DAG
中文名有向无环图。它不是spark独有技术。它是一种编程思想 ,甚至于hadoop阵营里也有运用DAG的技术,比如Tez,Oozie。有意思的是,Tez是从MapReduce的基础上深化而来的分布式计算框架。其核心思想是将Map和Reduce两个阶段分成更多的函数,各个函数之间可自由组合,形成DAG dependencies链,延迟计算。可见DAG思想适合多阶段的分布式计算,如果是MapReduce,Map本身就是InputStream,Reduce本身就是OutputStream,根本就不需要dependencies了。如果使用DAG思想反而得不偿失。
spark的算子分为两大类。一类是Transformation,一类是action。Transformation会在逻辑上将batch时间内的RDD形成一个DAG,然后在action触发后,在物理上通过dependencies回溯进行RDD的计算。
那么从RDD到DAG是怎样生成的呢?
DStream
RDD首先第一步要先变成DStream。
一个spark streaming程序首先要从数据源讲起,这里以kafka作为数据为例,通过以下代码可以得到一个InputDStream。
val inputDStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](ssc, kafkaParams, fromOffsets, messageHandler)
这是Driect的方式,也可以通过Reciver的方式得到ReceiverInputDStream,但是它本身也是继承自InputDStream。
val receiverInputDStream = KafkaUtils.createStream(ssc, kafkaParams, topics, storageLevel)
abstract class ReceiverInputDStream[T: ClassTag](_ssc: StreamingContext)
extends InputDStream[T](_ssc)
通过源码可以看到InputDStream继承自DStream。
abstract class InputDStream[T: ClassTag](_ssc: StreamingContext)
extends DStream[T](_ssc)
由此RDD变成了DStream。下面我们来仔细研究一下DStream究竟是个什么样子呢。
我们知道一个spark streaming处理逻辑包括接收数据(InputStream),处理数据(transformation和action),输出结果(OutputStream)。前面从RDD到DStream部份实际上就是接收数据部分。那么从DStream的角度来看看数据处理的部份。
从源码可以看到每个transformation算子都有对应的DStream实现类。比如map->MappedDStream,flatMap->FlatMappedDStream,filter->FilteredDStream。
// =======================================================================
// DStream operations
// =======================================================================
/** Return a new DStream by applying a function to all elements of this DStream. */
def map[U: ClassTag](mapFunc: T => U): DStream[U] = ssc.withScope {
new MappedDStream(this, context.sparkContext.clean(mapFunc))
}
/**
* Return a new DStream by applying a function to all elements of this DStream,
* and then flattening the results
*/
def flatMap[U: ClassTag](flatMapFunc: T => TraversableOnce[U]): DStream[U] = ssc.withScope {
new FlatMappedDStream(this, context.sparkContext.clean(flatMapFunc))
}
/** Return a new DStream containing only the elements that satisfy a predicate. */
def filter(filterFunc: T => Boolean): DStream[T] = ssc.withScope {
new FilteredDStream(this, context.sparkContext.clean(filterFunc))
}
我们以FilteredDStream为例,看看源码。可以看到两个关键属性:parent和dependencies。parent是一个DStream,而dependencies是一个DStream的集合。parent相当于指针,指向当前DStream的父级DStream,从而形成DAG图的一环。而dependencies则是当前DStream之前的所有DStream的集合。parent相当于在逻辑上表明各个DStream的关系,dependencies相当于在物理上表明整个DAG图的所有RDD集合,以便回溯计算。
package org.apache.spark.streaming.dstream
import scala.reflect.ClassTag
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Duration, Time}
private[streaming]
class FilteredDStream[T: ClassTag](
parent: DStream[T],
filterFunc: T => Boolean
) extends DStream[T](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[T]] = {
parent.getOrCompute(validTime).map(_.filter(filterFunc))
}
}
前面是transformation算子所形成的DStream,那么action算子所形成的DStream呢。事实上所有的action最终都只会形成ForEachDstream,因为不管是foreachRDD还是print还是saveAsObjectFiles,通过查看源码,会发现最终调用的还是foreachRDD。所以我们以我们以foreachRDD为例。


def saveAsObjectFiles(prefix: String, suffix: String = ""): Unit = ssc.withScope {
val saveFunc = (rdd: RDD[T], time: Time) => {
val file = rddToFileName(prefix, suffix, time)
rdd.saveAsObjectFile(file)
}
this.foreachRDD(saveFunc, displayInnerRDDOps = false)
}
/**
* Save each RDD in this DStream as at text file, using string representation
* of elements. The file name at each batch interval is generated based on
* `prefix` and `suffix`: "prefix-TIME_IN_MS.suffix".
*/
def saveAsTextFiles(prefix: String, suffix: String = ""): Unit = ssc.withScope {
val saveFunc = (rdd: RDD[T], time: Time) => {
val file = rddToFileName(prefix, suffix, time)
rdd.saveAsTextFile(file)
}
this.foreachRDD(saveFunc, displayInnerRDDOps = false)
}
def print(num: Int): Unit = ssc.withScope {
def foreachFunc: (RDD[T], Time) => Unit = {
(rdd: RDD[T], time: Time) => {
val firstNum = rdd.take(num + 1)
// scalastyle:off println
println("-------------------------------------------")
println(s"Time: $time")
println("-------------------------------------------")
firstNum.take(num).foreach(println)
if (firstNum.length > num) println("...")
println()
// scalastyle:on println
}
}
foreachRDD(context.sparkContext.clean(foreachFunc), displayInnerRDDOps = false)
}
/**
* Apply a function to each RDD in this DStream. This is an output operator, so
* 'this' DStream will be registered as an output stream and therefore materialized.
* @param foreachFunc foreachRDD function
* @param displayInnerRDDOps Whether the detailed callsites and scopes of the RDDs generated
* in the `foreachFunc` to be displayed in the UI. If `false`, then
* only the scopes and callsites of `foreachRDD` will override those
* of the RDDs on the display.
*/
private def foreachRDD(
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean): Unit = {
new ForEachDStream(this,
context.sparkContext.clean(foreachFunc, false), displayInnerRDDOps).register()
}
ForEachDStream和所有transformation算子的DStream一样,也有两个关键属性:parent和dependencies。同样的,parent相当于在逻辑上表明各个DStream的关系,dependencies相当于在物理上表明整个DAG图的所有RDD集合,以便回溯计算。但唯一不同的是,多了一个生成job的函数。这也不难理解,在action最后生成的ForEachDStream需要使用用户自定义的函数对结果进行输出。即是在这里进行。
package org.apache.spark.streaming.dstream
import scala.reflect.ClassTag
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Duration, Time}
import org.apache.spark.streaming.scheduler.Job
/**
* An internal DStream used to represent output operations like DStream.foreachRDD.
* @param parent Parent DStream
* @param foreachFunc Function to apply on each RDD generated by the parent DStream
* @param displayInnerRDDOps Whether the detailed callsites and scopes of the RDDs generated
* by `foreachFunc` will be displayed in the UI; only the scope and
* callsite of `DStream.foreachRDD` will be displayed.
*/
private[streaming]
class ForEachDStream[T: ClassTag] (
parent: DStream[T],
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean
) extends DStream[Unit](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[Unit]] = None
override def generateJob(time: Time): Option[Job] = {
parent.getOrCompute(time) match {
case Some(rdd) =>
val jobFunc = () => createRDDWithLocalProperties(time, displayInnerRDDOps) {
foreachFunc(rdd, time)
}
Some(new Job(time, jobFunc))
case None => None
}
}
}
那么现在就比较明了了,如下图。
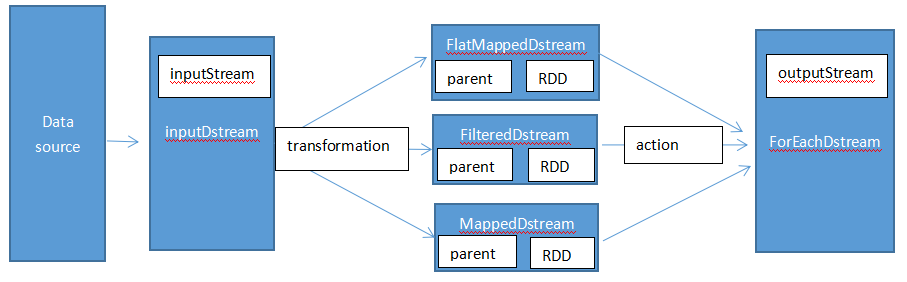
实际上,我们整个这一部份都是在讨论RDD怎样变成DStream。但是,这句话在表达上是有问题的,RDD表示弹性分布式数据集,它是不可变的。RDD真的是变成了DStream了吗?它们之间是什么关系呢?
实际上DStream是包含了RDD的数据集加指针。RDD还是没有变,它只是通过转换算子改变了形状。(Return a new DStream in which each RDD is generated by applying a function on each RDD of 'this' DStream.)。RDD仅包括数据。DStream得到对RDD数据集的引用,并反映了各个RDD所对应的DStream的逻辑顺序指针,以及当前批次(batch)的信息。
RDD = DStream at batch T
或者
DStream = RDD + dependencies + slideDuration
RDD和DStream的关系如下图

DStreamGraph
前面理解了RDD怎样形成了DStream,那么在整个batch里所有的操作包括数据输入,中间算子,结果输出产生的所有DStream是怎样串联在一起的呢?答案就是DStreamGraph 。
首先我们来看数据输入,即InputDstream。通过源码可以发现,它首先即是通过 DStreamGraph的addInputStream函数把数据保存在一个InputDStream的集合里。之所以是集合,表示可以接收多个数据源。
abstract class InputDStream[T: ClassTag](_ssc: StreamingContext) extends DStream[T](_ssc) ssc.graph.addInputStream(this) ================================= final private[streaming] class DStreamGraph extends Serializable with Logging private val inputStreams = new ArrayBuffer[InputDStream[_]]() def addInputStream(inputStream: InputDStream[_]) { this.synchronized { inputStream.setGraph(this) inputStreams += inputStream } }
然后在输出即OutputStram中,可以看到每个action算子对应的DStream,前面讲过,所有的action最终都会foreachRDD函数并得到ForEachDStream。在foreachRDD里会调用register函数,将此OutputDStream加入DStreamGraph。
abstract class DStream[T: ClassTag] ( @transient private[streaming] var ssc: StreamingContext ) extends Serializable with Logging private def foreachRDD( foreachFunc: (RDD[T], Time) => Unit, displayInnerRDDOps: Boolean): Unit = { new ForEachDStream(this, context.sparkContext.clean(foreachFunc, false), displayInnerRDDOps).register() } private[streaming] def register(): DStream[T] = { ssc.graph.addOutputStream(this) this } ========================== final private[streaming] class DStreamGraph extends Serializable with Logging def addOutputStream(outputStream: DStream[_]) { this.synchronized { outputStream.setGraph(this) outputStreams += outputStream } }
然后是中间的算子的DStream,阅读源码发现DStreamGraph并没有提供显示的将FilteredDstream或者MappedDstream加入的函数,比如类似于addOutputStream或者addInputStream的addDStream或者addFilteredDstream。那么,DStreamGraph是怎样将转换算子产生的DStream与首尾相连的呢?其实它只是使用parent便可以将全部的RDD使用dependencies串接了起来。在action的时候通过addOutputStream把ForEachDStream加入dependencies的同时,把dependencies也传递给了DStreamGraph。这样DStreamGraph就掌握了整个batch的DAG逻辑和物理图。
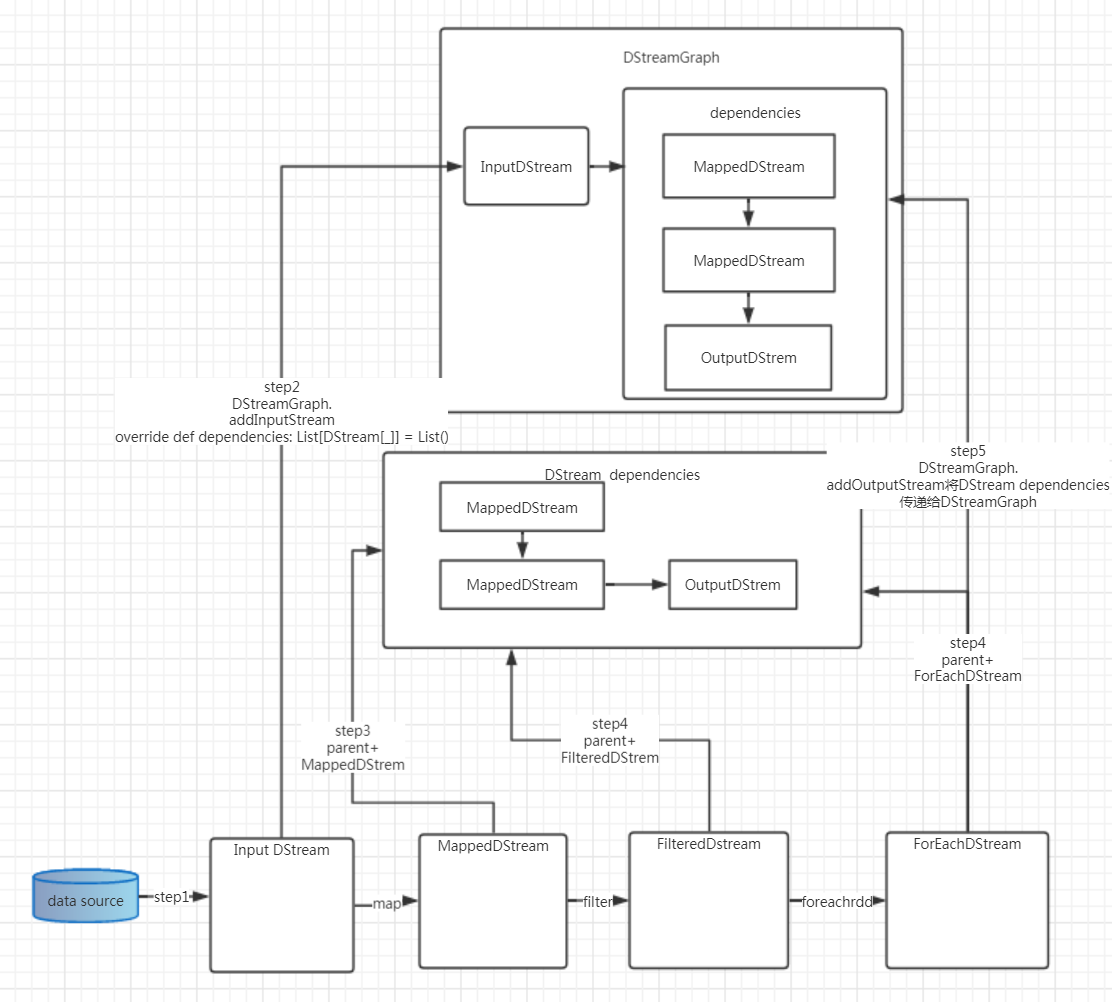
小结
step1 对接数据源,得到InputDStream。
step2 通过ssc.graph.addInputStream(this),将InputDStream加入DStreamGraph,并通过 override def dependencies: List[DStream[_]] = List()初始化依赖链dependencies。此时DStreamGraph持久有InputDStream。 此时DStream持有dependencies并为空。
step3 在Map算子中,通过override def dependencies: List[DStream[_]] = List(parent),将MappedDStream通过parent传入依赖链dependencies。此时DStream持有dependencies。dependencies = MappedDStream。
step4 在filter算子中,通过override def dependencies: List[DStream[_]] = List(parent),将FilteredDStream通过parent传入依赖链dependencies。此时DStream持有dependencies。
且dependencies =[ MappedDStream->FilteredDStream]。
step5 在action动作foreachRdd中,通过override def dependencies: List[DStream[_]] = List(parent),将ForEachDStream通过parent传入依赖链dependencies。此时DStream持有dependencies。
且dependencies =[ MappedDStream->FilteredDStream->ForEachDStream]。
step6 在ForEachDStream实例化过后通过register函数中 ssc.graph.addOutputStream(this)通过当前对象将依赖链dependencies传入DStreamGraph。此时DStreamGraph持久有InputDStream。 而且此时DStreamGraph拥有
dependencies。 且dependencies =[ MappedDStream->FilteredDStream->ForEachDStream]。
step7 DStreamGraph将InputDStream的dependencies整合。此时dependencies = [ InputDStream->MappedDStream->FilteredDStream->ForEachDStream]。即为DAG图。
格式原因,排版不是那么友好,图片可能更为清楚。

现在完成了DAG的静态链,形成了一个计算逻辑的模板。下一篇会探讨spark streaming如何在每个batch根据DAG模板动态生成相应的DAG实例,并提交job,执行。