2.1 用户行为数据简介
- 用户行为数据可分为显性反馈行为和隐性反馈行为;
- 用户数据的统一表示;


2.2 用户行为分析
在设计推荐算法之前需要对用户行为数据进行分析,了解数据中蕴含的一般规律可以对算法的设计起到指导作用。
- 用户活跃度和物品流行度
- 均近似符合长尾分布:e.g. 物品流行度定义:对用户产生过行为的总数;e.g. 用户活跃度定义:对物品产生过行为的总数
- 活跃度和流行度的关系:一般新用户倾向于浏览热门的物品,因为他们对网站还不熟悉,只能点击首页的热门物品,而老用户会逐渐开始浏览冷门的物品(用户越活跃,越倾向于浏览冷门物品)。
- 协同过滤算法:仅基于用户行为数据设计的算法。
- 方法有基于领域的方法(最广泛)、基于图的随机游走算法、隐语义算法。
- 基于领域的方法可分为基于用户的协同过滤算法和基于物品的协同过滤算法。
2.3 实验设计和算法评测
以离线评测为例。topN推荐问题:预测用户会不会对某部电影评分,而不是预测用户在准备对某部电影评分的前提下,会给电影评多少分。
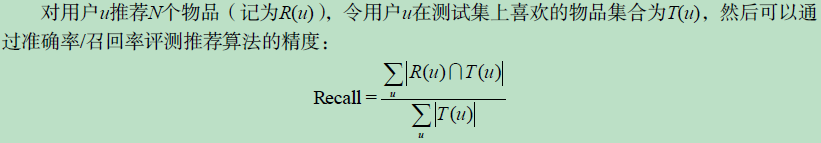
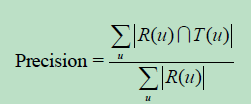

2.4 基于邻域的算法
1、基于用户的协同过滤算法
基础算法步骤:(1)找到和目标用户兴趣相似的用户集合;
(2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
主要利用行为的相似度量用户的相似度。量化相似: Jaccard 相似度 / 余弦相似度 / 欧式距离。
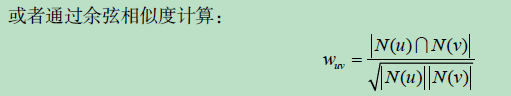

参考指标:
- 准确率 / 召回率:参数K的选择比较重要;
- 覆盖度:K越大,流行度越高,推荐物品就越热门,长尾物品推荐就少,覆盖率就低;
- 流行度:K越大,参考的人就越多,结果就越趋近全局热门物品;
UserCF缺点:计算量大;运算时间复杂度和空间复杂度的增长和用户数的增长近似于平方关系。
用户相似度计算的改进:两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度,用物品热门度进行惩罚。实验证明,考虑物品的流行度对提升推荐结果的质量确实有帮助。
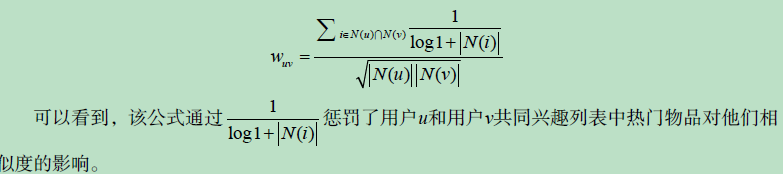

2、基于物品的协同过滤算法
(1)基础算法:给用户推荐那些和他们之前喜欢的物品相似的物品。其中,相似度不是利用物品的内容属性计算物品之间的相似度,主要分析用户的行为记录计算物品之间的相似度。



(2)用户活跃度对物品相似度的影响:活跃用户对物品相似度的贡献应该小于不活跃的用户.
可以加惩罚项,但对于过度活跃用户,直接忽略他的兴趣列表。IUF的加入对准确率和召回率影响很小,但提高了覆盖率,降低了流行度,总体上改进了推荐算法。

(3)物品相似度的归一化

由于热门的类其类内物品相似度比较大,如果不进行归一化,就会推荐比较热门类中的热门物品,覆盖率就低。
(3)UserCF 与 ItemCF 的综合比较
UserCF的推荐结果着重于反映和用户兴趣相似的小群体的热点,而ItemCF的推荐结果着重于维系用户的历史兴趣。换句话说,UserCF的推荐更社会化,反映了用户所在的小型兴趣群体中物品的热门程度,而ItemCF的推荐更加个性化,反映了用户自己的兴趣传承。
UserCF适用于新闻:(a)个性化新闻推荐更加强调抓住新闻热点,热门程度和时效性是重点,而个性化相对次要些。(b)技术方面:新闻多且快,物品相关列表更新跟不上,而用户相对好些,对于冷启动问题,可以直接推荐热门新闻。
ItemCF适用于图书、商务、电影网站:用户兴趣比较固定持久,个性化相对重要性,物品增长速度也不会很快,一天一更新就好。

2.5 隐语义模型
基础算法(LFM):核心思想是通过隐藏特征(latent factor)联系用户兴趣和物品。对于一个用户,首先得到用户兴趣分类,再从分类中挑选他可能喜欢的物品。
从数据出发,自动找到归类,采用基于用户行为统计的自动聚类。


损失函数:可用随机梯度下降法求解
重要参数:隐特征个数 / 学习速率 / 正则化系数 / 负正样本比例。其中正负样本比例影响最大,控制了推荐算法发掘长尾的能力。
LFM的关键之一:如何生成负样本(隐形反馈数据集,只有正样本,所以要生成负样本)。当数据集很稀疏时,性能会明显下降。原则如下:

基于LFM的实际系统的例子。
LFM模型有个实际应用问题,很难实现实时推荐。模型需要训练迭代且耗时,在新闻推荐关注中,冷启动问题非常明显,好的推荐算法需要在新闻短暂的生命周期内将其推送给对他感兴趣的用户。针对实时性这个问题,雅虎的解决方案:

LFM和基于领域的方法的比较:
- 理论基础:LFM是一种基于机器学习的方法,通过优化一个设定的目标建立最优模型;基于领域的方法是统计方法,没有学习过程;
- 离线计算的空间复杂度:前者节省训练内存,后者需要维护一个离线相关表,数据量大时占用大量内存。LFM:O(MF + FN);UserCF: O(MM);ItemCF: O(NN)
- 离线计算的时间复杂度:LFM: O(KFS);UserCF: O(M(K/M)^2);ItemCF: O(N(K/N)^2)
- 在线实时推荐:LFM实现在线实时推荐难度较高

- 推荐解释:ItemCF有较好的解释性,LFM较难解释