一,架构图及其说明
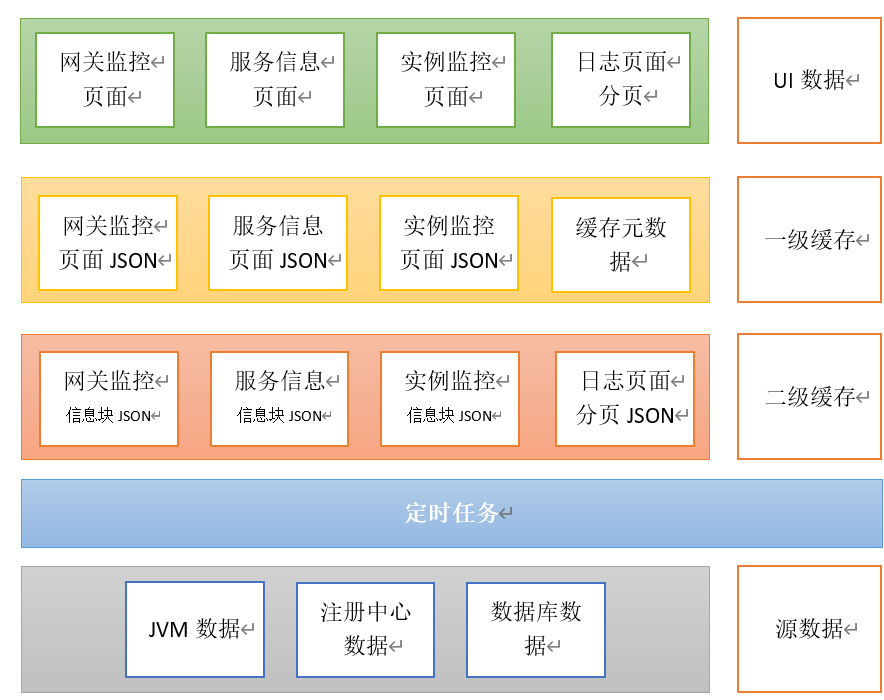
1,UI数据:页面
2,一级缓存:内存
3,二级缓存:硬盘文件系统
4,定时任务:同步数据库与缓存中的数据
5,数据源:数据库
二,场景分析
加缓存之前的数据信息流:
浏览器发出数据请求后,服务器后端接收到数据请求,开始通过数据源连接读取各种数据后,通过业务逻辑层处理成需要的逻辑数据后返回给浏览器。浏览器更新数据模型展现数据。
三,上述场景存在的问题
1、 每次获取数据都要走相同的数据流程来获取数据,如果遇到源数据宕机、或者逻辑性能降低情况时页面效果会非常的差。
2、 每次获取到数据后都要进行相同的数据逻辑处理,浪费性能。
3、 获取到的数据可能并没有发生变化,但是每次都产生了不必要的浪费。
四,缓存方案选择
1,划分的原则:业务场景
2,常见方案:
1)一级缓存+二级缓存;
2)一级缓存;
3,实现方式:
1)一级缓存可以采用HashTable的方式来进行数据存储。不同的页面可以创建不同的HashTable对象,页面的不同信息块创建不同的Key值,将逻辑层处理好的JSON数据作为Value来存放。当信息块更新数据时,通过Key值可以直接获取到JSON数据。如果是这个页面的数据刷新则直接将HashTable的数据序列化为JSON返回即可。
2) 二级缓存基于本地文件系统,将数据序列化为JSON后写入文本文件即可。一个页面信息块一个JSON文本文件。
3)缓存元数据是用来二级缓存中的文件片同一级缓存中HashTable及Keyd的映射关系。如果数据较少,可以将映射关系写死在程序中。
4)定时任务,是将源数据的相关数据通过定时单线程方式获取数据后通过业务逻辑层将数据加工成信息块需要的JSON数据后,将数据更新到一级缓存和二级缓存。定时任务需要注意:不能使用固定时间启动方式,比如说一秒钟启动一次,这种方式是不稳定的。因为如果数据源及加工数据的时间超过了固定启动时间,会早点线程阻塞引发线程安全问题。所以最好采用长轮训机制,在每次轮训过程中增加等待时间,确保每个时间点有且仅有一个线程在获取数据。
4,根据使用场景选择合适的缓存方案:
(1)页面数据的刷新频率较高可以采用一级缓存加二级缓存的方式。通过增加一级缓存减少磁盘IO频次,从而提高性能,提高页面效果。
(2)页面数据量较大为降低内存消耗,是不能使用一级缓存的。只能使用二级缓存来提高性能。例如:日志的分页数据首加载、实例分页数据的首加载,这样的场景式不能使用一级缓存的。
5,更多处理方式
(1)唯一签名处理:另外为避免频繁的内存和磁盘IO,最好对数据做唯一签名处理,即对序列化后的JSON数据做MD5加密,获取数据唯一签名。这样做的好处是可以根据MD5值来判断是否数据发生了变化,如果获取数据的MD5值和缓存中数据的MD5值不同则说明数据发生了变化,需要更新缓存数据。如果MD5值相同,则不需要更新缓存数据。