参考博客:
https://www.cnblogs.com/xiao987334176/p/9041318.html
线程概念的引入背景
进程
之前我们已经了解了操作系统中进程的概念,程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
有了进程为什么要有线程
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
-
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
-
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
如果这两个缺点理解比较困难的话,举个现实的例子也许你就清楚了:如果把我们上课的过程看成一个进程的话,那么我们要做的是耳朵听老师讲课,手上还要记笔记,脑子还要思考问题,这样才能高效的完成听课的任务。而如果只提供进程这个机制的话,上面这三件事将不能同时执行,同一时间只能做一件事,听的时候就不能记笔记,也不能用脑子思考,这是其一;如果老师在黑板上写演算过程,我们开始记笔记,而老师突然有一步推不下去了,阻塞住了,他在那边思考着,而我们呢,也不能干其他事,即使你想趁此时思考一下刚才没听懂的一个问题都不行,这是其二。
现在你应该明白了进程的缺陷了,而解决的办法很简单,我们完全可以让听、写、思三个独立的过程,并行起来,这样很明显可以提高听课的效率。而实际的操作系统中,也同样引入了这种类似的机制——线程。
线程的出现
操作系统是管理进程的,每个进程是资源隔离的。在一个操作系统中,同一时间,可以有多个任务。
多个任务之间的内存必须隔离开。比如使用qq的时候还能使用微信。并发要求日益增加,比如聊天的时候,可以开多个窗口,还可以看电影,听歌...
开启一个子进程的开销,是很大的。操作系统在进程之间的切换,时间开销也很大。
进程之间的通信:
数据共享 : 时间开销
如果多个子进程之间的数据共享量过多的时候,
就不应该将这些数据隔离开
一个进程 —— 实现不了并发
你既不希望数据隔离,还要实现并发的效果。那么就应该使用线程
线程是轻量级的进程
线程的创建和销毁所需要的时间开销都非常小
线程直接使用进程的内存
线程不能独立存在,要依赖于进程
进程和线程的关系

|
1
|
print(123) |
执行输出:123
真正执行代码的是线程
程序启动是一个进程。
使用线程执行代码,接受CPU调度。
线程的时间开销小于进程时间开销
线程的特点


TCB包括以下信息: (1)线程状态。 (2)当线程不运行时,被保存的现场资源。 (3)一组执行堆栈。 (4)存放每个线程的局部变量主存区。 (5)访问同一个进程中的主存和其它资源。 用于指示被执行指令序列的程序计数器、保留局部变量、少数状态参数和返回地址等的一组寄存器和堆栈。
使用线程的实际场景

开启一个字处理软件进程,该进程肯定需要办不止一件事情,比如监听键盘输入,处理文字,定时自动将文字保存到硬盘,这三个任务操作的都是同一块数据,因而不能用多进程。只能在一个进程里并发地开启三个线程,如果是单线程,那就只能是,键盘输入时,不能处理文字和自动保存,自动保存时又不能输入和处理文字。
内存中的线程

多个线程共享同一个进程的地址空间中的资源,是对一台计算机上多个进程的模拟,有时也称线程为轻量级的进程。
而对一台计算机上多个进程,则共享物理内存、磁盘、打印机等其他物理资源。多线程的运行也多进程的运行类似,是cpu在多个线程之间的快速切换。
不同的进程之间是充满敌意的,彼此是抢占、竞争cpu的关系,如果迅雷会和QQ抢资源。而同一个进程是由一个程序员的程序创建,所以同一进程内的线程是合作关系,一个线程可以访问另外一个线程的内存地址,大家都是共享的,一个线程干死了另外一个线程的内存,那纯属程序员脑子有问题。
类似于进程,每个线程也有自己的堆栈,不同于进程,线程库无法利用时钟中断强制线程让出CPU,可以调用thread_yield运行线程自动放弃cpu,让另外一个线程运行。
线程通常是有益的,但是带来了不小程序设计难度,线程的问题是:
1. 父进程有多个线程,那么开启的子线程是否需要同样多的线程
2. 在同一个进程中,如果一个线程关闭了文件,而另外一个线程正准备往该文件内写内容呢?
因此,在多线程的代码中,需要更多的心思来设计程序的逻辑、保护程序的数据。
线程是轻量级的进程
线程的创建和销毁所需要的时间开销都非常小
线程直接使用进程的内存
线程不能独立存在,要依赖于进程
进程 —— 资源分配的最小单位
线程 —— CPU调度的最小单位
轻型进程 : 创建、销毁、切换 开销比进程小
数据不隔离
可以并发
依赖进程
每一个进程里至少有一个线程
进程负责管理资源、线程负责执行代码
|
1
2
3
|
def func(exp): 2+3*5-6 # 它不会影响全局变量 return eval(exp) |
python程序运行起来 —— 进程
进程 —— 管理整个程序的内存,
存储全局的变量 : 内置的函数 全局的名字
线程 —— 执行代码
用户级线程和内核级线程(了解)
线程的实现可以分为两类:用户级线程(User-Level Thread)和内核线线程(Kernel-Level Thread),后者又称为内核支持的线程或轻量级进程。在多线程操作系统中,各个系统的实现方式并不相同,在有的系统中实现了用户级线程,有的系统中实现了内核级线程。
用户级线程
内核的切换由用户态程序自己控制内核切换,不需要内核干涉,少了进出内核态的消耗,但不能很好的利用多核Cpu。

在用户空间模拟操作系统对进程的调度,来调用一个进程中的线程,每个进程中都会有一个运行时系统,用来调度线程。此时当该进程获取cpu时,进程内再调度出一个线程去执行,同一时刻只有一个线程执行。
内核级线程
内核级线程:切换由内核控制,当线程进行切换的时候,由用户态转化为内核态。切换完毕要从内核态返回用户态;可以很好的利用smp,即利用多核cpu。windows线程就是这样的。

用户级与内核级线程的对比
内核支持线程是OS内核可感知的,而用户级线程是OS内核不可感知的。
用户级线程的创建、撤消和调度不需要OS内核的支持,是在语言(如Java)这一级处理的;而内核支持线程的创建、撤消和调度都需OS内核提供支持,而且与进程的创建、撤消和调度大体是相同的。
用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行;在有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
用户级线程的程序实体是运行在用户态下的程序,而内核支持线程的程序实体则是可以运行在任何状态下的程序。
优点:当有多个处理机时,一个进程的多个线程可以同时执行。
缺点:由内核进行调度。
优点:
线程的调度不需要内核直接参与,控制简单。
可以在不支持线程的操作系统中实现。
创建和销毁线程、线程切换代价等线程管理的代价比内核线程少得多。
允许每个进程定制自己的调度算法,线程管理比较灵活。
线程能够利用的表空间和堆栈空间比内核级线程多。
同一进程中只能同时有一个线程在运行,如果有一个线程使用了系统调用而阻塞,那么整个进程都会被挂起。另外,页面失效也会产生同样的问题。
缺点:
资源调度按照进程进行,多个处理机下,同一个进程中的线程只能在同一个处理机下分时复用
混合实现
用户级与内核级的多路复用,内核同一调度内核线程,每个内核线程对应n个用户线程

linux操作系统的 NPTL
历史 在内核2.6以前的调度实体都是进程,内核并没有真正支持线程。它是能过一个系统调用clone()来实现的,这个调用创建了一份调用进程的拷贝,跟fork()不同的是,这份进程拷贝完全共享了调用进程的地址空间。LinuxThread就是通过这个系统调用来提供线程在内核级的支持的(许多以前的线程实现都完全是在用户态,内核根本不知道线程的存在)。非常不幸的是,这种方法有相当多的地方没有遵循POSIX标准,特别是在信号处理,调度,进程间通信原语等方面。 很显然,为了改进LinuxThread必须得到内核的支持,并且需要重写线程库。为了实现这个需求,开始有两个相互竞争的项目:IBM启动的NGTP(Next Generation POSIX Threads)项目,以及Redhat公司的NPTL。在2003年的年中,IBM放弃了NGTP,也就是大约那时,Redhat发布了最初的NPTL。 NPTL最开始在redhat linux 9里发布,现在从RHEL3起内核2.6起都支持NPTL,并且完全成了GNU C库的一部分。 设计 NPTL使用了跟LinuxThread相同的办法,在内核里面线程仍然被当作是一个进程,并且仍然使用了clone()系统调用(在NPTL库里调用)。但是,NPTL需要内核级的特殊支持来实现,比如需要挂起然后再唤醒线程的线程同步原语futex. NPTL也是一个1*1的线程库,就是说,当你使用pthread_create()调用创建一个线程后,在内核里就相应创建了一个调度实体,在linux里就是一个新进程,这个方法最大可能的简化了线程的实现。 除NPTL的1*1模型外还有一个m*n模型,通常这种模型的用户线程数会比内核的调度实体多。在这种实现里,线程库本身必须去处理可能存在的调度,这样在线程库内部的上下文切换通常都会相当的快,因为它避免了系统调用转到内核态。然而这种模型增加了线程实现的复杂性,并可能出现诸如优先级反转的问题,此外,用户态的调度如何跟内核态的调度进行协调也是很难让人满意。
线程和python
理论知识
全局解释器锁GIL
Python代码的执行由Python虚拟机(也叫解释器主循环)来控制。Python在设计之初就考虑到要在主循环中,同时只有一个线程在执行。虽然 Python 解释器中可以“运行”多个线程,但在任意时刻只有一个线程在解释器中运行。
对Python虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
在多线程环境中,Python 虚拟机按以下方式执行:
a、设置 GIL;
b、切换到一个线程去运行;
c、运行指定数量的字节码指令或者线程主动让出控制(可以调用 time.sleep(0));
d、把线程设置为睡眠状态;
e、解锁 GIL;
d、再次重复以上所有步骤。
在调用外部代码(如 C/C++扩展函数)的时候,GIL将会被锁定,直到这个函数结束为止(由于在这期间没有Python的字节码被运行,所以不会做线程切换)编写扩展的程序员可以主动解锁GIL。
python线程模块的选择
Python提供了几个用于多线程编程的模块,包括thread、threading和Queue等。thread和threading模块允许程序员创建和管理线程。thread模块提供了基本的线程和锁的支持,threading提供了更高级别、功能更强的线程管理的功能。Queue模块允许用户创建一个可以用于多个线程之间共享数据的队列数据结构。
避免使用thread模块,因为更高级别的threading模块更为先进,对线程的支持更为完善,而且使用thread模块里的属性有可能会与threading出现冲突;其次低级别的thread模块的同步原语很少(实际上只有一个),而threading模块则有很多;再者,thread模块中当主线程结束时,所有的线程都会被强制结束掉,没有警告也不会有正常的清除工作,至少threading模块能确保重要的子线程退出后进程才退出。
thread模块不支持守护线程,当主线程退出时,所有的子线程不论它们是否还在工作,都会被强行退出。而threading模块支持守护线程,守护线程一般是一个等待客户请求的服务器,如果没有客户提出请求它就在那等着,如果设定一个线程为守护线程,就表示这个线程是不重要的,在进程退出的时候,不用等待这个线程退出。
threading模块
multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性,因而不再详细介绍(官方链接)
线程的创建Threading.Thread类
线程的创建
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('egon',)) t.start() print('主线程')
from threading import Thread import time class Sayhi(Thread): def __init__(self,name): super().__init__() self.name=name def run(self): time.sleep(2) print('%s say hello' % self.name) if __name__ == '__main__': t = Sayhi('egon') t.start() print('主线程')
多线程与多进程
from threading import Thread from multiprocessing import Process import os def work(): print('hello',os.getpid()) if __name__ == '__main__': #part1:在主进程下开启多个线程,每个线程都跟主进程的pid一样 t1=Thread(target=work) t2=Thread(target=work) t1.start() t2.start() print('主线程/主进程pid',os.getpid()) #part2:开多个进程,每个进程都有不同的pid p1=Process(target=work) p2=Process(target=work) p1.start() p2.start() print('主线程/主进程pid',os.getpid())
from threading import Thread from multiprocessing import Process import os def work(): print('hello') if __name__ == '__main__': #在主进程下开启线程 t=Thread(target=work) t.start() print('主线程/主进程') ''' 打印结果: hello 主线程/主进程 ''' #在主进程下开启子进程 t=Process(target=work) t.start() print('主线程/主进程') ''' 打印结果: 主线程/主进程 hello '''
from threading import Thread from multiprocessing import Process import os def work(): global n n=0 if __name__ == '__main__': # n=100 # p=Process(target=work) # p.start() # p.join() # print('主',n) #毫无疑问子进程p已经将自己的全局的n改成了0,但改的仅仅是它自己的,查看父进程的n仍然为100 n=1 t=Thread(target=work) t.start() t.join() print('主',n) #查看结果为0,因为同一进程内的线程之间共享进程内的数据 同一进程内的线程共享该进程的数据?
练习 :多线程实现socket
#_*_coding:utf-8_*_ #!/usr/bin/env python import multiprocessing import threading import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.bind(('127.0.0.1',8080)) s.listen(5) def action(conn): while True: data=conn.recv(1024) print(data) conn.send(data.upper()) if __name__ == '__main__': while True: conn,addr=s.accept() p=threading.Thread(target=action,args=(conn,)) p.start()
#_*_coding:utf-8_*_ #!/usr/bin/env python import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue s.send(msg.encode('utf-8')) data=s.recv(1024) print(data)
Thread类的其他方法

Thread实例对象的方法 # isAlive(): 返回线程是否活动的。 # getName(): 返回线程名。 # setName(): 设置线程名。 threading模块提供的一些方法: # threading.currentThread(): 返回当前的线程变量。 # threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 # threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
from threading import Thread import threading from multiprocessing import Process import os def work(): import time time.sleep(3) print(threading.current_thread().getName()) if __name__ == '__main__': #在主进程下开启线程 t=Thread(target=work) t.start() print(threading.current_thread().getName()) print(threading.current_thread()) #主线程 print(threading.enumerate()) #连同主线程在内有两个运行的线程 print(threading.active_count()) print('主线程/主进程') ''' 打印结果: MainThread <_MainThread(MainThread, started 140735268892672)> [<_MainThread(MainThread, started 140735268892672)>, <Thread(Thread-1, started 123145307557888)>] 主线程/主进程 Thread-1 '''
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('egon',)) t.start() t.join() print('主线程') print(t.is_alive()) ''' egon say hello 主线程 False '''
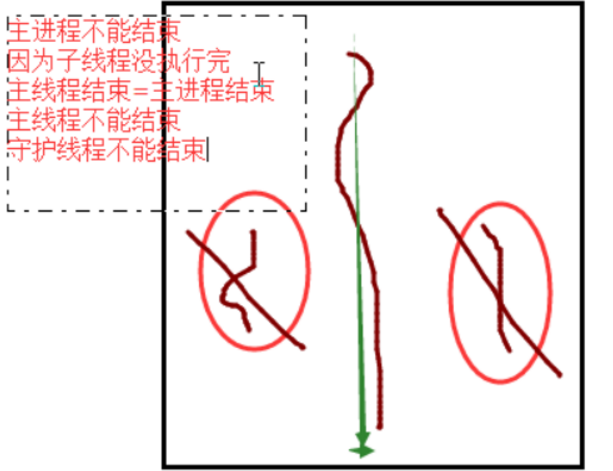
守护线程
无论是进程还是线程,都遵循:守护xx会等待主xx运行完毕后被销毁。需要强调的是:运行完毕并非终止运行
#1.对主进程来说,运行完毕指的是主进程代码运行完毕 #2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
#1 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束, #2 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('egon',)) t.setDaemon(True) #必须在t.start()之前设置 t.start() print('主线程') print(t.is_alive()) ''' 主线程 True '''
from threading import Thread import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") t1=Thread(target=foo) t2=Thread(target=bar) t1.daemon=True t1.start() t2.start() print("main-------")
|
1
2
3
4
|
from threading import Threaddef func(i): print('*'*i)Thread(target=func,args=(1,)).start() |
执行输出:*
开5个线程
|
1
2
3
4
5
6
|
from threading import Threaddef func(i): print('*'*i)for i in range(5): Thread(target=func,args=(i,)).start() |
执行输出:
*
**
***
****
做效率测试,进程和线程,谁更快
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import timefrom threading import Threadfrom multiprocessing import Processdef func(i): print('*'*i)if __name__ == '__main__': start = time.time() for i in range(5): Thread(target=func,args=(i,)).start() print('线程',time.time()-start) start = time.time() for i in range(5): Process(target=func,args=(i,)).start() print('进程',time.time()-start) |
执行输出:
*
**
***
****
线程 0.0020182132720947266
进程 0.0661768913269043
*
**
***
****
从结果中,可以看出:线程比进程更快。
使用join方法等待所有线程/进程执行完毕,再测试
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import timefrom threading import Threadfrom multiprocessing import Processdef func(i): print('*'*i)if __name__ == '__main__': start = time.time() thread_lst = [] for i in range(5): t = Thread(target=func,args=(i,)) t.start() thread_lst.append(t) for t in thread_lst:t.join() # 等待所有线程执行完毕 print('线程',time.time()-start) start = time.time() process_lst = [] for i in range(5): p = Process(target=func,args=(i,)) p.start() process_lst.append(p) for p in process_lst:p.join() print('进程',time.time()-start) |
执行输出:
*
**
***
****
线程 0.0030286312103271484
*
**
***
****
进程 0.16040682792663574
线程并发效果:
所有方法睡1秒
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import timefrom threading import Threaddef func(i): time.sleep(1) print('*'*i)if __name__ == '__main__': start = time.time() thread_lst = [] for i in range(10): t = Thread(target=func,args=(i,)) t.start() thread_lst.append(t) for t in thread_lst:t.join() print(time.time()-start) |
执行输出
*
**
*****
********
******
****
*******
***
*********
1.003647804260254
线程执行,是异步的。
操作系统控制了线程的执行。线程执行,顺序是乱的。
并发执行,没有顺序。从结果中,就可以看出。
打印线程号
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import osimport timefrom threading import Threaddef func(i): print('--->子线程',os.getpid()) time.sleep(1) print('*'*i)if __name__ == '__main__': print('主进程',os.getpid()) start = time.time() thread_lst = [] for i in range(10): t = Thread(target=func,args=(i,)) t.start() thread_lst.append(t) for t in thread_lst:t.join() print(time.time()-start) |
执行输出:
主进程 20120
--->子线程 20120
--->子线程 20120
--->子线程 20120
--->子线程 20120
--->子线程 20120
--->子线程 20120
--->子线程 20120
--->子线程 20120
--->子线程 20120
--->子线程 20120
****
**
*
***
*****
*********
*******
******
********
1.0029516220092773
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
import osimport timefrom threading import Threaddef func(i): print('--->子线程',os.getpid()) time.sleep(1) print('*'*i)if __name__ == '__main__': print('主进程',os.getpid()) start = time.time() thread_lst = [] for i in range(10): t = Thread(target=func,args=(i,)) t.start() #Thread.name 获取和设置线程的名称 #Thread.ident 获取线程的标识符 print('-->',t.name,t.ident) thread_lst.append(t) for t in thread_lst:t.join() # 等待所有线程结束 print(time.time()-start) |
执行输出:
主进程 20260
--->子线程 20260
--> Thread-1 21460
--->子线程 20260
--> Thread-2 20580
--->子线程 20260
--> Thread-3 21456
--->子线程 20260
--> Thread-4 19076
--->子线程 20260
--> Thread-5 5988
--->子线程 20260
--> Thread-6 17780
--->子线程 20260
--> Thread-7 20572
--->子线程 20260
--> Thread-8 20604
--->子线程 20260
--> Thread-9 20308
--->子线程 20260
--> Thread-10 19312
*
**
****
***
********
******
*******
*****
*********
1.0048184394836426
可以看出
同一个进程下的多个线程进程号相同 : 线程号不同
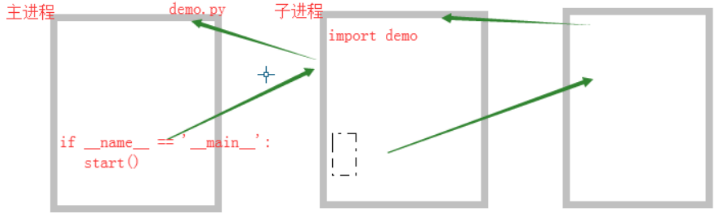
为什么进程执行需要if __name__ == '__main__' :
而线程不需要呢?看下图
停不下来了,主因是start()
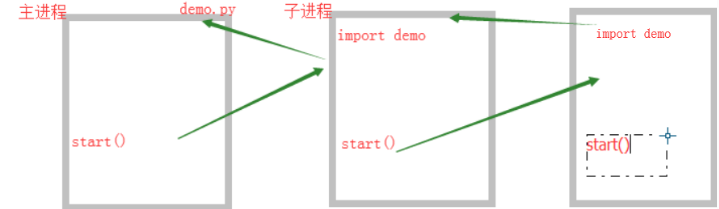
加了if __name__ = '__main__' ,不会出现循环导入问题
进程执行时,相当于把当前文件给import了一次,那么所有代码会加载一次。
而线程执行时,是直接从进程中获取值。
线程引用主进程的变量,修改数据
|
1
2
3
4
5
6
7
8
9
10
11
|
from threading import Threadn = 100def manage(): global n n = 0 # 修改全局变量t = Thread(target=manage)t.start()t.join()print('-->',n) |
执行输出:
--> 0
结论:
线程和进程的区别:
1. 效率问题 : 线程快 进程慢
2. 同一个进程下的多个线程进程号相同 : 线程号不同
3. if __name__ == '__main__' : 开启进程 必须有这句话 但是开启线程不需要
这种现象只在windows操作系统上才出现
4. 数据的共享问题:在进程之间数据隔离,在线程之间数据共享
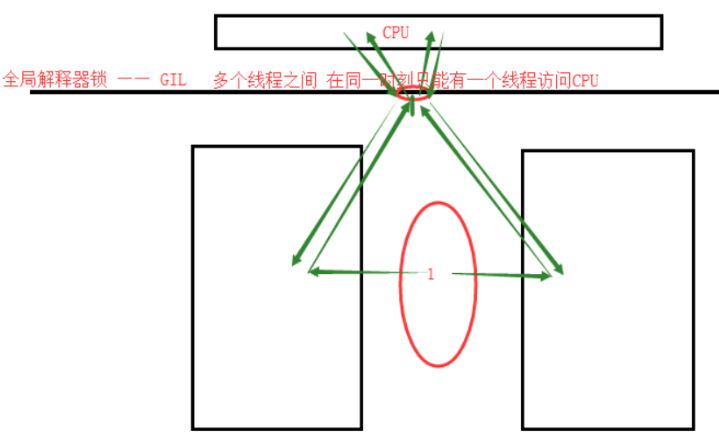
GIL问题,截止到目前为止,还没有解决。
解释行语言,都存在这个问题
GIL,主要是锁线程。不是锁进程。
python代码 --> 字节码--> 机器码
c语言 字节码 --> 机器码
python 多线程同时,只能调用一个CPU。而C语言,能直接调用多个CPU。
所以在高计算性场景中,C比python更胜一筹
python更适合高IO型的程序 : 比如web网站,爬虫...
python的程序就不能充分的利用CPU了呢???使用多进程就可以解决。
多进程 —— 开启和销毁的时候慢,操作系统切换的时候也慢
但是切换的影响非常小
GIL —— 全局解释器锁
锁线程 :在计算的时候 同一时刻只能有一个线程访问CPU
线程锁限制了你对CPU的使用,但是不影响web类或者爬虫类代码的效率
我们可以通过启动多进程的形式来弥补这个问题
|
1
2
3
4
5
6
7
8
9
10
|
import timefrom threading import Threaddef func1(): while True: time.sleep(1) print('子线程')t = Thread(target=func1)t.start()print('主线程') |
执行输出:
主线程
子线程
子线程
...
一直在输出子线程。为什么呢?
主线程,会等待子线程结束
|
1
2
3
4
5
6
7
8
9
10
11
|
import timefrom threading import Threaddef func1(): # 守护线程 while True: time.sleep(1) print('子线程')t = Thread(target=func1)t.setDaemon(True)t.start()print('主线程') |
执行输出:
主线程
发送瞬间就执行完毕了。
为啥子线程,没输出呢?因主线程执行完毕,子线程随之关闭。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import timefrom threading import Threaddef func1(): # 守护线程 while True: time.sleep(1) print('子线程')def func2(): time.sleep(5) print('子线程2')t = Thread(target=func1)t2 = Thread(target=func2)t.setDaemon(True) # 设置守护线程t.start()t2.start()print('主线程') |
执行输出:
主线程
子线程
子线程
子线程
子线程
子线程2
结论:
主进程的守护进程是在主进程的代码结束,守护进程就结束了
主线程的守护线程会在非守护线程的所有线程执行完毕之后才结束
在同一个进程里面的多个线程,会受到GIL锁的限制。
多个进程之间,不会有GIL
一个CPU,同时只有一个线程执行
cpu同一时刻只能执行一个进程?答案是的
cpu同一时刻只能执行一个进程中的某一个线程
之前写的python代码,都是属于单线程的程序