无论是在大型项目,还是小型项目中,随着业务的迭代,用户的增长,数据库数据往往都是成百万级别的,这时候普通的sql语句执行起来是非常慢的,这时候就需要对sql进行优化啦,接下来将手把手从索引原理带你学会如何分析优化,写出一手高逼格的sql。
Mysql的索引存储原理:
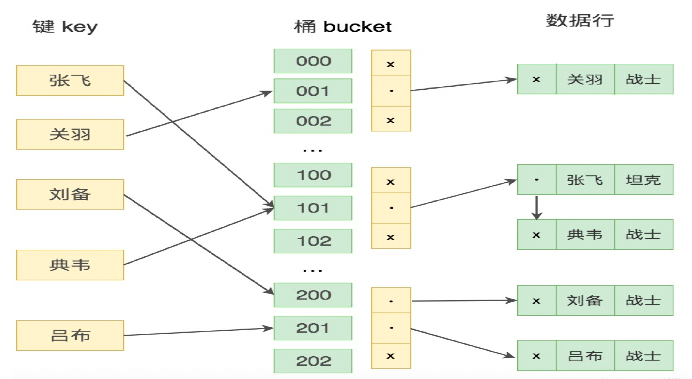
mysql有两种索引:**hash**和**b+tree**
select * from user where age = 10 (生效)
select * from user where age > 10 (不生效)
(如上图)hash索引:Hash 进行检索效率非常高,通过对key进行hash并可以找到对应的数据,但是它是**不支持范围查询**的,如上面的sql
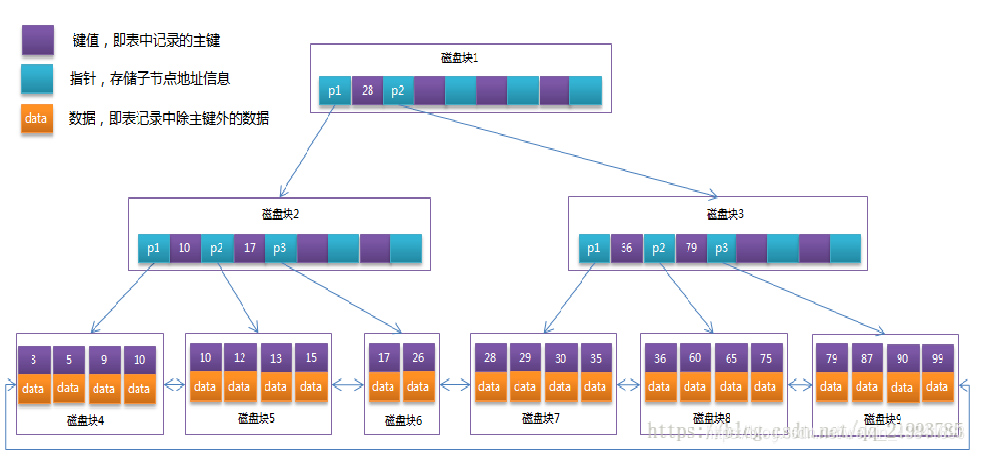
(如上图)b+tree索引:它是由一个个磁盘块组成的。形成一颗树,特性如下 1, 非叶子节点只存储主键 2, 叶子节点存储数据,并且数据与数据之间有指针关联,这就是为什么范围查询b+tree起到作用了。 3,需要注意的是,b+tree形成的时候就已经按照索引的顺序排列了。 **疑问**: 1,为什么b+tree要把data数据存放在叶子节点呢? 2,为什么非叶子节点只存放主键呢? 解答: 1, mysql默认每一节点层是存储16k的数据,目的是为了使非叶子节点存储更多的索引key值,控制树的高度。 2, 假设:存储的主键索引是bigint类型,默认是8b大小,而存储子节点的地址是6b,总共14b。16kb/14b=1170,所以根节点可以存储1170个key,假设有三层的话,默认存储的数据1k的话,那么叶节点可以存储16个数据,1170*1170*16=两千一百多万,两千多万的数据只需要三次I/O就可以找到数据。 总结: **hash**不支持范围查询,时间复杂度:O(1) **B+tree**支持范围查询,时间复杂度:O(log n) 一般项目中我们常用的都是B—tree的索引,因为需要范围查询,这个根据实际情况建立索引。
定位sql+分析sql
优化哪些sql:
首先,我们要对sql进行优化,那必须要找到执行慢的sql,可以通过下面的步骤设置对sql的监控
开启慢查询日志:
Linux系统下是编辑/etc/my.conf 开启慢查询日志:slow_query_log=ON 慢查询日志记录到的文件路径:slow_query_log_file=/var/lib/mysql/slow-mysql.log 执行超过多少秒为慢查询:long_query_time=1 (超过1秒钟视为慢查询) 在命令窗口通过命令导出慢sql mysqldumpslow slow-mysql.log
通过explain关键字查看该sql执行计划
写法:explain + (需要分析的sql)

type:
system :const的特例,仅返回一条数据的时候。 const : 查找主键索引,返回的数据至多一条(0或者1条)。 属于精确查找 eq_ref : 查找唯一性索引,返回的数据至多一条。属于精确查找 ref : 查找非唯一性索引,返回匹配某一条件的多条数据。属于精确查找、数据返回可能是多条 range : 查找某个索引的部分索引,一般在where子句中使用 < 、>、in、between等关键词。只检索给定范围的行,属于范围查找 index : 查找所有的索引树,比ALL要快的多,因为索引文件要比数据文件小的多 ALL : 不使用任何索引,进行全表扫描,性能最差。
表示实际使用的索引
rows:
扫描出的行数(估算的行数)
filtered:
按表条件过滤的行百分比
执行情况的描述和说明
实战:
假如一张表有三百多万条数据,需要分页查询出billType 为’abc’ 和 status为1的第2000000后10 条记录?
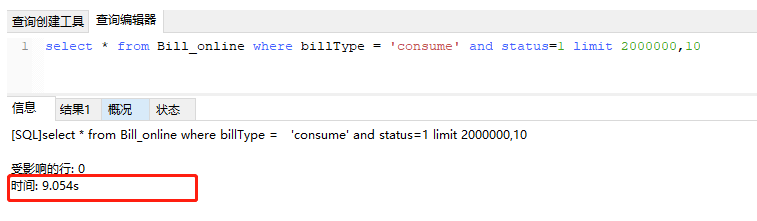
优化前的sql : select * from Bill_online where billType = 'abc' and status=1 limit 2000000,10
我们来分析一下。在没有索引条件下分页搜索的原理:
mysql从 0 到 2000000 所有数据全部扫描一次,然后再取出10条数据,最后丢弃前面的数据,这样大量浪费了时间。经过测试**全表扫描**用时:** 2.7**s 那我们上面讲到,mysql的索引既然那么快,我们不妨加个索引看看,加索引也是有规则的,如何加才能让索引起到作用,这里条件是billType和status,我们给他加个联合索引(b-tree类型的,因为我们是范围查询)。
创建语句:ALTER TABLEBillADD INDEXbillType_status_index(billType,status) USING BTREE ;
索引已经建立完毕,接着跑了一下sql。如下图,9s多,天啊
不急不急,我们照常分析一下。
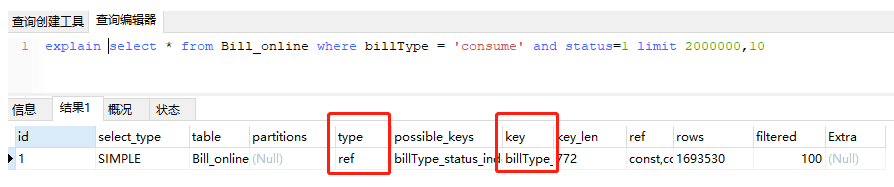
如上图:该sql执行计划用到索引,为什么会如此慢呢,比全表扫描还要慢上6秒,那我们来看一下用到索引的执行原理和过程,才能判断他为什么那么慢。
#####
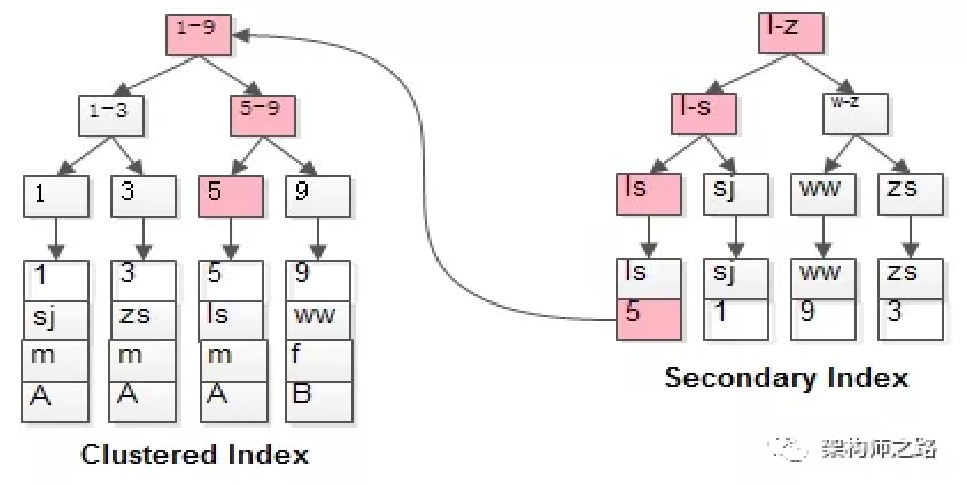
以下为重点,需要耐心耐心耐心的细看哦:
如上图,右边为普通索引,左边为聚集索引,聚集索引就是以主键作为索引,这个是默认的,并且叶子节点是存有索引对应的行数据的,称为聚集索引,而普通索引呢,叶子节点存放的是主键索引的指针,而上面建立的联合索引就是一个普通索引,这一点大家需要清楚。
那我们分析下加了索引的sql,该sql是利用我们创建的联合索引(普通索引)去查询数据,从1开始查,先是在右边索引树找到对应的主键id,在通过id去找对应的行数据,这里因为返回的列是 “*” ,这些数据只有主键索引的树才有,所有每次查都会从右边开始,一直找左边的树,最后找到数据再返回。一直到2000000行,这里利用所有慢的理由就是每次都要遍历两棵索引树,大大浪费了IO。
那我们能不能只扫描右边的树呢,这样不就可以减少IO时间了吗。那我们看看右边的树有什么数据,联合索引的值:billType,status,id, 这三种类型数据,那我们可以先取出需要的id,再去右边的表扫描取出需要的数据,那这样是不是更快呢,这里就是用到了覆盖索引,覆盖索引就是说当前用到的索引在该索引树可以直接取到数据,不需要回表查询。
优化后:
select * from Bill_online b inner join
(select id from Bill_online where billType = 'consume' and status=1 limit 2000000,10) a
on a.id = b.id
我们看一下上面的sql,通过子查询把需要的id查询出来(用到覆盖索引),然后在拿着id去inner join需要的数据。这样就大大减少了不必要的IO了。
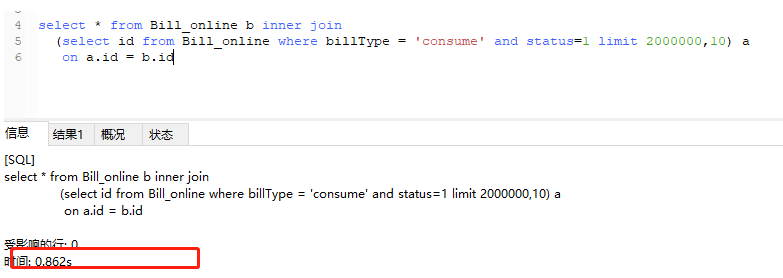
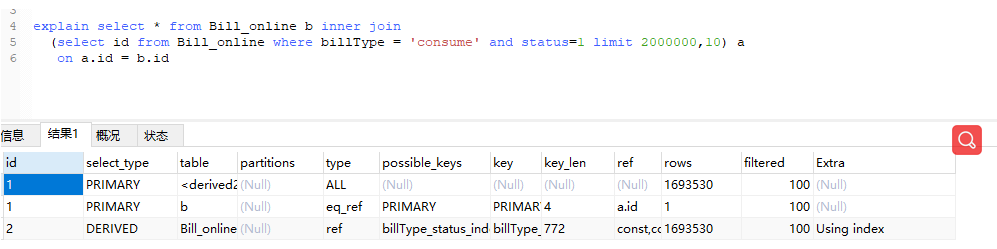
如上图,优化后直接是进入1秒,这差距是不是有点大,我们再来通过explain看看执行计划。如下图:
这里其实还可以再优化下:
select * from Bill_online where id >=( select id from Bill_online where billType = 'consume' and status=1 limit 2000000,1) limit 10
其实原理都是一样的,我们需要掌握索引存储和执行原理,以及通过explain分析,索引创建的规则等等。。
下章为大家讲解:如何正确建立索引,最左匹配法,建立索引需要注意什么,如何避免索引失效等等……