逻辑回归常见问题:
1)https://www.cnblogs.com/ModifyRong/p/7739955.html
2)https://www.cnblogs.com/lianyingteng/p/7701801.html
3)LR 推导
(0)推导在笔记上,现在摘取部分要点如下:
LR回归是在线性回归模型的基础上,使用sigmoid函数,将线性模型 wTx的结果压缩到[0,1]之间,使其拥有概率意义。 其本质仍然是一个线性模型,实现相对简单。在广告计算和推荐系统中使用频率极高,是CTR预估模型的基本算法。同时,LR模型也是深度学习的基本组成单元。
LR回归属于概率性判别式模型,之所谓是概率性模型,是因为LR模型是有概率意义的;之所以是判别式模型,是因为LR回归并没有对数据的分布进行建模,也就是说,LR模型并不知道数据的具体分布,而是直接将判别函数,或者说是分类超平面求解了出来。
决策边界并不是训练集的属性,而是假设本身和参数的属性。因为训练集不可以定义决策边界,它只负责拟合参数;而只有参数确定了,决策边界才得以确定。
LR回归给我的直观感受就是:它利用Sigmoid的一些性质,使得线性回归(多项式回归)从拟合数据神奇的转变成了拟合数据的边界,使其更加有助于分类!就一个感触:NB!
(1)逻辑回归的损失函数为什么要使用极大似然函数作为损失函数?
- 损失函数一般有四种,平方损失函数,对数损失函数,HingeLoss0-1损失函数,绝对值损失函数。将极大似然函数取对数以后等同于对数损失函数。在逻辑回归这个模型下,对数损失函数的训练求解参数的速度是比较快的。至于原因大家可以求出这个式子的梯度更新
这个式子的更新速度只和xij,yi相关。和sigmod函数本身的梯度是无关的。这样更新的速度是可以自始至终都比较的稳定。
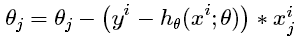
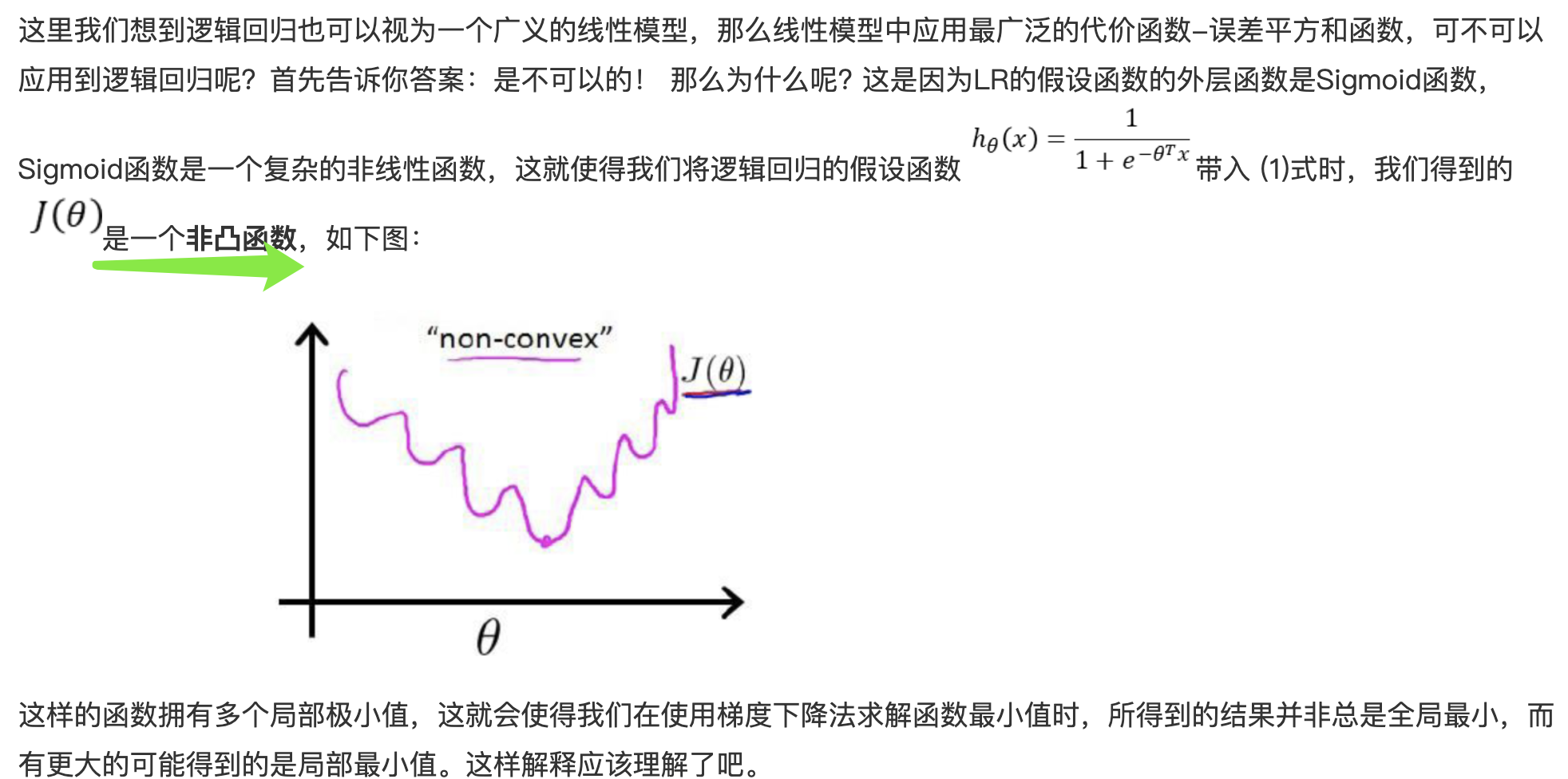
- 为什么不选平方损失函数的呢?其一是因为如果你使用平方损失函数,你会发现梯度更新的速度和sigmod函数本身的梯度是很相关的。sigmod函数在它在定义域内的梯度都不大于0.25。这样训练会非常的慢。

- 交叉熵衡量概率分布的差异,分类标签的 one-hot 是概率分布,网络输出 softmax 是概率分布,损失函数衡量两个分布之间的差异;
(2)逻辑回归在训练的过程当中,如果有很多的特征高度相关或者说有一个特征重复了100遍,会造成怎样的影响?
- 先说结论,如果在损失函数最终收敛的情况下,其实就算有很多特征高度相关也不会影响分类器的效果。
- 但是对特征本身来说的话,假设只有一个特征,在不考虑采样的情况下,你现在将它重复100遍。训练完以后,数据还是这么多,但是这个特征本身重复了100遍,实质上将原来的特征分成了100份,每一个特征都是原来特征权重值的百分之一。
- 如果在随机采样的情况下,其实训练收敛完以后,还是可以认为这100个特征和原来那一个特征扮演的效果一样,只是可能中间很多特征的值正负相消了。
(3) 为什么我们还是会在训练的过程当中将高度相关的特征去掉?
- 去掉高度相关的特征会让模型的可解释性更好
- 可以大大提高训练的速度。如果模型当中有很多特征高度相关的话,就算损失函数本身收敛了,但实际上参数是没有收敛的,这样会拉低训练的速度。其次是特征多了,本身就会增大训练的时间。
(4)LR中若标签为+1和-1,损失函数如何推导?
- way1:把0-1的sigmoid的lr结果Y映射为2y-1,推导不变
- way2:把激活函数换成tanh,因为tanh的值域范围为[-1,1],满足结果,推导不变
- way3:依旧以sigmoid函数的话,似然函数(likelihood)模型是:


(5)逻辑回归的优缺点总结
在这里我们总结了逻辑回归应用到工业界当中一些优点:
- 形式简单,模型的可解释性非常好。从特征的权重可以看到不同的特征对最后结果的影响,某个特征的权重值比较高,那么这个特征最后对结果的影响会比较大。
- 模型效果不错。在工程上是可以接受的(作为baseline),如果特征工程做的好,效果不会太差,并且特征工程可以大家并行开发,大大加快开发的速度。
- 训练速度较快。分类的时候,计算量仅仅只和特征的数目相关。并且逻辑回归的分布式优化sgd发展比较成熟,训练的速度可以通过堆机器进一步提高,这样我们可以在短时间内迭代好几个版本的模型。
- 资源占用小,尤其是内存。因为只需要存储各个维度的特征值,。
- 方便输出结果调整。逻辑回归可以很方便的得到最后的分类结果,因为输出的是每个样本的概率分数,我们可以很容易的对这些概率分数进行cutoff,也就是划分阈值(大于某个阈值的是一类,小于某个阈值的是一类)。
但是逻辑回归本身也有许多的缺点:
- 准确率并不是很高。因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布。
- 很难处理数据不平衡的问题。举个例子:如果我们对于一个正负样本非常不平衡的问题比如正负样本比 10000:1.我们把所有样本都预测为正也能使损失函数的值比较小。但是作为一个分类器,它对正负样本的区分能力不会很好。
- 处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据,或者进一步说,处理二分类的问题 。
- 逻辑回归本身无法筛选特征。有时候,我们会用gbdt来筛选特征,然后再上逻辑回归。
(6)预处理数据做两件事:
- 如果测试集中一条数据的特征值已经确实,那么我们选择实数0来替换所有缺失值,因为本文使用Logistic回归。因此这样做不会影响回归系数的值。sigmoid(0)=0.5,即它对结果的预测不具有任何倾向性。
- 如果测试集中一条数据的类别标签已经缺失,那么我们将该类别数据丢弃,因为类别标签与特征不同,很难确定采用某个合适的值来替换。
(7)逻辑回归用于多分类:
有两种方式可以出处理该类问题:一种是我们对每个类别训练一个二元分类器(One-vs-all),当K个类别不是互斥的时候,比如用户会购买哪种品类,这种方法是合适的。
如果K个类别是互斥的,即 y=i的时候意味着 y 不能取其他的值,比如用户的年龄段,这种情况下 Softmax 回归更合适一些。Softmax 回归是直接对逻辑回归在多分类的推广,相应的模型也可以叫做多元逻辑回归(Multinomial Logistic Regression)。

(8)应用举例
这里以预测用户对品类的购买偏好为例,介绍一下美团是如何用逻辑回归解决工作中问题的。该问题可以转换为预测用户在未来某个时间段是否会购买某个品类,如果把会购买标记为1,不会购买标记为0,就转换为一个二分类问题。
提取的特征的时间跨度为30天,标签为2天。生成的训练数据大约在7000万量级(美团一个月有过行为的用户),我们人工把相似的小品类聚合起来,最后有18个较为典型的品类集合。如果用户在给定的时间内购买某一品类集合,就作为正例。哟了训练数据后,使用Spark版的LR算法对每个品类训练一个二分类模型,迭代次数设为100次的话模型训练需要40分钟左右,平均每个模型2分钟,测试集上的AUC也大多在0.8以上。训练好的模型会保存下来,用于预测在各个品类上的购买概率。预测的结果则会用于推荐等场景。
由于不同品类之间正负例分布不同,有些品类正负例分布很不均衡,我们还尝试了不同的采样方法,最终目标是提高下单率等线上指标。经过一些参数调优,品类偏好特征为推荐和排序带来了超过1%的下单率提升。
1、关于模型在各个维度进行不均匀伸缩后,最优解与原来等价吗?
答:等不等价要看最终的误差优化函数。如果经过变化后最终的优化函数等价则等价。明白了这一点,那么很容易得到,如果对原来的特征乘除某一常数,则等价。做加减和取对数都不等价。
2. 过拟合和欠拟合如何产生,如何解决?
欠拟合:根本原因是特征维度过少,导致拟合的函数无法满足训练集,误差较大;
解决方法:增加特征维度;
过拟合:根本原因是特征维度过大,导致拟合的函数完美的经过训练集,但对新数据的预测结果差。
解决方法:(1)减少特征维度;(2)正则化,降低参数值。
减少过拟合总结:过拟合主要是有两个原因造成的:数据太少+模型太复杂
(1)获取更多数据 :从数据源头获取更多数据;数据增强(Data Augmentation) :数据增强,常用的方式:上下左右翻转flip,旋转图像,平移变换,随机剪切crop图像,图像尺度变换,改变图像色差、对比度,仿射变换,扭曲图像特征,增强图像噪音(一般使用高斯噪音,盐椒噪音)等
(2)使用合适的模型:减少网络的层数、神经元个数等均可以限制网络的拟合能力;
(3)dropout
(3)正则化,在训练的时候限制权值变大;
(4)限制训练时间;通过评估测试;
(4)增加噪声 Noise: 输入时+权重上(高斯初始化)
(5)结合多种模型: Bagging用不同的模型拟合不同部分的训练集;Boosting只使用简单的神经网络;
3、关于逻辑回归,连续特征离散化的好处
在工业界,很少直接将连续值作为特征喂给逻辑回归模型,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
-
稀疏向量内积乘法运算速度快,计算结果方便存储,容易scalable(扩展)。
-
离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰。
-
逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合。
-
离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力。
-
特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问。
大概的理解:1)计算简单;2)简化模型;3)增强模型的泛化能力,不易受噪声的影响。
4、一些问题:
解决过拟合的方法:数据扩充、正则项、提前终止
如何用LR建立一个广告点击的模型:
特征提取—>特征处理(离散化、归一化、onehot等)—>找出候选集—->模型训练,得到结果
为什么LR需要归一化或取对数?
符合假设、利于分析、归一化也有利于梯度下降
为什么LR把特征离散化后效果更好?
引入非线性