作者在Caffe中引入了一个新层,一般情况在Caffe中引入一个新层需要修改caffe.proto,添加该层头文件*.hpp,CPU实现*.cpp,GPU实现*.cu,代码结果如下图所示:

- caffe.proto
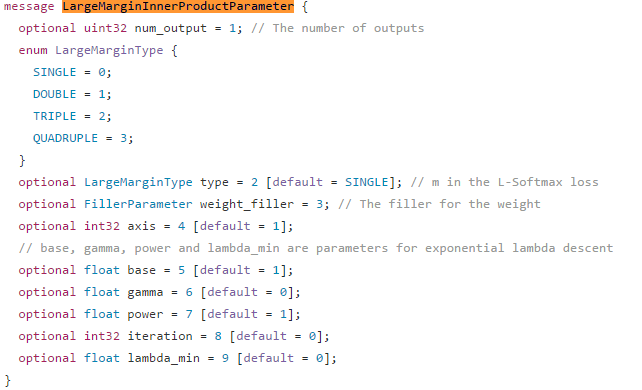
作者在caffe.proto中引入了largemargin_inner_product_laye层所需要的一些参数,例如num_output、type等,请注意一些参数有默认取值。
- largemargin_inner_product_laye.hpp
#ifndef CAFFE_LARGEMARGIN_INNER_PRODUCT_LAYER_HPP_ #define CAFFE_LARGEMARGIN_INNER_PRODUCT_LAYER_HPP_ #include <vector> #include "caffe/blob.hpp" #include "caffe/layer.hpp" #include "caffe/proto/caffe.pb.h" namespace caffe { /** * @brief Also known as a "LargeMargin fully-connected" layer, computes an LargeMargin inner product * with a set of learned weights, and (optionally) adds biases. * * TODO(dox): thorough documentation for Forward, Backward, and proto params. */ template <typename Dtype> class LargeMarginInnerProductLayer : public Layer<Dtype> { public: explicit LargeMarginInnerProductLayer(const LayerParameter& param) : Layer<Dtype>(param) {} virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); virtual void Reshape(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); virtual inline const char* type() const { return "LargeMarginInnerProduct"; } virtual inline int ExactNumBottomBlobs() const { return 2; } virtual inline int MaxTopBlobs() const { return 2; } protected: virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top); virtual void Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom); virtual void Backward_gpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom); int M_; int K_; int N_; LargeMarginInnerProductParameter_LargeMarginType type_; // common variables Blob<Dtype> x_norm_; Blob<Dtype> w_norm_; Blob<Dtype> cos_theta_; Blob<Dtype> sign_0_; // sign_0 = sign(cos_theta) // for DOUBLE type Blob<Dtype> cos_theta_quadratic_; // for TRIPLE type Blob<Dtype> sign_1_; // sign_1 = sign(abs(cos_theta) - 0.5) Blob<Dtype> sign_2_; // sign_2 = sign_0 * (1 + sign_1) - 2 Blob<Dtype> cos_theta_cubic_; // for QUADRA type Blob<Dtype> sign_3_; // sign_3 = sign_0 * sign(2 * cos_theta_quadratic_ - 1) Blob<Dtype> sign_4_; // sign_4 = 2 * sign_0 + sign_3 - 3 Blob<Dtype> cos_theta_quartic_; int iter_; Dtype lambda_; }; } // namespace caffe #endif // CAFFE_LARGEMARGIN_INNER_PRODUCT_LAYER_HPP_
作者在该头文件中遵循了“在caffe引入层的一般规范”,此外引入了一些变量。一些变量更具其命名,我们是可以大致猜出去含义的,如x_norm_,w_norm_。
- largemargin_inner_product_laye.cpp
由于该部分代码较多,因此笔者采取函数注释的方式进行分析(只要分析type=DOUBLE的情形)
#include <vector> #include "caffe/blob.hpp" #include "caffe/common.hpp" #include "caffe/filler.hpp" #include "caffe/layer.hpp" #include "caffe/util/math_functions.hpp" #include "caffe/layers/largemargin_inner_product_layer.hpp" namespace caffe { //该函数主要完成参数赋值、weight Blob初始化 template <typename Dtype> void LargeMarginInnerProductLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { CHECK_EQ(bottom[0]->num(), bottom[1]->num()) << "Number of labels must match number of output; " << "DO NOT support multi-label this version." << "e.g., if prediction shape is (M X N), " << "label count (number of labels) must be M, " << "with integer values in {0, 1, ..., N-1}."; type_ = this->layer_param_.largemargin_inner_product_param().type(); iter_ = this->layer_param_.largemargin_inner_product_param().iteration(); lambda_ = (Dtype)0.; const int num_output = this->layer_param_.largemargin_inner_product_param().num_output(); N_ = num_output; const int axis = bottom[0]->CanonicalAxisIndex( this->layer_param_.largemargin_inner_product_param().axis()); K_ = bottom[0]->count(axis); // Check if we need to set up the weights if (this->blobs_.size() > 0) { LOG(INFO) << "Skipping parameter initialization"; } else { this->blobs_.resize(1); // Intialize the weight vector<int> weight_shape(2); weight_shape[0] = N_; weight_shape[1] = K_; this->blobs_[0].reset(new Blob<Dtype>(weight_shape));//weight维度为(N_,K_) // fill the weights shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>( this->layer_param_.largemargin_inner_product_param().weight_filler())); weight_filler->Fill(this->blobs_[0].get()); } // parameter initialization this->param_propagate_down_.resize(this->blobs_.size(), true);//weight大小设置以及初始化 } template <typename Dtype> void LargeMarginInnerProductLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { // Figure out the dimensions const int axis = bottom[0]->CanonicalAxisIndex( this->layer_param_.largemargin_inner_product_param().axis()); const int new_K = bottom[0]->count(axis); CHECK_EQ(K_, new_K) << "Input size incompatible with inner product parameters."; M_ = bottom[0]->count(0, axis);//单个样本输出维度N_,样本数M_,单个样本维度K_,请记住这三个参数的含义 vector<int> top_shape = bottom[0]->shape(); top_shape.resize(axis + 1); top_shape[axis] = N_; top[0]->Reshape(top_shape);//top的维度(M_,N_) // if needed, reshape top[1] to output lambda vector<int> lambda_shape(1, 1); top[1]->Reshape(lambda_shape);//为了加速收敛引入了指数退化项lambda // common variables vector<int> shape_1_X_M(1, M_); x_norm_.Reshape(shape_1_X_M);//norm{xi},i属于[0,M_-1] vector<int> shape_1_X_N(1, N_); w_norm_.Reshape(shape_1_X_N);//norm{wi},i属于[0,N_-1] sign_0_.Reshape(top_shape); cos_theta_.Reshape(top_shape);//cos(theta)的维度(M_,N_) // optional temp variables switch (type_) { case LargeMarginInnerProductParameter_LargeMarginType_SINGLE: break; case LargeMarginInnerProductParameter_LargeMarginType_DOUBLE: cos_theta_quadratic_.Reshape(top_shape);//cos(theta)^2的维度(M_,N_) break; case LargeMarginInnerProductParameter_LargeMarginType_TRIPLE: cos_theta_quadratic_.Reshape(top_shape); cos_theta_cubic_.Reshape(top_shape); sign_1_.Reshape(top_shape); sign_2_.Reshape(top_shape); break; case LargeMarginInnerProductParameter_LargeMarginType_QUADRUPLE: cos_theta_quadratic_.Reshape(top_shape); cos_theta_cubic_.Reshape(top_shape); cos_theta_quartic_.Reshape(top_shape); sign_3_.Reshape(top_shape); sign_4_.Reshape(top_shape); break; default: LOG(FATAL) << "Unknown L-Softmax type."; } } template <typename Dtype> void LargeMarginInnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { iter_ += (Dtype)1.; Dtype base_ = this->layer_param_.largemargin_inner_product_param().base(); Dtype gamma_ = this->layer_param_.largemargin_inner_product_param().gamma(); Dtype power_ = this->layer_param_.largemargin_inner_product_param().power(); Dtype lambda_min_ = this->layer_param_.largemargin_inner_product_param().lambda_min(); lambda_ = base_ * pow(((Dtype)1. + gamma_ * iter_), -power_); lambda_ = std::max(lambda_, lambda_min_); top[1]->mutable_cpu_data()[0] = lambda_;//指数退化项,iter_很大时,lambda_趋于0 /************************* common variables *************************/ const Dtype* bottom_data = bottom[0]->cpu_data(); Dtype* mutable_x_norm_data = x_norm_.mutable_cpu_data(); for (int i = 0; i < M_; i++) { mutable_x_norm_data[i] = sqrt(caffe_cpu_dot(K_, bottom_data + i * K_, bottom_data + i * K_));//norm{xi}计算,i属于M_ } const Dtype* weight = this->blobs_[0]->cpu_data(); Dtype* mutable_w_norm_data = w_norm_.mutable_cpu_data(); for (int i = 0; i < N_; i++) { mutable_w_norm_data[i] = sqrt(caffe_cpu_dot(K_, weight + i * K_, weight + i * K_));//norm{wi}计算,i属于N_ } Blob<Dtype> xw_norm_product_; xw_norm_product_.Reshape(cos_theta_.shape()); caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, M_, N_, 1, (Dtype)1., x_norm_.cpu_data(), w_norm_.cpu_data(), (Dtype)0., xw_norm_product_.mutable_cpu_data());//norm{wi}乘以norm{xj},输出维度为(M_,N_) caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, (Dtype)1., bottom_data, weight, (Dtype)0., cos_theta_.mutable_cpu_data()); caffe_add_scalar(M_ * N_, (Dtype)0.000000001, xw_norm_product_.mutable_cpu_data());//防止分母为0 caffe_div(M_ * N_, cos_theta_.cpu_data(), xw_norm_product_.cpu_data(), cos_theta_.mutable_cpu_data());//cos(theta),输出维度为(M_,N_) caffe_cpu_sign(M_ * N_, cos_theta_.cpu_data(), sign_0_.mutable_cpu_data()); switch (type_) { case LargeMarginInnerProductParameter_LargeMarginType_SINGLE: break; case LargeMarginInnerProductParameter_LargeMarginType_DOUBLE: caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., cos_theta_quadratic_.mutable_cpu_data());//cos(theta)^2,输出维度为(M_,N_) break; case LargeMarginInnerProductParameter_LargeMarginType_TRIPLE: caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., cos_theta_quadratic_.mutable_cpu_data()); caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)3., cos_theta_cubic_.mutable_cpu_data()); caffe_abs(M_ * N_, cos_theta_.cpu_data(), sign_1_.mutable_cpu_data()); caffe_add_scalar(M_ * N_, -(Dtype)0.5, sign_1_.mutable_cpu_data()); caffe_cpu_sign(M_ * N_, sign_1_.cpu_data(), sign_1_.mutable_cpu_data()); caffe_copy(M_ * N_, sign_1_.cpu_data(), sign_2_.mutable_cpu_data()); caffe_add_scalar(M_ * N_, (Dtype)1., sign_2_.mutable_cpu_data()); caffe_mul(M_ * N_, sign_0_.cpu_data(), sign_2_.cpu_data(), sign_2_.mutable_cpu_data()); caffe_add_scalar(M_ * N_, - (Dtype)2., sign_2_.mutable_cpu_data()); break; case LargeMarginInnerProductParameter_LargeMarginType_QUADRUPLE: caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)2., cos_theta_quadratic_.mutable_cpu_data()); caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)3., cos_theta_cubic_.mutable_cpu_data()); caffe_powx(M_ * N_, cos_theta_.cpu_data(), (Dtype)4., cos_theta_quartic_.mutable_cpu_data()); caffe_copy(M_ * N_, cos_theta_quadratic_.cpu_data(), sign_3_.mutable_cpu_data()); caffe_scal(M_ * N_, (Dtype)2., sign_3_.mutable_cpu_data()); caffe_add_scalar(M_ * N_, (Dtype)-1., sign_3_.mutable_cpu_data()); caffe_cpu_sign(M_ * N_, sign_3_.cpu_data(), sign_3_.mutable_cpu_data()); caffe_mul(M_ * N_, sign_0_.cpu_data(), sign_3_.cpu_data(), sign_3_.mutable_cpu_data()); caffe_copy(M_ * N_, sign_0_.cpu_data(), sign_4_.mutable_cpu_data()); caffe_scal(M_ * N_, (Dtype)2., sign_4_.mutable_cpu_data()); caffe_add(M_ * N_, sign_4_.cpu_data(), sign_3_.cpu_data(), sign_4_.mutable_cpu_data()); caffe_add_scalar(M_ * N_, - (Dtype)3., sign_4_.mutable_cpu_data()); break; default: LOG(FATAL) << "Unknown L-Softmax type."; } /************************* Forward *************************/ Dtype* top_data = top[0]->mutable_cpu_data(); caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, (Dtype)1., bottom_data, weight, (Dtype)0., top_data);//top = XW’,X为bottom data维度为(M_,K_),W'为权重矩阵、维度为(K_,N_) const Dtype* label = bottom[1]->cpu_data(); const Dtype* xw_norm_product_data = xw_norm_product_.cpu_data(); switch (type_) { case LargeMarginInnerProductParameter_LargeMarginType_SINGLE: { break; } case LargeMarginInnerProductParameter_LargeMarginType_DOUBLE: { const Dtype* sign_0_data = sign_0_.cpu_data(); const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data(); for (int i = 0; i < M_; i++) { const int label_value = static_cast<int>(label[i]); top_data[i * N_ + label_value] = xw_norm_product_data[i * N_ + label_value] * ((Dtype)2. * sign_0_data[i * N_ + label_value] * cos_theta_quadratic_data[i * N_ + label_value] - (Dtype)1.); }//修改样本i对应label的输出(请参考论文) caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, lambda_, bottom_data, weight, (Dtype)1., top_data);//引入lambda_,加速收敛 caffe_scal(M_ * N_, (Dtype)1./((Dtype)1. + lambda_), top_data); break;//上述两个操作参考原始论文很好理解 } case LargeMarginInnerProductParameter_LargeMarginType_TRIPLE: { const Dtype* sign_1_data = sign_1_.cpu_data(); const Dtype* sign_2_data = sign_2_.cpu_data(); const Dtype* cos_theta_data = cos_theta_.cpu_data(); const Dtype* cos_theta_cubic_data = cos_theta_cubic_.cpu_data(); for (int i = 0; i < M_; i++) { const int label_value = static_cast<int>(label[i]); top_data[i * N_ + label_value] = xw_norm_product_data[i * N_ + label_value] * (sign_1_data[i * N_ + label_value] * ((Dtype)4. * cos_theta_cubic_data[i * N_ + label_value] - (Dtype)3. * cos_theta_data[i * N_ + label_value]) + sign_2_data[i * N_ + label_value]); } caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, lambda_, bottom_data, weight, (Dtype)1., top_data); caffe_scal(M_ * N_, (Dtype)1./((Dtype)1. + lambda_), top_data); break; } case LargeMarginInnerProductParameter_LargeMarginType_QUADRUPLE: { const Dtype* sign_3_data = sign_3_.cpu_data(); const Dtype* sign_4_data = sign_4_.cpu_data(); const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data(); const Dtype* cos_theta_quartic_data = cos_theta_quartic_.cpu_data(); for (int i = 0; i < M_; i++) { const int label_value = static_cast<int>(label[i]); top_data[i * N_ + label_value] = xw_norm_product_data[i * N_ + label_value] * (sign_3_data[i * N_ + label_value] * ((Dtype)8. * cos_theta_quartic_data[i * N_ + label_value] - (Dtype)8. * cos_theta_quadratic_data[i * N_ + label_value] + (Dtype)1.) + sign_4_data[i * N_ + label_value]); } caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, lambda_, bottom_data, weight, (Dtype)1., top_data); caffe_scal(M_ * N_, (Dtype)1./((Dtype)1. + lambda_), top_data); break; } default: { LOG(FATAL) << "Unknown L-Softmax type."; } } } //在反向传播中,我只简单介绍一下核心的误差传递,忽略导数的计算公式分析。计算公式参考论文是很好理解的 template <typename Dtype> void LargeMarginInnerProductLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) { Blob<Dtype> inv_w_norm_; inv_w_norm_.Reshape(w_norm_.shape()); Blob<Dtype> xw_norm_ratio_; xw_norm_ratio_.Reshape(cos_theta_.shape()); caffe_add_scalar(N_, (Dtype)0.000000001, w_norm_.mutable_cpu_data()); caffe_set(N_, (Dtype)1., inv_w_norm_.mutable_cpu_data()); caffe_div(N_, inv_w_norm_.cpu_data(), w_norm_.cpu_data(), inv_w_norm_.mutable_cpu_data()); caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, M_, N_, 1, (Dtype)1., x_norm_.cpu_data(), inv_w_norm_.cpu_data(), (Dtype)0., xw_norm_ratio_.mutable_cpu_data()); const Dtype* top_diff = top[0]->cpu_diff(); const Dtype* bottom_data = bottom[0]->cpu_data(); const Dtype* label = bottom[1]->cpu_data(); const Dtype* weight = this->blobs_[0]->cpu_data(); if (this->param_propagate_down_[0]) { Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff();//请注意:weight和weight_diff含义不同 const Dtype* xw_norm_ratio_data = xw_norm_ratio_.cpu_data(); switch (type_) { case LargeMarginInnerProductParameter_LargeMarginType_SINGLE: { caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, N_, K_, M_, (Dtype)1., top_diff, bottom_data, (Dtype)1., this->blobs_[0]->mutable_cpu_diff()); break; } case LargeMarginInnerProductParameter_LargeMarginType_DOUBLE: { const Dtype* sign_0_data = sign_0_.cpu_data(); const Dtype* cos_theta_data = cos_theta_.cpu_data(); const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data(); for (int i = 0; i < N_; i++) { for (int j = 0; j < M_; j++) {// dL/dwij = sum{dL/dfni*dfni/dwij},求和范围n属于[0,M_) const int label_value = static_cast<int>(label[j]); if (label_value != i) { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[j * N_ + i], bottom_data + j * K_, (Dtype)1., weight_diff + i * K_); } else { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[j * N_ + i] * (Dtype)4. * sign_0_data[j * N_ + i] * cos_theta_data[j * N_ + i], bottom_data + j * K_, (Dtype)1., weight_diff + i * K_); caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[j * N_ + i] * (-xw_norm_ratio_data[j * N_ + i]) * ((Dtype)2. * sign_0_data[j * N_ + i] * cos_theta_quadratic_data[j * N_ + i] + (Dtype)1.), weight + i * K_, (Dtype)1., weight_diff + i * K_); } } } caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, N_, K_, M_, lambda_/((Dtype)1. + lambda_), top_diff, bottom_data, (Dtype)1., this->blobs_[0]->mutable_cpu_diff()); break; } case LargeMarginInnerProductParameter_LargeMarginType_TRIPLE: { const Dtype* sign_1_data = sign_1_.cpu_data(); const Dtype* sign_2_data = sign_2_.cpu_data(); const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data(); const Dtype* cos_theta_cubic_data = cos_theta_cubic_.cpu_data(); for (int i = 0; i < N_; i++) { for (int j = 0; j < M_; j++) { const int label_value = static_cast<int>(label[j]); if (label_value != i) { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[j * N_ + i], bottom_data + j * K_, (Dtype)1., weight_diff + i * K_); } else { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[j * N_ + i] * sign_1_data[j * N_ + i] * ((Dtype)12. * cos_theta_quadratic_data[j * N_ + i] - (Dtype)3.), bottom_data + j * K_, (Dtype)1., weight_diff + i * K_); caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[j * N_ + i] * (-xw_norm_ratio_data[j * N_ + i]) * ((Dtype)8. * sign_1_data[j * N_ + i] * cos_theta_cubic_data[j * N_ + i] - sign_2_data[j * N_ + i]), weight + i * K_, (Dtype)1., weight_diff + i * K_); } } } caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, N_, K_, M_, lambda_/((Dtype)1. + lambda_), top_diff, bottom_data, (Dtype)1., this->blobs_[0]->mutable_cpu_diff()); break; } case LargeMarginInnerProductParameter_LargeMarginType_QUADRUPLE: { const Dtype* sign_3_data = sign_3_.cpu_data(); const Dtype* sign_4_data = sign_4_.cpu_data(); const Dtype* cos_theta_data = cos_theta_.cpu_data(); const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data(); const Dtype* cos_theta_cubic_data = cos_theta_cubic_.cpu_data(); const Dtype* cos_theta_quartic_data = cos_theta_quartic_.cpu_data(); for (int i = 0; i < N_; i++) { for (int j = 0; j < M_; j++) { const int label_value = static_cast<int>(label[j]); if (label_value != i) { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[j * N_ + i], bottom_data + j * K_, (Dtype)1., weight_diff + i * K_); } else { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[j * N_ + i] * sign_3_data[j * N_ + i] * ((Dtype)32. * cos_theta_cubic_data[j * N_ + i] - (Dtype)16. * cos_theta_data[j * N_ + i]), bottom_data + j * K_, (Dtype)1., weight_diff + i * K_); caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[j * N_ + i] * (-xw_norm_ratio_data[j * N_ + i]) * (sign_3_data[j * N_ + i] * ((Dtype)24. * cos_theta_quartic_data[j * N_ + i] - (Dtype)8. * cos_theta_quadratic_data[j * N_ + i] - (Dtype)1.) - sign_4_data[j * N_ + i]), weight + i * K_, (Dtype)1., weight_diff + i * K_); } } } caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, N_, K_, M_, lambda_/((Dtype)1. + lambda_), top_diff, bottom_data, (Dtype)1., this->blobs_[0]->mutable_cpu_diff()); break; } default: { LOG(FATAL) << "Unknown L-Softmax type."; } } } // Gradient with respect to bottom data if (propagate_down[0]) { Dtype* bottom_diff = bottom[0]->mutable_cpu_diff(); const Dtype* xw_norm_ratio_data = xw_norm_ratio_.cpu_data(); caffe_set(M_ * K_, (Dtype)0., bottom_diff); switch (type_) { case LargeMarginInnerProductParameter_LargeMarginType_SINGLE: { caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, (Dtype)1., top_diff, this->blobs_[0]->cpu_data(), (Dtype)0., bottom[0]->mutable_cpu_diff()); break; } case LargeMarginInnerProductParameter_LargeMarginType_DOUBLE: { const Dtype* sign_0_data = sign_0_.cpu_data(); const Dtype* cos_theta_data = cos_theta_.cpu_data(); const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data(); for (int i = 0; i < M_; i++) { const int label_value = static_cast<int>(label[i]); for (int j = 0; j < N_; j++) {// dL/dxij = sum{dL/dfin*dfin/dxij},求和范围n属于[0,N_) if (label_value != j) { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j], weight + j * K_, (Dtype)1., bottom_diff + i * K_); } else { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * (Dtype)4. * sign_0_data[i * N_ + j] * cos_theta_data[i * N_ + j], weight + j * K_, (Dtype)1., bottom_diff + i * K_); caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] / (-xw_norm_ratio_data[i * N_ + j]) * ((Dtype)2. * sign_0_data[i * N_ + j] * cos_theta_quadratic_data[i * N_ + j] + (Dtype)1.), bottom_data + i * K_, (Dtype)1., bottom_diff + i * K_); } } } caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, lambda_/((Dtype)1. + lambda_), top_diff, this->blobs_[0]->cpu_data(), (Dtype)1., bottom[0]->mutable_cpu_diff()); break; } case LargeMarginInnerProductParameter_LargeMarginType_TRIPLE: { const Dtype* sign_1_data = sign_1_.cpu_data(); const Dtype* sign_2_data = sign_2_.cpu_data(); const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data(); const Dtype* cos_theta_cubic_data = cos_theta_cubic_.cpu_data(); for (int i = 0; i < M_; i++) { const int label_value = static_cast<int>(label[i]); for (int j = 0; j < N_; j++) { if (label_value != j) { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j], weight + j * K_, (Dtype)1., bottom_diff + i * K_); } else { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * sign_1_data[i * N_ + j] * ((Dtype)12. * cos_theta_quadratic_data[i * N_ + j] - (Dtype)3.), weight + j * K_, (Dtype)1., bottom_diff + i * K_); caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] / (-xw_norm_ratio_data[i * N_ + j]) * ((Dtype)8. * sign_1_data[i * N_ + j] * cos_theta_cubic_data[i * N_ + j] - sign_2_data[i * N_ +j]), bottom_data + i * K_, (Dtype)1., bottom_diff + i * K_); } } } caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, lambda_/((Dtype)1. + lambda_), top_diff, this->blobs_[0]->cpu_data(), (Dtype)1., bottom[0]->mutable_cpu_diff()); break; } case LargeMarginInnerProductParameter_LargeMarginType_QUADRUPLE: { const Dtype* sign_3_data = sign_3_.cpu_data(); const Dtype* sign_4_data = sign_4_.cpu_data(); const Dtype* cos_theta_data = cos_theta_.cpu_data(); const Dtype* cos_theta_quadratic_data = cos_theta_quadratic_.cpu_data(); const Dtype* cos_theta_cubic_data = cos_theta_cubic_.cpu_data(); const Dtype* cos_theta_quartic_data = cos_theta_quartic_.cpu_data(); for (int i = 0; i < M_; i++) { const int label_value = static_cast<int>(label[i]); for (int j = 0; j < N_; j++) { if (label_value != j) { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j], weight + j * K_, (Dtype)1., bottom_diff + i * K_); } else { caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] * sign_3_data[i * N_ + j] * ((Dtype)32. * cos_theta_cubic_data[i * N_ + j] - (Dtype)16. * cos_theta_data[i * N_ + j]), weight + j * K_, (Dtype)1., bottom_diff + i * K_); caffe_cpu_axpby(K_, (Dtype)1. / ((Dtype)1. + lambda_) * top_diff[i * N_ + j] / (-xw_norm_ratio_data[i * N_ + j]) * (sign_3_data[i * N_ + j] * ((Dtype)24. * cos_theta_quartic_data[i * N_ + j] - (Dtype)8. * cos_theta_quadratic_data[i * N_ + j] - (Dtype)1.) - sign_4_data[i * N_ + j]), bottom_data + i * K_, (Dtype)1., bottom_diff + i * K_); } } } caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, lambda_/((Dtype)1. + lambda_), top_diff, this->blobs_[0]->cpu_data(), (Dtype)1., bottom[0]->mutable_cpu_diff()); break; } default: { LOG(FATAL) << "Unknown L-Softmax type."; } } } } #ifdef CPU_ONLY STUB_GPU(LargeMarginInnerProductLayer); #endif INSTANTIATE_CLASS(LargeMarginInnerProductLayer); REGISTER_LAYER_CLASS(LargeMarginInnerProduct); } // namespace caffe
反向传播时我只示例性的展示了链式法则(有d代表偏导符号∂了)。如果大家觉得lambda碍事,可以直接认为其值为0,这样能够简化我们的理解。
GPU实现部分原理应该差不多,只是实现方式有所差异,这里我就不进行分析了。大家可以参考这篇说明理解这篇论文的基本原理https://mp.weixin.qq.com/s?__biz=MzA3Mjk0OTgyMg==&mid=2651123524&idx=1&sn=0546ceca3d88e2ff1e66fbecc99bd6a7&chksm=84e6c615b3914f03bec98f22eefb00da5b30a82866c068cc4045e3ee9d0a31366f2f8bb5fec1&scene=0&ptlang=2052&source&ADUIN=1184611233&ADSESSION=1496371074&ADTAG=CLIENT.QQ.5527_.0&ADPUBNO=26632#rd
总结:通过阅读源码,我明白了链式法则在程序中是如何运用的,也学到了一个加速网络收敛的技巧(即引入指数退化项)。