Deep Learning是大神Ian GoodFellow, Yoshua Bengio 和 Aaron Courville合著的深度学习的武功秘籍,涵盖深度学习各个领域,从基础到前沿研究。因为封面上有人工智能生成的鲜花图像,人送外号“花书” 。该书系统地介绍了深度学习的基础知识和后续发展,是一本值得反复读的好书。
这里根据书的框架做笔记如下,方便以后回顾阅读,加油!!!
1.0 引言
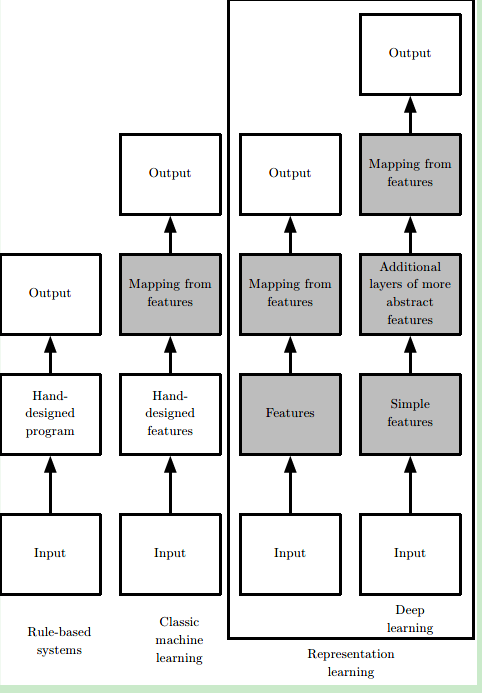
什么是machine learning?在原始的AI系统中,定义不同的case使用不同的解决方法,这称为“hard code”。进一步的AI系统需要一种去获取知识的能力,也就是从原始数据中发现模(“Pattern”),这种能力就是machine learning。
但是,一般的machine learning算法严重依赖于数据的表示(representation),表示中包含的每份信息又称为feature。这又引发了一个新的问题,对于很多task,我们不知道应该提取什么样的特征(只能经验主义)。机器学习早期的时候十分依赖于已有的知识库和人为的逻辑规则,需要人们花大量的时间去制定合理的逻辑判定,可以说是有多少人工,就有多少智能。后来逐渐发展出一些简单的机器学习方法例如logistic regression、naive bayes等,机器可以通过一些特征来学习一定的模式出来,但这非常依赖于可靠的特征,比如对于logistic regression用来辅助医疗诊断,我们无法将核磁共振图像直接输入机器来作出诊断,而是医生需要先做一份报告总结一些特征,而机器通过报告中提供的表征再来进行机器学习,这就对如何提取有效表征提出了很大的要求,仍是一个需要花费很多人力的过程。
于是又有了representation learning,即使用machine learning不光光是学习reprsentation到output的映射(mapping),还要学习data到representation的映射。使用机器学习来发掘表示本身,而不仅仅把表示映射到输出。人们发展出了表征学习(representation learning),希望机器自己能够提取出有意义的特征而无需人为干预。
典型的表示学习算法是autoencoder。encoder函数是将输入数据映射成表示;decoder函数将表示映射回原始数据的格式。我们期望当输入数据经过编码器和解码器之后尽可能多地保留信息,同时希望新的表示有各种好的特性,这也是自编码器的训练目标。
representation learning的难点:表示是多种多样的,一种表示学习算法很难覆盖多种层次和不同类型的表示。也就是多个因素同时影响观察到的数据,从原始数据中提取如此高层次、抽象的特征是非常困难的。
Deep Learning:使用多层次的结构,用简单的表示来获取高层的表示。这样,解决了上面的问题(一种方法)。让计算机通过较简单概念构建复杂的概念。
这些表征很有可能是隐含的、抽象的,比如图像识别中单个像素可能没有有效的信息,更有意义的是若干像素组成的边,由边组成的轮廓,进而由轮廓组成的物体。深度学习就是通过一层层的表征学习,每层可能逻辑很简单,但之后的层可以通过对前面简单的层的组合来构建更复杂的表征。经典的例子如多层感知机(multilayer perceptron),就是每个感知机的数理逻辑都很简单,层内可以并行执行,层间顺序执行,通过层层叠加实现更复杂的逻辑。深度学习的“深”可以理解为通过更多层来结合出更复杂的逻辑,这就完成了从输入到内在层层表征再由内在表征到输出的映射。
花书总体结构
花书可以大致分为三大部分:
- 机器学习基础知识:涵盖线性代数,概率论,数值计算和传统机器学习基础等知识。如果之前学过Andrew Ng的CS229的话基本可以跳过。
- 深度神经网络核心知识:属于本书必读部分,涵盖前馈神经网络,卷积神经网络(CNN),递归神经网络(RNN) 等。
- 深度学习前沿:有一些前沿研究领域的介绍,如线性因子模型,表征学习,生成模型等。
1.1 深度学习的历史趋势
目前为止深度学习已经经历了三次发展浪潮:
1、20 世纪40 年代到60 年代深度学习的雏形出现在控制论(cybernetics)中,是从神经科学的角度出发的简单线性模型,但局限是无法学习非线性的异或函数。不过,这个时期为后来的深度学习打下基础,我们现在训练常用的随机梯度下降算法(stochastic gradient descent)就是源自处理这个时期的一种线性模型——自适应线性单元(Adaptive Linear Neuron)。虽然现在仍有媒体经常将深度学习与神经科学类比,但是由于我们对大脑工作机制的研究进展缓慢,所以实际上现在深度学习从业者已很少从神经科学中寻找灵感。;
2、20 世纪80 年代到90 年代深度学习表现为联结主义(connectionism)或并行分布处理,主要是强调很多的简单的计算单位可以通过互联进行更复杂的计算。这个时期成果很多,比如现在常用的反向传播算法(back propagation)还有自然语言处理中常用的LSTM(第十章讲递归神经网络时详谈)都来自与这个时期。之后由于很多AI产品期望过高而又无法落地,研究热潮逐渐退去。
3、直到2006 年,才真正以深度学习之名复兴。由于软硬件性能的提高,深度学习逐渐应用在各个领域,深度学习研究重整旗鼓。“深度”学习的名字成为主流,意在强调可以训练更多层次更复杂的神经网络,“深”帮助我们开发更复杂的模型,解决更复杂的问题。
深度学习火起来的原因,主要是由于两点:1.我们有更大量的数据进行训练 2.我们有更好的软硬件可以支持更复杂的模型。
随着模型准确度的提高,深度学习也逐渐得到更广泛的实际应用,比如图像识别,语音识别,机器翻译等领域。像DeepMind AlphaGo这种强化学习方面的应用更是掀起了全民AI热潮。与此同时,各种深度学习框架的出现如Caffe,Torch,Tensorflow等也方便更多人学习或利用深度学习模型。这些反过来又促进了深度学习行业的发展。
参考文献:
https://zhuanlan.zhihu.com/p/38431213
http://www.deeplearningbook.org/
https://applenob.github.io/deep_learning_1.html