卷积层的非线性部分
一、ReLU定义
ReLU:全称 Rectified Linear Units)激活函数
定义
def relu(x):
return x if x >0 else 0
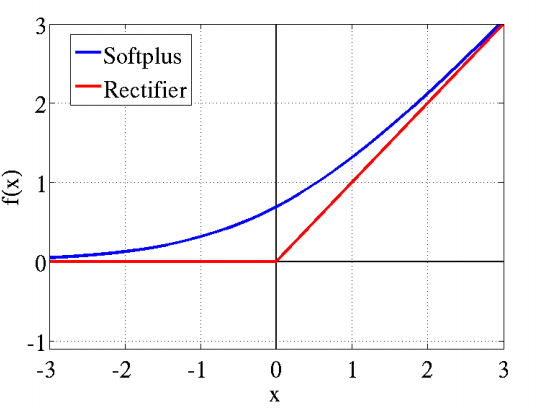
#Softplus为ReLU的平滑版
二、传统sigmoid系激活函数
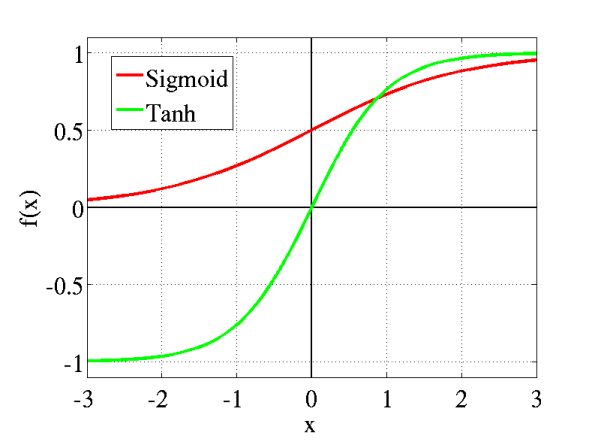
Sigmoid与人的神经反应很相似,在很多浅层模型上发挥巨大作用
传统神经网络中最常用的两个激活函数,Sigmoid系(Logistic-Sigmoid、Tanh-Sigmoid)被视为神经网络的核心所在。
从数学上来看,非线性的Sigmoid函数对中央区的信号增益较大,对两侧区的信号增益小,在信号的特征空间映射上,有很好的效果。
从神经科学上来看,中央区酷似神经元的兴奋态,两侧区酷似神经元的抑制态,因而在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧区。
无论是哪种解释,看起来都比早期的线性激活函数(y=x),阶跃激活函数(-1/1,0/1)高明了不少。
梯度消失问题
sigmoid导数值的范围(0, 0.25)
tanh的导数值范围(0, 1)
可以看出sigmoid的弱点:对于深度网络,sigmoid在最好的情况下也会把传递的导数数值缩小至0.25倍,下层网络得到的梯度值明显小很多。这会导致模型训练效果很差。
对于浅层网络这种影响不明显,但对于深度网络,反向传导逐渐变成了一个“漫长累积”的过程。
从训练效果看,以不同激活函数的LeNet模型,训练迭代数与Loss的关系——
sigmoid明显弱一些,tanh与ReLU相近
ReLU的优点:没有出现梯度消失问题
三、ReLU的线性性质
作为一个非线性函数,它还具备线性性质
1 0 0
[ 0 1 0 ] x 向量 = 结果
0 0 0
对线性部分的输出,结果等效于左乘一个非0即1的对角阵(向量负数位置对应对角阵位置上为0),仍可以被看作是一个线性操作
这一性质会使模型的理论分析变得简单
四、ReLU的不足
1:过于宽广的接受域,在接受较大数据时出现不稳定
可以对输入数据上界进行限制,比如ReLU6
2:负数方向
输入数据的负数部分,ReLU会把它置为0,那么梯度也为0,训练过程中负数部分不会更新
解决:一系列的改进函数,比如 Leaky ReLU