一、 引子
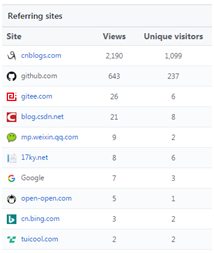
首先感谢博客园:第一篇文章、第一个开源项目,算是旗开得胜。可以看到,项目大部分流量来自于博客园,码农乐园,名不虚传^^。
园友给了我很多支持,并提出了很好的改进意见。现加入屏幕分辨率自适应和OPC Server可CLSID和ProgID自适应加载功能。屏幕自适应本是普遍问题,因为之前都是标配硬件,举手之劳,一懒就忽略了。
仅仅十天前,我还是上github只会点击 的菜鸟。Readme文件如何编辑都是现学现卖。
的菜鸟。Readme文件如何编辑都是现学现卖。
第一次向github上传仓库,下载了发现居然没有任何exe,dll,bak文件!度之,更改忽略文件。总之是赶鸭子上架,各种囧。
然则有园友捧场,我也就不揣浅陋,以见教于大方了。
二、 如何加入一个新驱动
- 准备工作
我更新了dll文件夹:增加了libnodave.dll、libnodave.net.dll、SiemensPLCDriver.dll。这个SiemensPLCDriver.dll,
就是西门子S7系列PLC的驱动程序(包括源代码,在Program里面)。请先同步或者重新下载最新版本。
libnodave开源库(https://github.com/netdata/libnodave)据说是来自西门子的德国大神所作。某前辈当年一句话:能搞定驱动就是大牛。我找到了libnodave,封装后成功的实现了与西门子200PLC通讯,很受鼓舞,也成为了项目的起点。
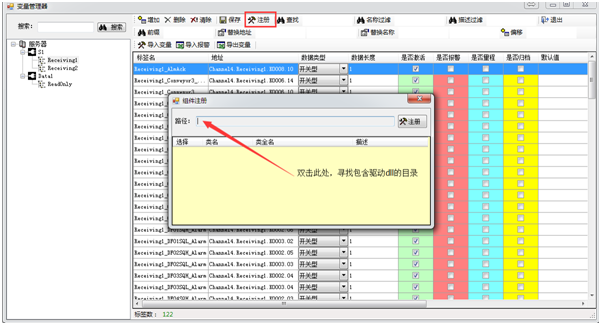
- 注册驱动
打开变量管理器TagConfig,点注册,双击【路径】框,在dll文件夹里找到SiemensPLCDriver.dll。
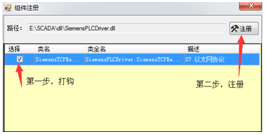
如果出现在下方列表,打钩,点注册,一般会提示成功。
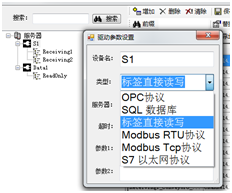
这时候,右键点树节点S1->参数设置,就会看到S7以太网协议已经成为可选项。
- 驱动的加载
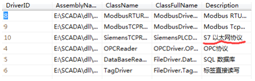
实际上述一系列动作,就是驱动dll的信息,已经写入了数据库的RegisterModule表。
这张表就是为系统服务反射加载驱动程序提供基本信息:加载的位置、类名 、描述,以便实例化为具体的驱动类。
在DAServer内有一个AddDriver方法,就是Activator.CreateInstance加载驱动并转换为IDriver。
使用反射加载,最大优点就是用户可以自己实现一个驱动,或者引用第三方驱动,并用TagConfig注册,而不需要改动源代码。
三、 如何实现一个新驱动
- 驱动接口规范
[Description("S7 以太网协议")] public sealed class SiemensTCPReader : IPLCDriver, IMultiReadWrite
我在前一篇文章里提到,IPLCDriver 是所有PLC都实现的接口。IMultiReadWrite 是支持批量读写的下位机必须实现的接口。
因为PLC都具有可连接性、可读写性,同时西门子的协议还支持批量读写。
SiemensTCPReader 里的Connect方法,就是对libnodave中connectPLC方法的封装。
Dispose方法,就是释放libnodave的非托管资源。
ReadBytes、ReadInt32、ReadBit、ReadFloat、WriteFloat等方法,就是对IReaderWriter接口的实现。也就是单独读写。
ReadMultiple、WriteMultiple方法是对IMultiReadWrite 接口的实现,也是对libnodave中批量读写方法的封装。
GetDeviceAddress/GetAddress方法很重要,在TagConfig里编辑的地址是西门子约定俗成的,比如DB3,DD122.1,要翻译成下位机理解的设备地址DeviceAddress。
这个Description 属性描述符,在注册之后会被反射为驱动的描述字符,存入数据库。
- 为什么要实现批量读写,如何实现
批量读写的目的,就是为了提高性能。
很多人总是拿C#、.NET的所谓性能说事。首先我认为.NET性能优良。关键是你怎么写。
而对性能影响最大的往往不是语言、框架,而是IO。IO的性能成本往往是语言本身的十倍、百倍、甚至千倍。
在PLC通讯过程中,请求往返就是性能瓶颈。因为大部分下位机不支持订阅-发布(推送)模式,只能采用定期轮询方式。
既然是轮询,如果变量很多,如果一个个去读写,读1000个变量要轮询1000次,一次往返起码几十毫秒,效率差的惊人,还占用PLC大量资源。这是行不通的。
但如果你想一次就能读入1000个变量,要考虑到变量地址可能是不连续的,散乱的。而每次读取的大小受PDU所限。
所以,就一定要对变量的分布分析整理,类似送快递,客户虽然分布在各个小区,但并不能像醉汉一样漫无目的的投递,而是根据客户的分布,执行最优化的路线选择。
整理的结果,就是将所有要读写的变量分割为块,每块大小不能超过PLC 的PDU。力求往返次数最少、一次读入的区块最大、包含的变量最多。
分割整理变量区块的功能,就是PLCGroup 的UpdatePDUArea函数实现的。不过我在这里只是进行简单的地址归纳,并没有做最优解。最优算法肯定是存在的,但可能与现行方法出入不会太大。
四、 下面的计划
写一系列帖子,把架构、原理讲清楚。大致如下:
- 网关层接口概述
- 上下位机通讯原理
- 如何实现一个设备驱动
- 如何设计图元
- VS插件模块及原理
- 归档模块及文件格式
- 如何进行功能扩展
- 组态变量表达式实现
github地址:https://github.com/GavinYellow/SharpSCADA。欢迎大家提出宝贵意见和建议!