https://www.cnblogs.com/herbert/archive/2013/01/07/2848892.html
os.walk(top, topdown = True, onerror = None, followlinks = False)
文件结构:
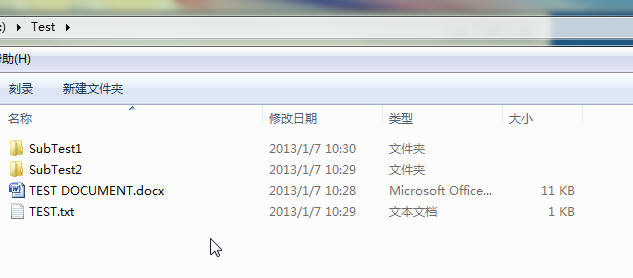
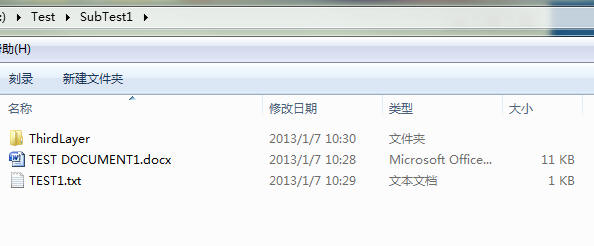
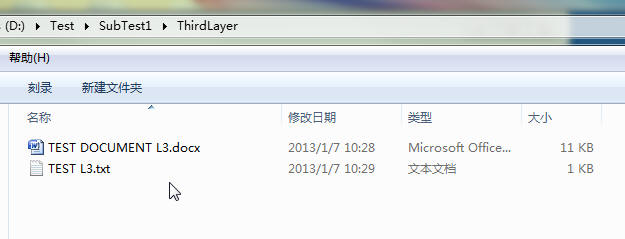
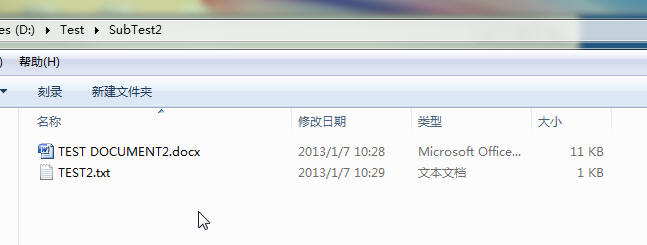
示例代码1:
import os
path = 'D:Test'
for root, dirs, files in os.walk(path):
print("Root = ", root, "dirs = ", dirs, "files = ", files)
结果:
| root | dirs | files |
|---|---|---|
| Root = D:Test | dirs = ['SubTest1', 'SubTest2'] | files = ['TEST DOCUMENT.docx', 'TEST.txt'] |
| Root = D:TestSubTest1 | dirs = ['ThirdLayer'] | files = ['TEST DOCUMENT1.docx', 'TEST1.txt'] |
| Root = D:TestSubTest1ThirdLayer | dirs = [] | files = ['TEST DOCUMENT L3.docx', 'TEST L3.txt'] |
| Root = D:TestSubTest2 | dirs = [] | files = ['TEST DOCUMENT2.docx', 'TEST2.txt'] |
结果分析:
1,先从根目录进行遍历,读取跟目录的文件夹和文件。
2,以根目录第一个子目录为新的根目录,读取其文件夹和文件。
3,再以2中的第一个子文件夹为根目录,读取文件夹和文件。(这个应该是属于树结构里面的自上而下深度遍历算法)
4,读取1步骤里面其他子目录的文件夹和文件。
示例代码2:(修改topdown 为False)
示例代码2:
import os
path = 'D:Test'
for root, dirs, files in os.walk(path, False):
print("Root = ", root, "dirs = ", dirs, "files = ", files)
结果:
| Root | dirs | files |
|---|---|---|
| Root = D:TestSubTest1ThirdLayer | dirs = [] | files = ['TEST DOCUMENT L3.docx', 'TEST L3.txt'] |
| Root = D:TestSubTest1 | dirs = ['ThirdLayer'] | files = ['TEST DOCUMENT1.docx', 'TEST1.txt'] |
| Root = D:TestSubTest2 | dirs = [] | files = ['TEST DOCUMENT2.docx', 'TEST2.txt'] |
| Root = D:Test | dirs = ['SubTest1', 'SubTest2'] | files = ['TEST DOCUMENT.docx', 'TEST.txt'] |
结果分析:
其实结果实质是一样的,不同的是,这次使用的是自下而上的深度遍历算法。
其他说明:
文件的全路径: 从上面的结果可以看出,文件的全路径,应该是os.path.join(root, files)
如果你要数路径下有多少个文件夹,其实很简单就是所有的root数目-1,因为root数目包含path文件夹。
如果以文件作为path路径会怎样? 返回空。
import os
path = 'D:TestTEST.txt'
for root, dirs, files in os.walk(path, False):
print("Root = ", root, "dirs = ", dirs, "files = ", files)
如果以一个不存在的文件夹为路径作为path会怎样?这里假定如果onerror = None,返回为空。
import os
path = 'D:Test1'
for root, dirs, files in os.walk(path, False):
print("Root = ", root, "dirs = ", dirs, "files = ", files)
https://blog.csdn.net/pursuit_zhangyu/article/details/79856226
walk()函数提供了可以遍历整个文件夹的功能,也就是说可以处理可以帮助我们高效的处理文件、目录方面的事情。
假设在你的工作目录下新建一个name文件夹,然后在name文件夹下新建3个.txt文件,分别为1.txt,2.txt,3.txt。
栗子1:
import os
files = 'name'
for walk in os.walk(files):
print(walk)
结果:
('name', [], ['1.txt', '2.txt', '3.txt'])
说明:
结果的3个值是代表下面的具体值
root 所指的是当前正在遍历的这个文件夹的本身的地址
dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
栗子2:
import os
files = 'name'
for walk in os.walk(files):
print(walk[2])
结果:
['1.txt', '2.txt', '3.txt']
栗子3:
import os
dir = 'D:\test'
#dir = r"D: est"
# count = 0
for parent, dirnames, filenames in os.walk(dir):
print(dirnames)
for filename in filenames:
print(filename)
fullpath = os.path.join(parent + '/', filename)
print(fullpath)