1. 概述 2. HTTP请求过程 3. 相关性能检测及优化手段 4. 浏览器的呈现过程 5. 浏览器的呈现引擎 6. 引用及延伸阅读
概述
为什么输入www.cnblogs.com之后敲一个回车,浏览器就会显示我们所看到的内容?这家伙在背后到底偷偷的干了哪些事情?今天我们就来挖掘一下这背后的故事。
HTTP请求过程
为直观明了,先上一张图:

画完之后,才发现原来我的字写的这么难看,别喷我,小伙伴们!
下面是详细的步骤以及说明:
- 输入URL,敲回车。
- 针对当前URL检查是否存在本地缓存, 如果存在,则会加载本地缓存进行呈现。如图,经过 (1)-> (2) ->(9) ->(10)。 ( 感谢“我是你的猪”的纠错 :) )
- 根据URL找到对应的IP地址。这一步通常被称为DNS轮询,这里面是有缓存机制的。缓存的顺序依次为:浏览器缓存->操作系统缓存->路由器缓存->DNS提供商缓存->DNS提供商轮询。
- 建立TCP连接到上一步找到的机器
- 用上一步建立的连接发送http request
- 等待并接收http response
- 关闭TCP连接,视情况而定,http1.1已经支持keep-alive。那么这个TCP请求是可以被后面的request利用的,这样就可以减少不断建立连接而造成的损失。
- 检查状态码,如果response的状态码出现3XX(跳转),未授权(401),错误(4XX和5XX)会有不同的处理。
- 准备呈现,如果response status 为304(内容未更改)浏览器则会从本来缓存加载内容进行呈现。
- 呈现
相关性能检测及优化手段
在很多浏览器的辅助工具中,大都将上述步骤分为了以下5 个:
- DNS轮询
- 建立连接
- 发送请求
- 等待响应
- 接受请求

我们通过查看这个时间线,就可以粗略知道我们的网站是否有性能问题以及问题出在哪里?然后我们就可以针对性的解决。
拿上图举例,第4步“等待响应”所花的时间为3.03秒。所谓等待响应主要是页面的处理时间,比如说查询数据库、业务逻辑处理计算等等直接最后把html代码封装成response返回。(关于IIS的请求处理过程我们后面再探讨)如果这一步的时间过长,那我们就要考虑从后台动态代码处理逻辑,以及数据查询方面下手去找问题了。另外需要监控并发量,是否服务器同时处理的请求过多导致处理时间过长等。
第3步和第5步如果时间过长,我们可以通过以下方式来解决。
- Request会携带cookie传输,这就是除了安全性考虑以外为什么我们建议限制cookie数据和大小的原因。
- Response 如果是html代码我们可以考虑代码压缩和gzip压缩。
- 静态资源可以采用其它的方式直接压缩。
- 建立CDN网络服务不同地域的用户。
浏览器的呈现过程
这里有一个略虚的问题,当我们输完www.cnblogs.com之后,到底是一个http请求,还是多个?
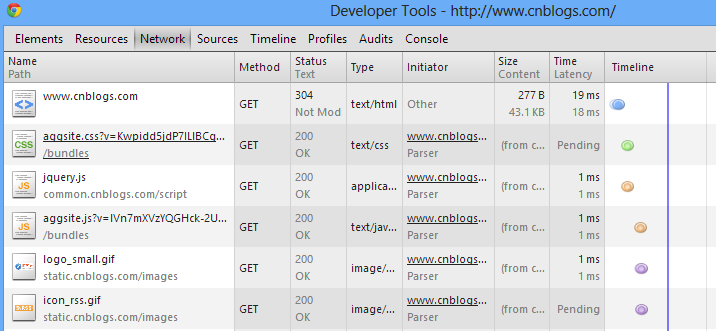
我们或许可以说,只有一个请求是直接产生的,而后面一堆的请求是取绝于我们所输入的URL。我们可以看到第一个请求的Path就是我们输入的URL,当这个请求的类型为text/html的时候,也就是说这个请求返回给我们的是html代码。那么浏览器会去呈现这个页面。
但是如果我们直接输入:http://common.cnblogs.com/script/jquery.js 这个时候当然浏览器不会去发起其它请求(前提条件是这个JS里面没有主动去请求其它资源的情况下)。而浏览器对于每一种请求类型的处理方式是不一样的,像text/html、application/JavaScript、text/plain等等这些是可以直接呈现的,而对于不能呈现的类型,浏览器会将该资源下载到本地。

总的来说,实际的请求数量是1+这个请求资源里面所包含其它资源的数量。
接下来,我们主要看一下,浏览器如果呈现text/html类型的请求。上面我们讲到的http的请求过程中的第6步浏览器已经拿到了返回结果即response。

那么浏览器在确认这个response的状态不是301(跳转)或者401(未授权)或其它需要做特殊处理的状态,之后开始进入呈现过程。
浏览器的呈现引擎
呈现引擎:负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。默认情况下,呈现引擎可显示 HTML 和 XML 文档与图片。通过插件(或浏览器扩展程序),还可以显示其它类型的内容;例如,使用 PDF 查看器插件就能显示 PDF 文档。这里我们主要讨论它的主要功能:显示使用 CSS 格式化的 HTML 内容和图片。
呈现引擎的处理步骤包括4个:

- 解析html转换成DOM树。浏览器有一个内置组件叫HTML解析器,会遍历HTML代码去生成DOM树。
- 结合部分CSS样式将DOM树转换成呈现树(这里面的样式包括颜色尺码等)。这里有浏览器的另外一个内置组件叫CSS解析器会遍历所有的CSS内容行成一组样式规则。这里面的CSS解析器和上一步的HTML解析器是同时进行的,之后会将样式规则附加到DOM树上就形成了我们的呈现树。
- 通过呈现树构建布局树,主要是为每一个DOM元素分配了一个应出现在屏幕上的确切坐标。
- 遍历呈现树,绘制每一个节点。

为了缩短整个呈现的过程,浏览器不会等到所有的DOM树和所有的样式规则都准备好再进行显示。而是一边解析一边显示,如果后面有JavaScript改变了某一些元素的样式属性则会导致重流(Reflow)和重绘(Repaint)。关于什么是重流和重绘这里就不详述了,网上有很多相关的资料,有兴趣的同鞋可以戳这里:重流和重绘
这是我的第一篇博客,主要是想对自己所掌握的知识有一个总结,也查看了很多网上的资料以及前辈们的博客J。当然也是想跟大家分享关于web方面的知识,我的侧重点主要在于web的一些运行机制,后面还会继续,下一篇将讨论一下关于IIS以及ASP.NET的运行机制,欢迎大家拍砖。
引用及延伸阅读
1. 浏览器工作原理:http://ux.sohu.com/topics/50972d9ae7de3e752e0081ff 2. What happens when you navigate to a URL: http://igoro.com/archive/what-really-happens-when-you-navigate-to-a-url/ 3. 前端必读之Best Practices for Speeding Up Your Web Site:http://developer.yahoo.com/performance/rules.html