上一节内容【algo&ds】4.树和二叉树、完全二叉树、满二叉树、二叉查找树、平衡二叉树、堆、哈夫曼树、散列表
7.B树
B树的应用可以参考另外一篇文章
8.字典树Trie

Trie 树,也叫“字典树”。顾名思义,它是一个树形结构。它是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。它的一个经典应用场景就是输入框的自动提示。
举个例子来说明一下,我们有 6 个字符串,它们分别是:how,hi,her,hello,so,see。我们希望在里面多次查找某个字符串是否存在。如果每次查找,都是拿要查找的字符串跟这 6 个字符串依次进行字符串匹配,那效率就比较低。我们就可以先对这 6 个字符串做一下预处理,组织成 Trie 树的结构,之后每次查找,都是在 Trie 树中进行匹配查找。Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。最后构造出来的就是下面这个图中的样子。

根节点不包含任何信息。每个节点表示一个字符串中的字符,从根节点到红色节点的一条路径表示一个字符串(注意:红色节点并不都是叶子节点)。
Trie树的构造过程如下:


当我们在 Trie 树中查找一个字符串的时候,比如查找字符串“her”,那我们将要查找的字符串分割成单个的字符 h,e,r,然后从 Trie 树的根节点开始匹配。如图所示,绿色的路径就是在 Trie 树中匹配的路径。

如果我们要查找的是字符串“he”呢?我们还用上面同样的方法,从根节点开始,沿着某条路径来匹配,如图所示,绿色的路径,是字符串“he”匹配的路径。但是,路径的最后一个节点“e”并不是红色的。也就是说,“he”是某个字符串的前缀子串,但并不能完全匹配任何字符串。

8.1字典树的存储结构
对于前面的trie树的逻辑存储结构,可以理解为下面这幅图

8.2字典树的代码实现及常用操作
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int Status;
typedef struct Node {
char data;
struct Node *children[26];
Status end;
} Trie, *TriePtr;
void Init(TriePtr *T)
{
(*T) = (TriePtr)malloc(sizeof(Trie));
(*T)->data = '/';
(*T)->end = FALSE;
}
void Insert(TriePtr T, char *str) {
int index;
char c;
while(c = *str++)
{
index = c - 'a';
if (T->children[index] == NULL)
{
TriePtr Node;
Node = (TriePtr)malloc(sizeof(Trie));
Node->data = c;
Node->end = FALSE;
T->children[index] = Node;
}
T = T->children[index];
}
T->end = TRUE;
}
Status Search(TriePtr T, char *str) {
int index;
char c;
while(c = *str++)
{
index = c - 'a';
if (T->children[index] == NULL)
{
return FALSE;
}
T = T->children[index];
}
if (T->end) {
return TRUE;
} else {
return FALSE;
}
}
int main(int argc, char const *argv[])
{
TriePtr T;
Init(&T);
char *str = "hello";
char *str2 = "hi";
Insert(T, str);
printf("str is search %d
", Search(T, str));
printf("str2 is search %d
", Search(T, str2));
return 0;
}
8.3复杂度分析
时间复杂度
如果要在一组字符串中,频繁地查询某些字符串,用 Trie 树会非常高效。构建 Trie 树的过程,需要扫描所有的字符串,时间复杂度是 O(n)(n 表示所有字符串的长度和)。但是一旦构建成功之后,后续的查询操作会非常高效。每次查询时,如果要查询的字符串长度是 k,那我们只需要比对大约 k 个节点,就能完成查询操作。跟原本那组字符串的长度和个数没有任何关系。所以说,构建好 Trie 树后,在其中查找字符串的时间复杂度是 O(k),k 表示要查找的字符串的长度。
空间复杂度
Trie 树是非常耗内存的,用的是一种空间换时间的思路。
刚刚我们在讲 Trie 树的实现的时候,讲到用数组来存储一个节点的子节点的指针。如果字符串中包含从 a 到 z 这 26 个字符,那每个节点都要存储一个长度为 26 的数组,并且每个数组存储一个 8 字节指针(或者是 4 字节,这个大小跟 CPU、操作系统、编译器等有关)。而且,即便一个节点只有很少的子节点,远小于 26 个,比如 3、4 个,我们也要维护一个长度为 26 的数组。Trie 树的本质是避免重复存储一组字符串的相同前缀子串,但是现在每个字符(对应一个节点)的存储远远大于 1 个字节。按照我们上面举的例子,数组长度为 26,每个元素是 8 字节,那每个节点就会额外需要 26*8=208 个字节。而且这还是只包含 26 个字符的情况。如果字符串中不仅包含小写字母,还包含大写字母、数字、甚至是中文,那需要的存储空间就更多了。所以在某些情况下,Trie 树不一定会节省存储空间。在重复的前缀并不多的情况下,Trie 树不但不能节省内存,还有可能会浪费更多的内存。
8.4Trie树和红黑树、散列表的比较
在刚刚讲的这个场景,在一组字符串中查找字符串,Trie 树实际上表现得并不好。它对要处理的字符串有及其严苛的要求。
- 第一,字符串中包含的字符集不能太大。我们前面讲到,如果字符集太大,那存储空间可能就会浪费很多。即便可以优化,但也要付出牺牲查询、插入效率的代价。
- 第二,要求字符串的前缀重合比较多,不然空间消耗会变大很多。
- 第三,如果要用 Trie 树解决问题,那我们就要自己从零开始实现一个 Trie 树,还要保证没有 bug,这个在工程上是将简单问题复杂化,除非必须,一般不建议这样做。
- 第四,我们知道,通过指针串起来的数据块是不连续的,而 Trie 树中用到了指针,所以,对缓存并不友好,性能上会打个折扣。
综合这几点,针对在一组字符串中查找字符串的问题,我们在工程中,更倾向于用散列表或者红黑树。因为这两种数据结构,我们都不需要自己去实现,直接利用编程语言中提供的现成类库就行了。
9.红黑树
此章节内容都是参考极客时间专栏-《数据结构与算法之美》
9.1红黑树的定义
平衡二叉查找树其实有很多,比如,Splay Tree(伸展树)、Treap(树堆)等,但是我们提到平衡二叉查找树,听到的基本都是红黑树。它的出镜率甚至要高于“平衡二叉查找树”这几个字,有时候,我们甚至默认平衡二叉查找树就是红黑树。
红黑树的英文是“Red-Black Tree”,简称 R-B Tree。它是一种不严格的平衡二叉查找树。顾名思义,红黑树中的节点,一类被标记为黑色,一类被标记为红色。除此之外,一棵红黑树还需要满足这样几个要求:
- 根节点是黑色的;
- 每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据;
- 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的;
- 每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点;
这里的第二点要求“叶子节点都是黑色的空节点”,稍微有些奇怪,它主要是为了简化红黑树的代码实现而设置的。它的结构图案例如下,图中去掉了黑色的、空的叶子节点。

为什么说红黑树是“近似平衡”的?
平衡二叉查找树的初衷,是为了解决二叉查找树因为动态更新导致的性能退化问题。所以,“平衡”的意思可以等价为性能不退化。“近似平衡”就等价为性能不会退化的太严重。
二叉查找树很多操作的性能都跟树的高度成正比。一棵极其平衡的二叉树(满二叉树或完全二叉树)的高度大约是 log2n,所以如果要证明红黑树是近似平衡的,我们只需要分析,红黑树的高度是否比较稳定地趋近 log2n 。
接下来一步一步推导红黑树的高度。
首先,我们来看,如果我们将红色节点从红黑树中去掉,那单纯包含黑色节点的红黑树的高度是多少呢?
红色节点删除之后,有些节点就没有父节点了,它们会直接拿这些节点的祖父节点(父节点的父节点)作为父节点。所以,之前的二叉树就变成了四叉树。

前面红黑树的定义里有这么一条:从任意节点到可达的叶子节点的每个路径包含相同数目的黑色节点。我们从四叉树中取出某些节点,放到叶节点位置,四叉树就变成了完全二叉树。所以,仅包含黑色节点的四叉树的高度,比包含相同节点个数的完全二叉树的高度还要小,所以去掉红色节点的“黑树”的高度也不会超过 log2n。
现在把红色节点加回去,高度会变成多少呢?
在红黑树中,红色节点不能相邻,也就是说,有一个红色节点就要至少有一个黑色节点,将它跟其他红色节点隔开。红黑树中包含最多黑色节点的路径不会超过 log2n,所以加入红色节点之后,最长路径不会超过 2log2n,也就是说,红黑树的高度近似 2log2n。所以,红黑树的高度只比高度平衡的 AVL 树的高度(log2n)仅仅大了一倍,在性能上,下降得并不多。这样推导出来的结果不够精确,实际上红黑树的性能更好。
为什么在工程中大家都喜欢用红黑树这种平衡二叉查找树?
前面提到 Treap、Splay Tree,绝大部分情况下,它们操作的效率都很高,但是也无法避免极端情况下时间复杂度的退化。尽管这种情况出现的概率不大,但是对于单次操作时间非常敏感的场景来说,它们并不适用。AVL 树是一种高度平衡的二叉树,所以查找的效率非常高,但是,有利就有弊,AVL 树为了维持这种高度的平衡,就要付出更多的代价。每次插入、删除都要做调整,就比较复杂、耗时。所以,对于有频繁的插入、删除操作的数据集合,使用 AVL 树的代价就有点高了。红黑树只是做到了近似平衡,并不是严格的平衡,所以在维护平衡的成本上,要比 AVL 树要低。所以,红黑树的插入、删除、查找各种操作性能都比较稳定。对于工程应用来说,要面对各种异常情况,为了支撑这种工业级的应用,我们更倾向于这种性能稳定的平衡二叉查找树。
9.2红黑树的实现
红黑树的建立过程会频繁的破坏它的定义中的第三四点,而我们要做的就是把破坏的点恢复过来。在这之前,需要掌握两个非常重要的操作,左旋和右旋,可以参考如下的图片来理解。

1.插入操作的平衡调整
红黑树规定,插入的节点必须是红色的。而且,二叉查找树中新插入的节点都是放在叶子节点上。所以,关于插入操作的平衡调整,有这样两种特殊情况,但是也都非常好处理。
- 如果插入节点的父节点是黑色的,那我们什么都不用做,它仍然满足红黑树的定义。
- 如果插入的节点是根节点,那我们直接改变它的颜色,把它变成黑色就可以了。
除此之外,其他情况都会违背红黑树的定义,于是我们就需要进行调整,调整的过程包含两种基础的操作:左右旋转和改变颜色。
红黑树的平衡调整过程是一个迭代的过程。我们把正在处理的节点叫作关注节点。关注节点会随着不停地迭代处理,而不断发生变化。最开始的关注节点就是新插入的节点。新节点插入之后,如果红黑树的平衡被打破,那一般会有下面三种情况。我们只需要根据每种情况的特点,不停地调整,就可以让红黑树继续符合定义,也就是继续保持平衡。我们下面依次来看每种情况的调整过程。提醒你注意下,为了简化描述,我把父节点的兄弟节点叫作叔叔节点,父节点的父节点叫作祖父节点。
1.如果关注节点是 a,它的叔叔节点 d 是红色
- 将关注节点 a 的父节点 b、叔叔节点 d 的颜色都设置成黑色;
- 将关注节点 a 的祖父节点 c 的颜色设置成红色;
- 关注节点变成 a 的祖父节点 c;
- 跳到 CASE 2 或者 CASE 3。

2.如果关注节点是 a,它的叔叔节点 d 是黑色,关注节点 a 是其父节点 b 的右子节点
- 关注节点变成节点 a 的父节点 b;
- 围绕新的关注节点b 左旋;
- 跳到 CASE 3。

3.如果关注节点是 a,它的叔叔节点 d 是黑色,关注节点 a 是其父节点 b 的左子节点
- 围绕关注节点 a 的祖父节点 c 右旋;
- 将关注节点 a 的父节点 b、兄弟节点 c 的颜色互换。
- 调整结束。

2.删除操作的平衡调整
删除操作的平衡调整分为两步,第一步是针对删除节点初步调整。初步调整只是保证整棵红黑树在一个节点删除之后,仍然满足最后一条定义的要求,也就是说,每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点;第二步是针对关注节点进行二次调整,让它满足红黑树的第三条定义,即不存在相邻的两个红色节点。
1. 针对删除节点初步调整
这里需要注意一下,红黑树的定义中“只包含红色节点和黑色节点”,经过初步调整之后,为了保证满足红黑树定义的最后一条要求,有些节点会被标记成两种颜色,“红 - 黑”或者“黑 - 黑”。如果一个节点被标记为了“黑 - 黑”,那在计算黑色节点个数的时候,要算成两个黑色节点。在下面的讲解中,如果一个节点既可以是红色,也可以是黑色,在画图的时候,我会用一半红色一半黑色来表示。如果一个节点是“红 - 黑”或者“黑 - 黑”,我会用左上角的一个小黑点来表示额外的黑色。
CASE 1:如果要删除的节点是 a,它只有一个子节点 b
- 删除节点 a,并且把节点 b 替换到节点 a 的位置,这一部分操作跟普通的二叉查找树的删除操作一样;
- 节点 a 只能是黑色,节点 b 也只能是红色,其他情况均不符合红黑树的定义。这种情况下,我们把节点 b 改为黑色;
- 调整结束,不需要进行二次调整。

CASE 2:如果要删除的节点 a 有两个非空子节点,并且它的后继节点就是节点 a 的右子节点 c
- 如果节点 a 的后继节点就是右子节点 c,那右子节点 c 肯定没有左子树。我们把节点 a 删除,并且将节点 c 替换到节点 a 的位置。这一部分操作跟普通的二叉查找树的删除操作无异;
- 然后把节点 c 的颜色设置为跟节点 a 相同的颜色;
- 如果节点 c 是黑色,为了不违反红黑树的最后一条定义,我们给节点 c 的右子节点 d 多加一个黑色,这个时候节点 d 就成了“红 - 黑”或者“黑 - 黑”;
- 这个时候,关注节点变成了节点 d,第二步的调整操作就会针对关注节点来做。

CASE 3:如果要删除的是节点 a,它有两个非空子节点,并且节点 a 的后继节点不是右子节点
- 找到后继节点 d,并将它删除,删除后继节点 d 的过程参照 CASE 1;
- 将节点 a 替换成后继节点 d;
- 把节点 d 的颜色设置为跟节点 a 相同的颜色;
- 如果节点 d 是黑色,为了不违反红黑树的最后一条定义,我们给节点 d 的右子节点 c 多加一个黑色,这个时候节点 c 就成了“红 - 黑”或者“黑 - 黑”;
- 这个时候,关注节点变成了节点 c,第二步的调整操作就会针对关注节点来做。

2.针对关注节点进行二次调整
经过初步调整之后,关注节点变成了“红 - 黑”或者“黑 - 黑”节点。针对这个关注节点,我们再分四种情况来进行二次调整。二次调整是为了让红黑树中不存在相邻的红色节点。
CASE 1:如果关注节点是 a,它的兄弟节点 c 是红色的
- 围绕关注节点 a 的父节点 b 左旋;
- 关注节点 a 的父节点 b 和祖父节点 c 交换颜色;
- 关注节点不变;
- 继续从四种情况中选择适合的规则来调整。

CASE 2:如果关注节点是 a,它的兄弟节点 c 是黑色的,并且节点 c 的左右子节点 d、e 都是黑色的
- 将关注节点 a 的兄弟节点 c 的颜色变成红色;
- 从关注节点 a 中去掉一个黑色,这个时候节点 a 就是单纯的红色或者黑色;
- 给关注节点 a 的父节点 b 添加一个黑色,这个时候节点 b 就变成了“红 - 黑”或者“黑 - 黑”;
- 关注节点从 a 变成其父节点 b;
- 继续从四种情况中选择符合的规则来调整。

CASE 3:如果关注节点是 a,它的兄弟节点 c 是黑色,c 的左子节点 d 是红色,c 的右子节点 e 是黑色
- 围绕关注节点 a 的兄弟节点 c 右旋;
- 节点 c 和节点 d 交换颜色;
- 关注节点不变;
- 跳转到 CASE 4,继续调整。

CASE 4:如果关注节点 a 的兄弟节点 c 是黑色的,并且 c 的右子节点是红色的
- 围绕关注节点 a 的父节点 b 左旋;
- 将关注节点 a 的兄弟节点 c 的颜色,跟关注节点 a 的父节点 b 设置成相同的颜色;
- 将关注节点 a 的父节点 b 的颜色设置为黑色;
- 从关注节点 a 中去掉一个黑色,节点 a 就变成了单纯的红色或者黑色;
- 将关注节点 a 的叔叔节点 e 设置为黑色;
- 调整结束。

9.3为什么红黑树的定义中,要求叶子节点是黑色的空节点?
之所以有这么奇怪的要求,其实就是为了实现起来方便。只要满足这一条要求,那在任何时刻,红黑树的平衡操作都可以归结为我们刚刚讲的那几种情况。
还是有点不好理解,我通过一个例子来解释一下。假设红黑树的定义中不包含刚刚提到的那一条“叶子节点必须是黑色的空节点”,我们往一棵红黑树中插入一个数据,新插入节点的父节点也是红色的,两个红色的节点相邻,这个时候,红黑树的定义就被破坏了。那我们应该如何调整呢?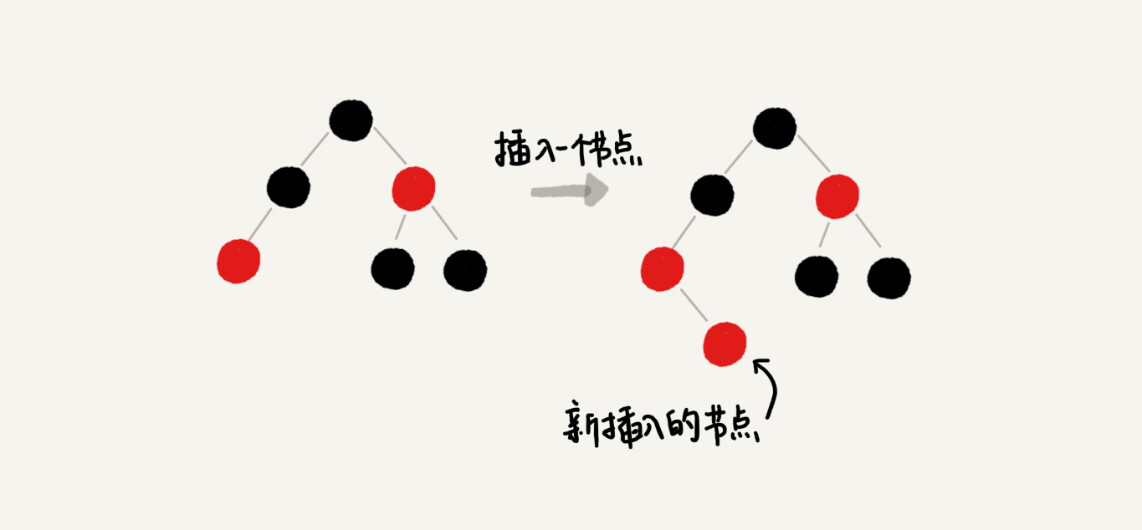
你会发现,这个时候,我们前面讲的插入时,三种情况下的平衡调整规则,没有一种是适用的。但是,如果我们把黑色的空节点都给它加上,变成下面这样,你会发现,它满足 CASE 2 了。
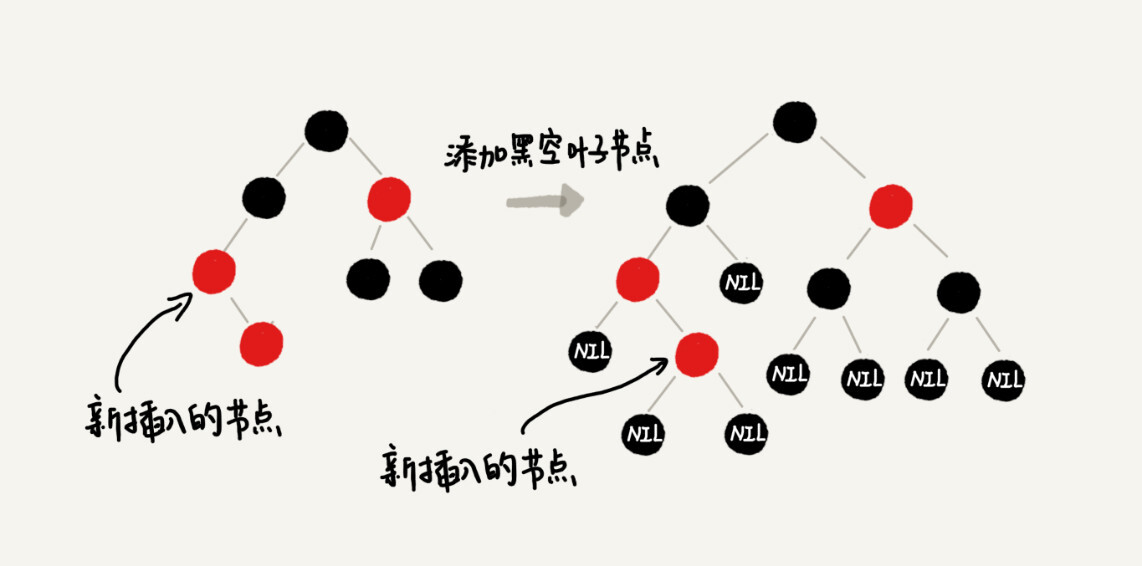
你可能会说,你可以调整一下平衡调整规则啊。比如把 CASE 2 改为“如果关注节点 a 的叔叔节点 b 是黑色或者不存在,a 是父节点的右子节点,就进行某某操作”。当然可以,但是这样的话规则就没有原来简洁了。
你可能还会说,这样给红黑树添加黑色的空的叶子节点,会不会比较浪费存储空间呢?答案是不会的。虽然我们在讲解或者画图的时候,每个黑色的、空的叶子节点都是独立画出来的。实际上,在具体实现的时候,我们只需要像下面这样,共用一个黑色的、空的叶子节点就行了。
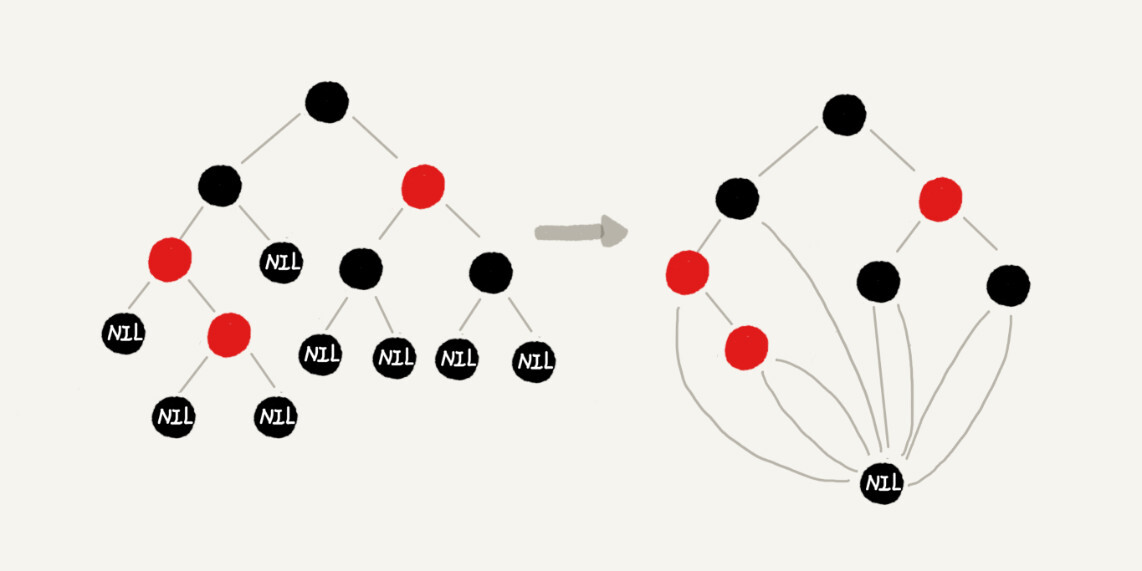
10.跳表
我们都知道二分查找算法,有它的局限性,具体可以参考文章。二分查找算法的局限性,主要体现在它需要连续存储结构,才能根据随机访问特性快速的实现二分,并且数组的内容必须是有序的。
那么,如果数据存储在链表中,就真的没法用二分查找算法了吗?
实际上,我们只需要对链表稍加改造,就可以支持类似“二分”的查找算法。我们把改造之后的数据结构叫作跳表(Skip list)。它确实是一种各方面性能都比较优秀的动态数据结构,可以支持快速的插入、删除、查找操作,写起来也不复杂,甚至可以替代红黑树(Red-black tree)。
10.1跳表的定义
对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。
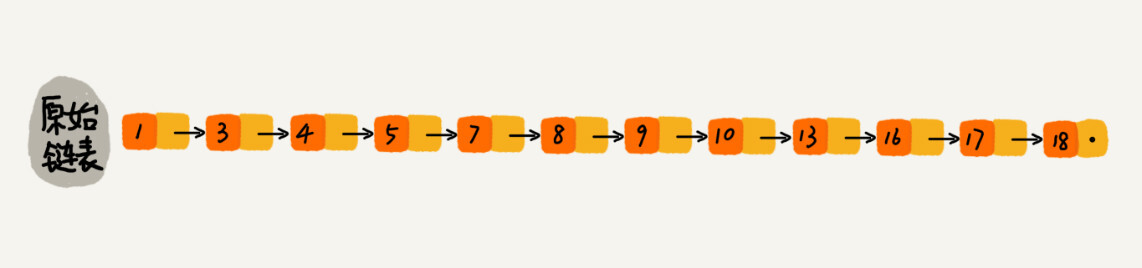
每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引或索引层。
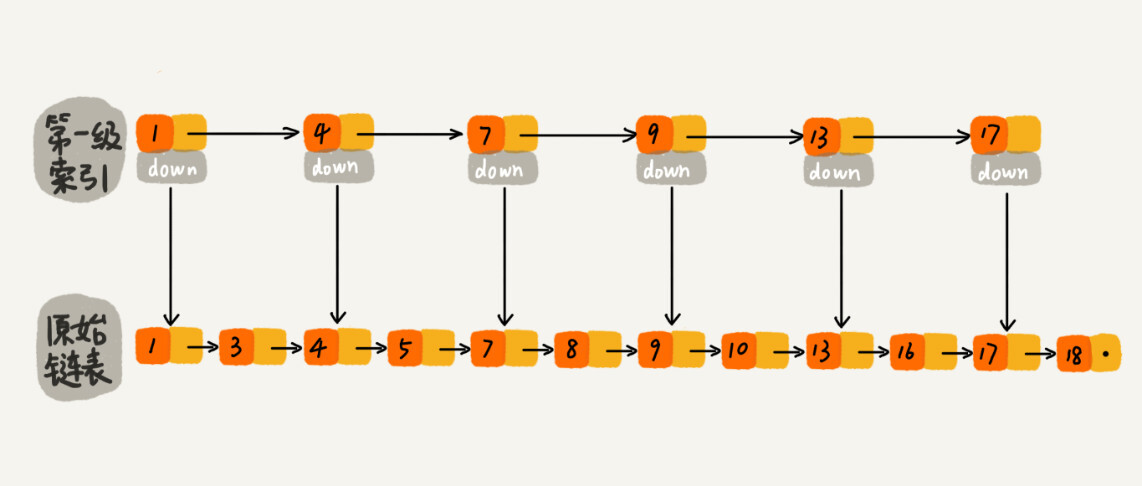
如果我们现在要查找某个结点,比如 16。我们可以先在索引层遍历,当遍历到索引层中值为 13 的结点时,我们发现下一个结点是 17,那要查找的结点 16 肯定就在这两个结点之间。然后我们通过索引层结点的 down 指针,下降到原始链表这一层,继续遍历。这个时候,我们只需要再遍历 2 个结点,就可以找到值等于 16 的这个结点了。这样,原来如果要查找 16,需要遍历 10 个结点,现在只需要遍历 7 个结点。
可以发现,加了一层索引之后,查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了,一般的,我们可以针对数据的规模来添加多层索引。前面讲的这种链表加多级索引的结构,就是跳表。
10.2复杂度分析
时间复杂度分析
如果链表里有 n 个结点,会有多少级索引呢?按照我们刚才讲的,每两个结点会抽出一个结点作为上一级索引的结点,那第一级索引的结点个数大约就是 n/2,第二级索引的结点个数大约就是 n/4,第三级索引的结点个数大约就是 n/8,依次类推,也就是说,第 k 级索引的结点个数是第 k-1 级索引的结点个数的 1/2,那第 k级索引结点的个数就是 n/(2^k)。假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2^h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。那这个 m 的值是多少呢?按照前面这种索引结构,我们每一级索引都最多只需要遍历 3 个结点,也就是说 m=3,为什么是 3 呢?我来解释一下。假设我们要查找的数据是 x,在第 k 级索引中,我们遍历到 y 结点之后,发现 x 大于 y,小于后面的结点 z,所以我们通过 y 的 down 指针,从第 k 级索引下降到第 k-1 级索引。在第 k-1 级索引中,y 和 z 之间只有 3 个结点(包含 y 和 z),所以,我们在 K-1 级索引中最多只需要遍历 3 个结点,依次类推,每一级索引都最多只需要遍历 3 个结点。
所以在跳表中查询任意数据的时间复杂度就是 O(logn)。这个查找的时间复杂度跟二分查找是一样的。换句话说,我们其实是基于单链表实现了二分查找,是不是很神奇!!!
但是它也不是十分完美,因为它的算法本质是通过空间来换时间,索引越多,空间复杂度越高。
空间复杂度分析
假设原始链表大小为 n,那第一级索引大约有 n/2 个结点,第二级索引大约有 n/4 个结点,以此类推,每上升一级就减少一半,直到剩下 2 个结点。如果我们把每层索引的结点数写出来,就是一个等比数列。
这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2。所以,跳表的空间复杂度是 O(n)。也就是说,如果将包含 n 个结点的单链表构造成跳表,我们需要额外再用接近 n 个结点的存储空间。
当然,这里的分析都是针对每两个结点抽一个结点到上级索引,这个间隔的结点个数并不是固定死的,如果把结点间隔扩大,那么空间复杂度也会相应的降低,但是时间复杂度肯定也会相应的提高。所以我们可以根据数据规模,使用场景需要来平衡时间和空间的效率,使得某一个特定场景拥有最大的时间空间效益。
参考资料