边阅边写
1.官方文档
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
逻辑回归,尽管名字带有“回归”,但它实际是一个分类模型而不是回归模型。在文献上,逻辑回归又称logit回归、最大熵分类或对数线性分类器。在这个模型中,使用逻辑函数对单次实验结果的可能性进行建模。
在scikit-learn中实施逻辑回归可以通过 LogisticRegression这个类。此实施可适用于二元、一对多或多远逻辑回归,并有可选的L2或L1正则化。
作为一个优化问题,二元类L2惩罚逻辑回归最小化以下成本函数:
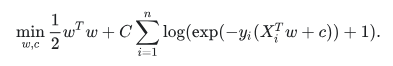
同样的,L1正则化逻辑回归解决一下优化问题:
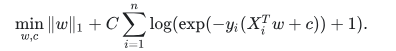
注意,在这种表示法中,是假设实验次数i的结果yi是在-1到1的集合中。
在LogisticRegression类中的求解器是“liblinear”, “newton-cg”, “lbfgs”, “sag” and “saga”这四个:
“liblinear”求解器使用坐标下降(CD)算法,并依赖于scikit-learn附带的优秀的C++ LIBLINEAR库。但是,在liblinear中的实现的CD算法无法学习真正的多项(多类)模型;相反,这个优化问题以一种“一对一”的方式分解,因此为所有类训练单独的二元分类器。这些操作发生在幕后,所以LogisticRegression实例使用这个求解器表现为多元分类器。对于L1惩罚,sklearn.svm.l1_min_c允许计算C的下界为了获得一个非空(所有特征权重为0)模型。
“lbfgs”, “sag” 和 “newton-cg”求解器只支持L2惩罚,而且发现对一些高维数据更快收敛。使用这些求解器设置multi_class为“multinomial”可以学习真正的多项回归模型,这意味着它的概率估计比默认的“一对一”设置更好地校准。
“sag” 求解器使用随机平均梯度下降,它在大样本维度多的大数据集中比其他求解器更快。
“saga”求解器是 “sag” 的变体,因此也支持无平滑惩罚L1选项,这个是稀疏多项逻辑会员的首选求解器。
“lbfgs”是一种近似于Broyden-Fletcher-Goldfarb-Shanno的优化算法,属于准牛顿算法。这个算法推荐适用于小数据集,在大数据集中性能会受到影响。
这下面的表格总结了每种求解器支持的惩罚:
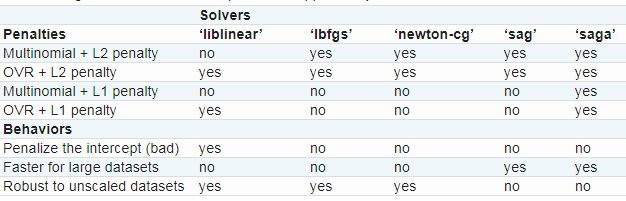
惩罚:
多项式+L2惩罚
一对一+L2惩罚
多项式+L1惩罚
一对一+L1惩罚
表现:
惩罚截距
在大数据集更快
在非标准数据集稳健
“lbfgs”由于稳健,在参数选项中是被默认的。对于大数据集,“saga” 求解器通常更快。对于大数据集,也可以考虑使用SGDClassifier对数损失,这个甚至会更快但需要更多调整。
** 举例 **
在逻辑回归中的L1惩罚和稀疏性
https://scikit-learn.org/stable/auto_examples/linear_model/plot_logistic_l1_l2_sparsity.html#sphx-glr-auto-examples-linear-model-plot-logistic-l1-l2-sparsity-py
L1-逻辑回归的回归路径
https://scikit-learn.org/stable/auto_examples/linear_model/plot_logistic_path.html#sphx-glr-auto-examples-linear-model-plot-logistic-path-py
绘制多项式和一对多逻辑回归
https://scikit-learn.org/stable/auto_examples/linear_model/plot_logistic_multinomial.html#sphx-glr-auto-examples-linear-model-plot-logistic-multinomial-py
多项稀疏逻辑回归在新组20中
https://scikit-learn.org/stable/auto_examples/linear_model/plot_sparse_logistic_regression_20newsgroups.html#sphx-glr-auto-examples-linear-model-plot-sparse-logistic-regression-20newsgroups-py
使用多项逻辑+L1的MNIST分类
** 与liblinear的不同 **
LogisticRegression使用solver=liblinear 或LinearSVC与外部liblinear库之间直接获得的分数可能存在差异,此时 fit_intercept=False拟合coef_(或)要预测的数据为零。这是因为对于具有decision_function零的样本 ,LogisticRegression并且LinearSVC 预测负类,而liblinear预测正类。请注意,fit_intercept=False具有decision_function零且具有多个样本 的模型可能是欠装,坏模型,建议您设置fit_intercept=True并增加intercept_scaling。
** 注意:使用稀疏逻辑回归进行特征选择 **
具有L1惩罚的逻辑回归产生稀疏模型,并且因此可以用于执行特征选择,如基于L1的特征选择中详述的 。
LogisticRegressionCV使用内置交叉验证实施逻辑回归以找到最优C参数。由于热启动,“newton-cg”, “sag”, “saga”和“lbfgs”求解器均被发现对于大数据集更快。对于多类情况,如果multi_class选项设置为“ovr”,则为每类获得最佳C;并且如果multi_class选项设置为“多选”,则通过最小化交叉熵损失来获得最优C。
** 参考文献 **
[5] Christopher M. Bishop:模式识别和机器学习,第4.3.4章
[6] Mark Schmidt,Nicolas Le Roux和Francis Bach:用随机平均梯度最小化有限和。
[7] Aaron Defazio,Francis Bach,Simon Lacoste-Julien:SAGA:一种支持非强凸复合目标的快速增量梯度法。
[8] https://en.wikipedia.org/wiki/Broyden%E2%80%93Fletcher%E2%80%93Goldfarb%E2%80%93Shanno_algorithm
[9] “Lbfgs与其他求解器的性能评估”
2.实例理解
https://blog.csdn.net/loveliuzz/article/details/78708359
LogisticRegressionCV文档
一个字母一个字母地重敲一遍代码
数据集:
http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/
后者在kaggle里找:
https://www.kaggle.com/uciml/breast-cancer-wisconsin-data/discussion