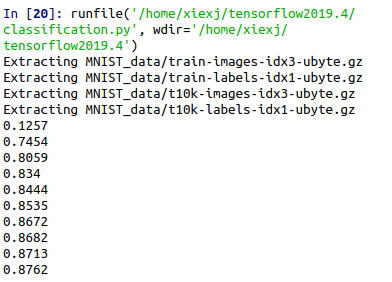
MNIST简单分类
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('MNIST_data', one_hot=True) #print mnist.train.num_examples #print mnist.test.num_examples #print mnist.validation.num_examples #print mnist.train.images[0] #print mnist.train.labels[0] def add_layer(inputs, in_size, out_size, activation_function=None): Weights = tf.Variable(tf.random_normal([in_size, out_size])) biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) Wx_plus_b = tf.matmul(inputs, Weights) + biases if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs def compute_accuracy(v_xs, v_ys): # no need ys y_pre = sess.run(prediction, feed_dict={xs: v_xs}) # tf.argmax(x, 1): find max value in each row here_return 100*1 correct_prediction = tf.equal(tf.argmax(y_pre, 1), tf.argmax(v_ys, 1)) # tf.cast(x, dtype): transfer format of x to dtype accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) result = sess.run(accuracy, feed_dict = {xs: v_xs, ys: v_ys}) return result # define placeholder for inputs to network xs = tf.placeholder(tf.float32, shape = (None, 784))#28*28 ys = tf.placeholder(tf.float32, [None, 10]) # add output layer prediction = add_layer(xs, 784, 10, activation_function = tf.nn.softmax) # the error between prediction and real data cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log( tf.clip_by_value(prediction, 1e-10, 1)),reduction_indices=[1])) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) with tf.Session() as sess: init = tf.global_variables_initializer() sess.run(init) for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={xs: batch_xs, ys:batch_ys}) if i % 100 == 0: print(compute_accuracy( mnist.test.images, mnist.test.labels))
Tensorflow解决overfitting——dropout 转自:莫烦Tensorflow教程(1~14)
Summary:所有需要在TensorBoard上展示的统计结果。
tf.name_scope():为Graph中的Tensor添加层级,TensorBoard会按照代码指定的层级进行展示,初始状态下只绘制最高层级的效果,点击后可展开层级看到下一层的细节。
tf.summary.scalar():添加标量统计结果。
tf.summary.histogram():添加任意shape的Tensor,统计这个Tensor的取值分布。
tf.summary.merge_all():添加一个操作,代表执行所有summary操作,这样可以避免人工执行每一个summary op。
tf.summary.FileWrite:用于将Summary写入磁盘,需要制定存储路径logdir,如果传递了Graph对象,则在Graph Visualization会显示Tensor Shape Information。执行summary op后,将返回结果传递给add_summary()方法即可。
未使用dropout:
import tensorflow as tf from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelBinarizer #load data digits=load_digits() #0~9的图像 X=digits.data #y是binary的,表示数字1,就在第二个位置放上1,其余都为0 y=digits.target y=LabelBinarizer().fit_transform(y) #切分 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=3) def add_layer(inputs,in_size,out_size,layer_name,activation_function=None): #Weights是一个矩阵,[行,列]为[in_size,out_size] Weights=tf.Variable(tf.random_normal([in_size,out_size]))#正态分布 #初始值推荐不为0,所以加上0.1,一行,out_size列 biases=tf.Variable(tf.zeros([1,out_size])+0.1) #Weights*x+b的初始化的值,也就是未激活的值 Wx_plus_b=tf.matmul(inputs,Weights)+biases #激活 if activation_function is None: #激活函数为None,也就是线性函数 outputs=Wx_plus_b else: outputs=activation_function(Wx_plus_b) # 下面的表示outputs的值 tf.summary.histogram(layer_name+'/outputs',outputs) return outputs #define placeholder for inputs to network xs=tf.placeholder(tf.float32,[None,64]) ys=tf.placeholder(tf.float32,[None,10]) #add output layer # l1为隐藏层,为了更加看出overfitting,所以输出给了100 l1=add_layer(xs,64,100,'l1',activation_function=tf.nn.tanh) prediction=add_layer(l1,100,10,'l2',activation_function=tf.nn.softmax) #the error between prediction and real data cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1])) #添加标量统计结果 tf.summary.scalar('loss',cross_entropy) train_step=tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy) init=tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) #添加一个操作,代表执行所有summary操作,这样可以避免人工执行每一个summary op merged=tf.summary.merge_all() #summary writer goes in here train_writer=tf.summary.FileWriter("logs/train",sess.graph)#train为log的子文件夹 test_writer=tf.summary.FileWriter("logs/test",sess.graph) for i in range(500): sess.run(train_step,feed_dict={xs:X_train,ys:y_train}) if i%50==0: #record loss train_result=sess.run(merged,feed_dict={xs:X_train,ys:y_train}) test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test}) train_writer.add_summary(train_result,i) test_writer.add_summary(test_result,i)
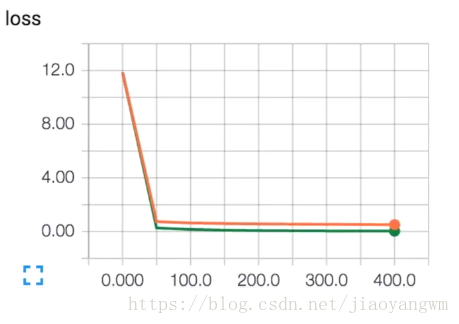
红色:testdata
绿色:trainingdata
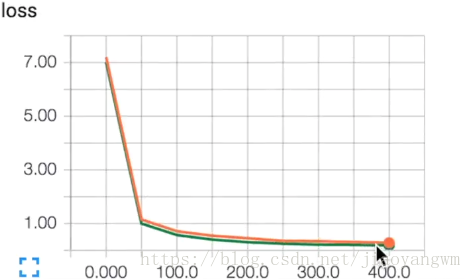
使用dropout:
train_result=sess.run(merged,feed_dict{xs:X_train,ys:y_train,keep_prob:1})
也就是训练数据未使用dropout时,仍然有过拟合
train_result=sess.run(merged,feed_dict{xs:X_train,ys:y_train,keep_prob:0.5})
此时两者拟合的很好
import tensorflow as tf from sklearn.datasets import load_digits from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelBinarizer #load data digits=load_digits() #0~9的图像 X=digits.data #y是binary的,表示数字1,就在第二个位置放上1,其余都为0 y=digits.target y=LabelBinarizer().fit_transform(y) #切分 X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=3) def add_layer(inputs,in_size,out_size,layer_name,activation_function=None): #Weights是一个矩阵,[行,列]为[in_size,out_size] Weights=tf.Variable(tf.random_normal([in_size,out_size]))#正态分布 #初始值推荐不为0,所以加上0.1,一行,out_size列 biases=tf.Variable(tf.zeros([1,out_size])+0.1) #Weights*x+b的初始化的值,也就是未激活的值 Wx_plus_b=tf.matmul(inputs,Weights)+biases #dropout 主功能,drop掉50%的结果,输出更新后的结果 Wx_plus_b=tf.nn.dropout(Wx_plus_b,keep_prob) #激活 if activation_function is None: #激活函数为None,也就是线性函数 outputs=Wx_plus_b else: outputs=activation_function(Wx_plus_b) # 下面的表示outputs的值 tf.summary.histogram(layer_name+'/outputs',outputs) return outputs #define placeholder for inputs to network """dropout""" # 确定保留多少结果不被舍弃掉 keep_prob=tf.placeholder(tf.float32) xs=tf.placeholder(tf.float32,[None,64]) ys=tf.placeholder(tf.float32,[None,10]) #add output layer # l1为隐藏层,为了更加看出overfitting,所以输出给了100 l1=add_layer(xs,64,50,'l1',activation_function=tf.nn.tanh) prediction=add_layer(l1,50,10,'l2',activation_function=tf.nn.softmax) #the error between prediction and real data cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1])) #添加标量统计结果 tf.summary.scalar('loss',cross_entropy) train_step=tf.train.GradientDescentOptimizer(0.6).minimize(cross_entropy) init=tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) #添加一个操作,代表执行所有summary操作,这样可以避免人工执行每一个summary op merged=tf.summary.merge_all() #summary writer goes in here train_writer=tf.summary.FileWriter("logs/train",sess.graph)#train为log的子文件夹 test_writer=tf.summary.FileWriter("logs/test",sess.graph) for i in range(500): # drop掉60%,保持40%不被drop掉 sess.run(train_step,feed_dict={xs:X_train,ys:y_train,keep_prob:0.4}) if i%50==0: #record loss(不要drop掉任何东西,所以为1) train_result=sess.run(merged,feed_dict={xs:X_train,ys:y_train,keep_prob:0.5}) test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test,keep_prob:1}) train_writer.add_summary(train_result,i) test_writer.add_summary(test_result,i)