散列表和链表组合使用
LRU缓存淘汰算法
借助散列表,我们可以把LRU缓存淘汰算法的时间复杂度降为O(1)。
一个缓冲cache系统主要包含以下操作
- 往缓存中添加一个数据;
- 从缓存中删除一个数据;
- 在缓存中查找一个数据。
单纯采用链表,时间复杂度只能是O(n)。
将散列表和双向链表结合,就可以降为O(1),其结构如下图所示:
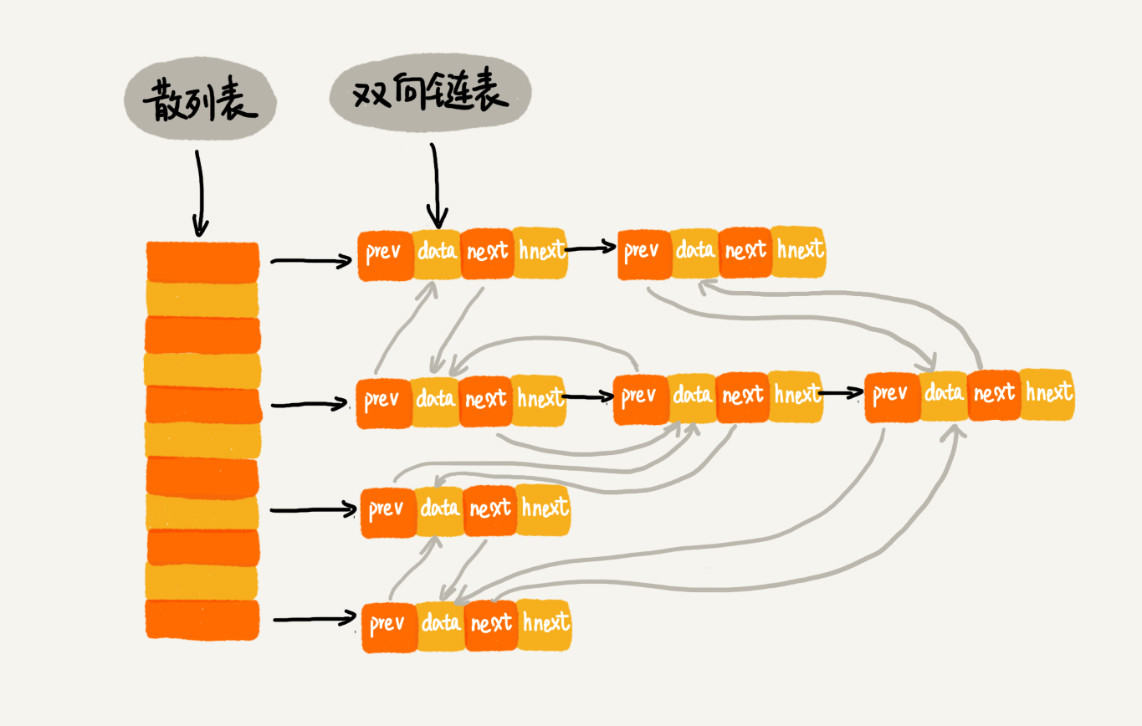
其中,我们使用双向链表存储数据,data存储数据,prev前驱指针,next后继指针。
此外,新增加了hnext指针,这个指针就是链表法散列表中的拉链的后继指针。
如何做到O(1)
查找
因为是散列表所以查找一个数据的操作时间复杂度就接近于O(1)。
删除
删除一个数据,我们借助散列表再O(1)的时间复杂度里找到该结点,
而双向链表有前驱指针,可以直接删除该节点,时间复杂度为O(1)。
添加
添加一个数据比较复杂,首先要看其是否已经在缓存中,
如果在就将其移动到双向链表的尾部,如果不在就检查缓存满了没,
满了就删除双向链表的头结点,再将数据放到双向链表的尾部,
如果没有满就直接将数据放大双向链表的尾部。
以上操作中,设计查找的操作是散列表完成的,删除节点、插入节点是双向链表完成的,所以时间复杂度是O(1)。
Redis有序集合
在有序集合中,每个成员对象有两个重要的属性,键key和分值score。
我们不仅需要key来查找数据,还会需要用score查找数据。
细化一下Redis有序集合的操作:
- 添加一个成员对象;
- 按照键值来删除一个成员对象;
- 按照键值来查找一个成员对象;
- 按照分值区间查找数据,比如查找积分在[100, 356] 之间的成员对象;
- 按照分值从小到大排序成员变量;
如果只按照分支将成员对象组织成跳表的结构,那么按照键值删除、查询对象就会很慢。
我们可以按照键值构建一个散列表,这样按照key来删除、查找一个对象的时间复杂度就都变成了O(1)。
Java中的LinkedHashMap
Jva中的LinkedHashMap中的Linked并不是链表法表示散列表的意思,而是双向链表和散列表结合。
LinkedHashMap本身就是一个支持LRU缓存淘汰策略的缓存系统,其数据的存取移动删除规则和LRU一样。
思考
今天讲的几个散列表和链表结合使用的例子里,我们用的都是双向链表。如果把双向链表改成单链表,还能否正常工作呢?为什么呢?
假设猎聘网有 10 万名猎头,每个猎头都可以通过做任务(比如发布职位)来积累积分,然后通过积分来下载简历。
假设你是猎聘网的一名工程师,如何在内存中存储这 10 万个猎头 ID 和积分信息,让它能够支持这样几个操作:
- 根据猎头的 ID 快速查找、删除、更新这个猎头的积分信息;
- 查找积分在某个区间的猎头 ID 列表;
- 查找按照积分从小到大排名在第 x 位到第 y 位之间的猎头 ...