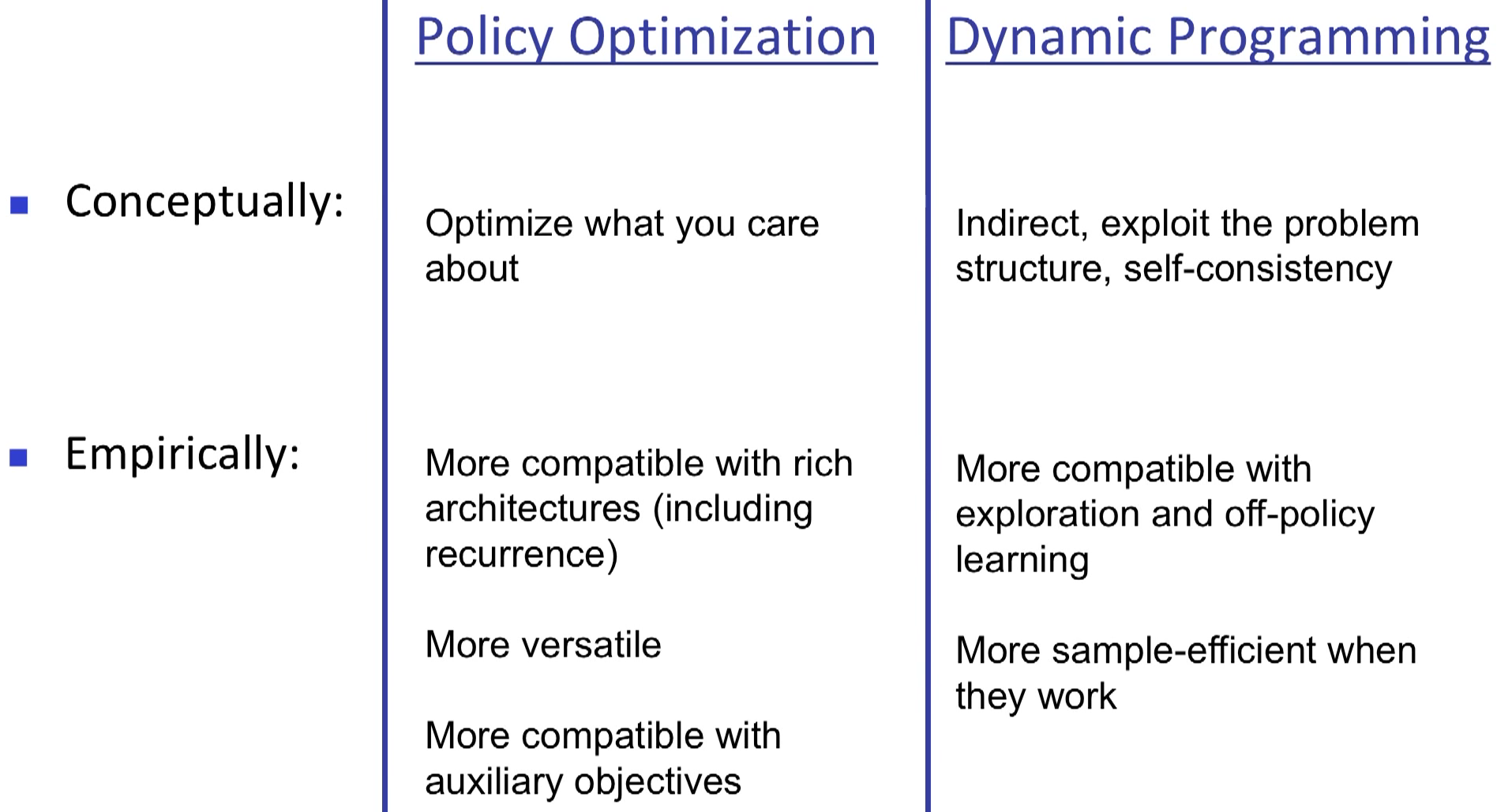









use this new form to estimate how good the update is.



If all three path show positive reward, should the policy increase the posibility of all the sampling?




monte carlo estimate

TD estimate






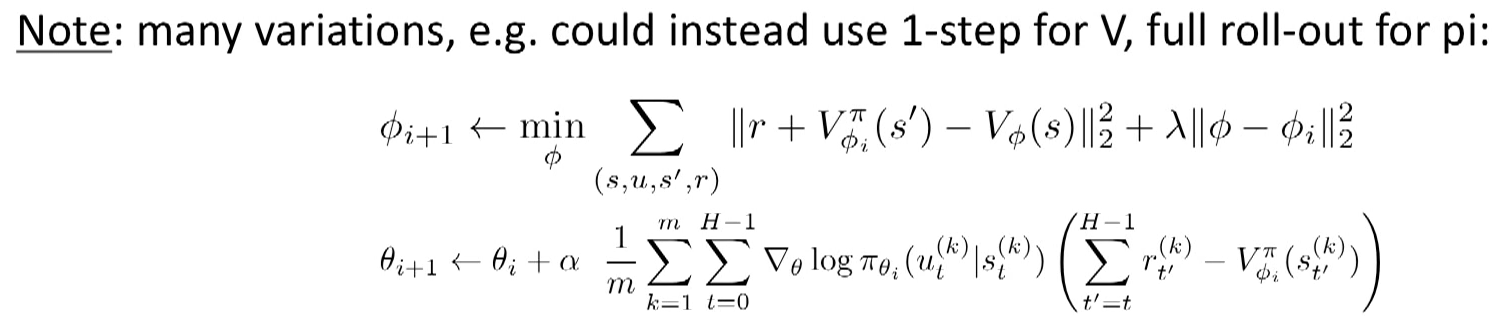
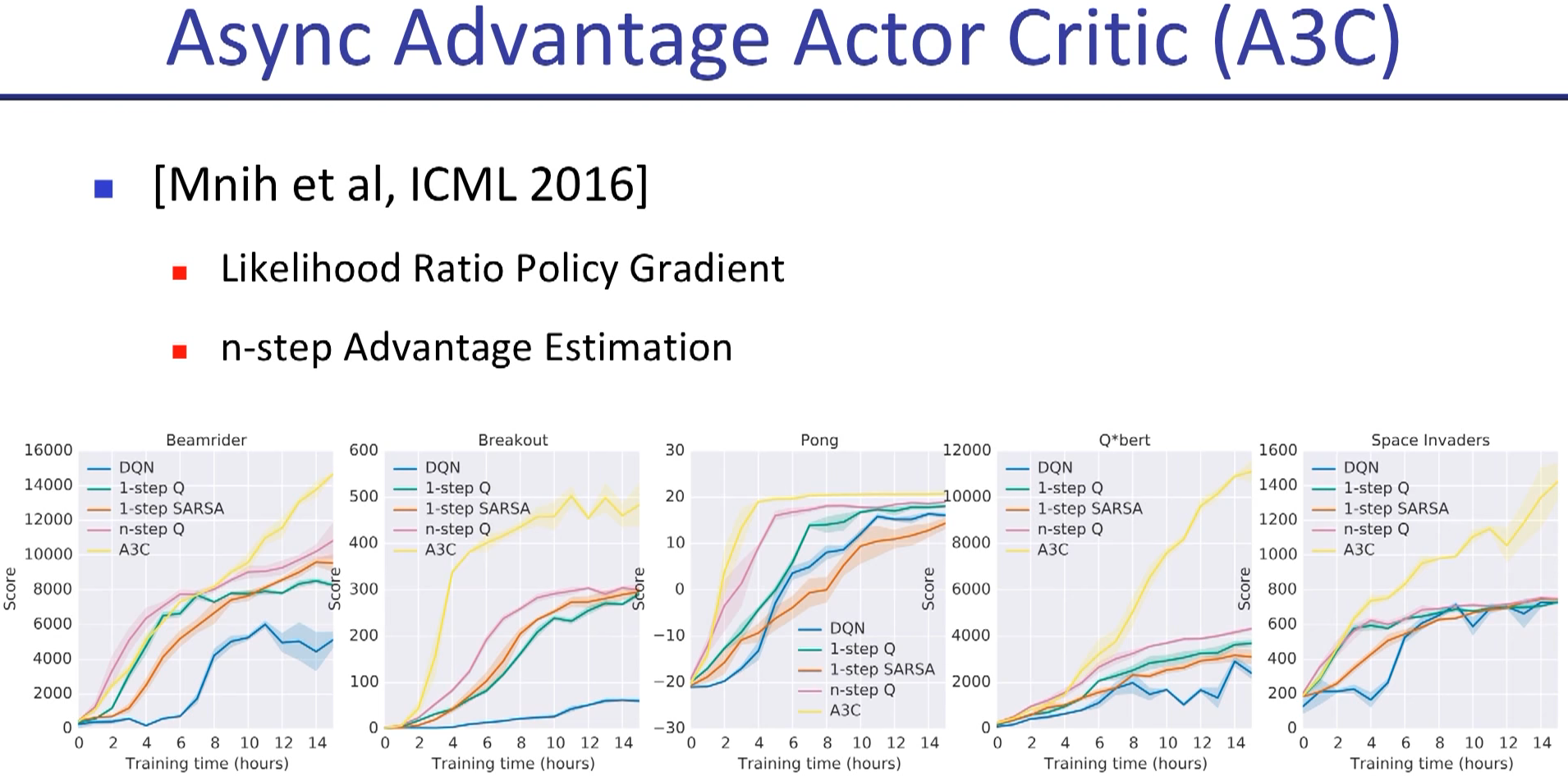
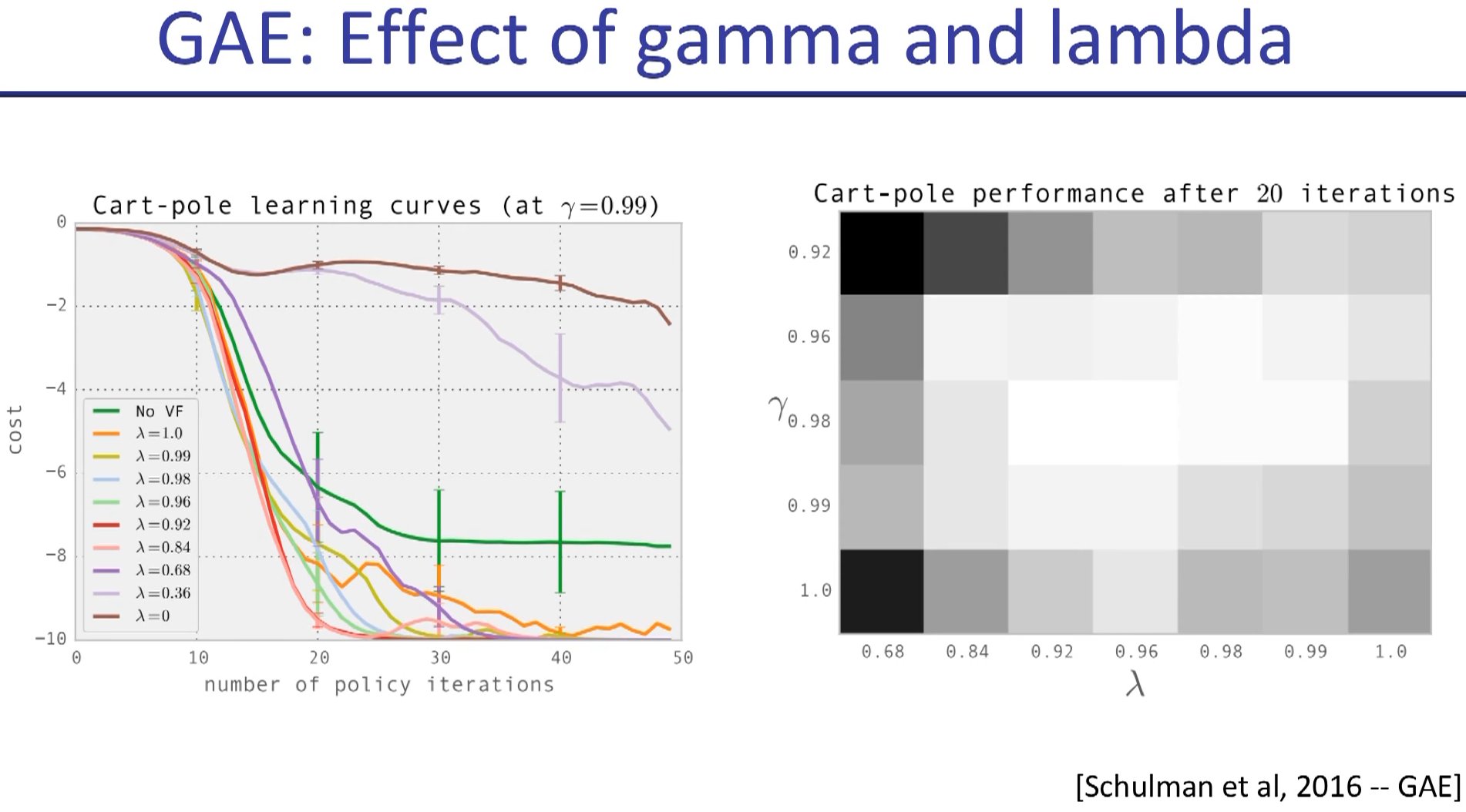

2 weeks to train as respect to real world time scale.
but could be faster in emulator (MOJOCO).
we don't know whether a set of hyperparameter is going to work until enough interations have past. So it's kind of tricky, and using emulator could alleviate this problem.
question: how to transform learnt knowledge of robot to real life if we are not sure about the match between simulator and real world?
Randomly initilize many simulator and see the robustness of the algorithm


this video shows that even a robot with two years of endeavor of a group of experts still isn't good at locomotion
hindsight experience replay
Marcin Richard from OpenAI
the program is set to find the best way to get pizza, but when the agent find a ice cream, the agent realizes that ice cream, corresponding to a higher reward, is the exact thing it wants to get.
https://zhuanlan.zhihu.com/p/29486661
https://zhuanlan.zhihu.com/p/31527085