1. Hadoop Ecosystem
存储:HDFS (Hadoop distributed file system)
计算:MapReduce
资源调度(resource negotiator):YARN
2. the master-slave architecture of Hadoop
manager负责对workers进行调度,如YARN
架构的具体体现:MapReduce job(细分成小任务,再汇总);HDFS集群的存储/管理(NameNode相当于manager;DataNode相当于worker);Spark
3. NameNode对元数据进行存储,DateNode即数据本身
Secondary Name Node用来辅助NameNode(引入原因:若所有record都存入内存,一断电就没有了;若所有record都存入磁盘,每次都要读取效率太低;所以引入fsimage edits两个文件;若每次都是NameNode自己启动的时候合并,启动速度过慢;所以引入Secondary NameNode提醒并帮助合并;Name Node挂掉的时候,也可以把Secondary NameNode里面的文件拷贝过来)但是secondary Name Node不是Name Node的备份!
DataNode要向NameNode报告,确保有效
4. HDFS blocks默认存储3份,大文件分块结束之后,每个块都会被备份,存在不同的DataNode中。Block size默认128MB
sample question: given a file of 500MB, let block size be 150MB, and replication factor=3. How much space do we need to store this file in HDFS and why?
500 need to be seperated into 150, 150, 150, 50. Since everyone need to be copied 3 times, in total we need (150*3+150*3+150*3+50*3)
5. 如果Block size过小,block的数量会过多,NameNode会包含过多metadata,读取时会花费过多时间
6. HDFS分块计算,ass第一题
7. HDFS读写流程
write in:create file -- write file -- close file
there is only single writer allowed at any time
the blocks are writing simultaneously
for one block, the replications are replicationg sequentially
the choose of DataNodes is random, based on replication management policy, rack awareness
8. HDFS rack awareness(机架感知)用于判断NameNode请求上传文件的时候,该选择哪些DataNode
if the replica will be stored on the local DataNode
第一个副本存储在local DataNode上,即同一台设备上
第二个副本存储在不同的rack上
第三个跟第二个副本在同一个rack上的不同设备上
9. Read in HDFS
multiple readers are allowed to read at the same time
the blocks are reading simultaneously
always choose the closest DataNodes to the client (based on the newwork topology)
handling errors and corrupted blocks (avoid visiting the dataNode again, report to NameNode)
10. HDFS erasure coding
替代replication的存储方法,在Hadoop3.0引入的
通过存储数学计算而不是原始的数字,从而减少存储次数。丢失的时候可以通过计算找到丢失的数字
11. erasure coding的存储过程
横着看是一个stripe,竖着看是一个block
存储的时候从左到右,从上到下存储。每一个block都被竖着分为200个Cell,一个cell64Kb
12. block group contains 6 raw data blocks and 3 parity blocks
13. http://www.yunsuan.info/matrixcomputations/solvematrixinverse.html
14. Fsimage添加元数据,editlog添加对数据进行的操作,读取的时候结合在一起读;secondary NameNode利用checkpoint可以提醒并帮助Fsimage与editlog合并
15. MapReduce的缺点
more suitable for one-pass computation on a large dataset,不适用于重复多次的计算
hard to compose and nest multiple operations,总要读写磁盘,所以效率很低
#spark的解决方法:将中间计算过程全写在内存里
16. Spark的feature
写入内存里;Parallel;Fault-tolerant;Lazy evaluation
17. Spark architecture
master node:driver程序的入口(main)里面声明了SparkContext
cluster manager是一台不管计算,只负责任务资源调度的机器
worker是负责计算的机器
executor是真正的JVM线程
18. RDD (Resilient Distributed Dataset)
RDD is where the data stays
RDD is the fundamental data structure of Apache Spark (is a collection of elements, can be operated on in parallel, fault tolerant)
19. RDD只有在collect之后才会有数据
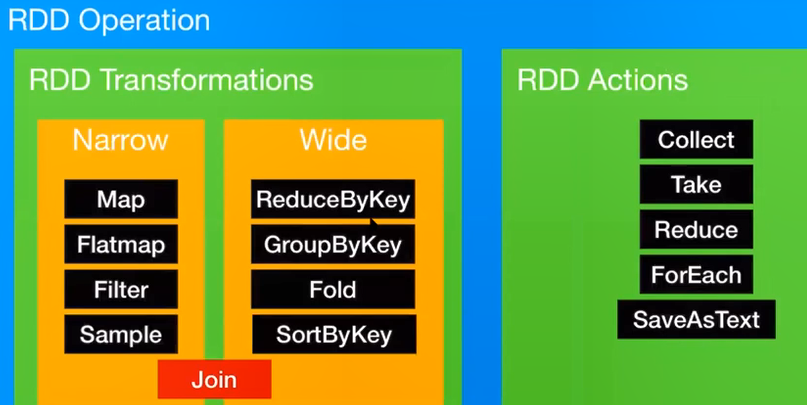
20. RDD operation