1.HDFS基本概念
HDFS设计架构
- 块(Block)文件被切分成块进行存储,默认大小为64MB,块是文件存储处理的逻辑单元(备份、查找)
- NameNode是管理节点,存放文件元数据
- 文件与数据块的映射表
- 数据块与数据节点的映射表

客户查询一个访问请求,那么会向上NameNode去查询元数据,返回的结果会知道文件存放在哪些节点上面,于是向这些节点去拿数据块,得到数据块后再组装拼接成想要的文件
- DateNode是工作节点,存放数据块

2.数据管理策略
HDFS中数据管理与容错
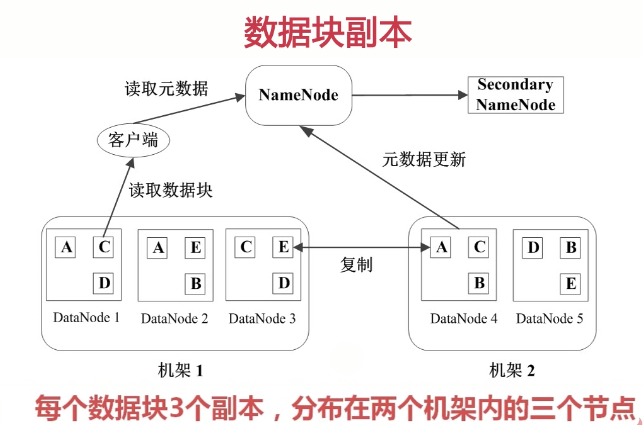
默认的数据块保留三份(多份冗余),其中两份在同一个机架上面
心跳检测

判断是否断机、宕机,NameNode也可知道哪些DataNode已经挂了
SecondaryNameNode
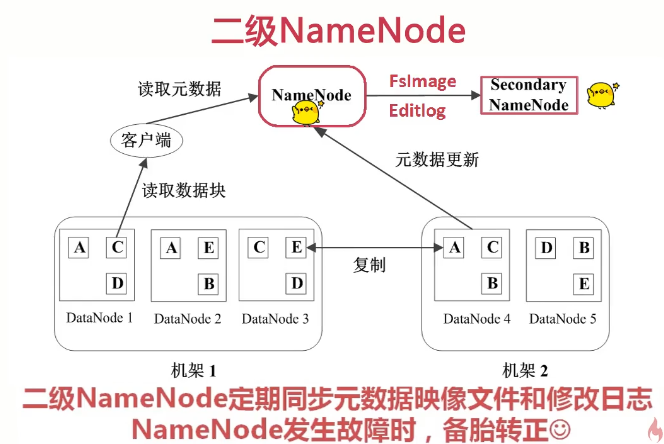
3.HDFS中文件的读写操作
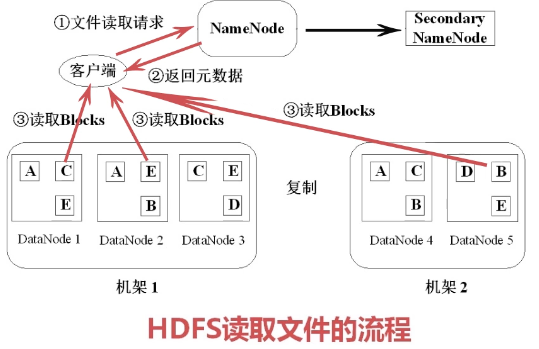
客户端(Java程序、命令行)发起文件读取请求(将文件名、路径告诉NameNode)
NameNode查询元数据,返回客户端(文件包含哪些块,分别在哪些DataNode里可找到)
客户端找到这些DataNode读取Blocks,下载下来后进行组装
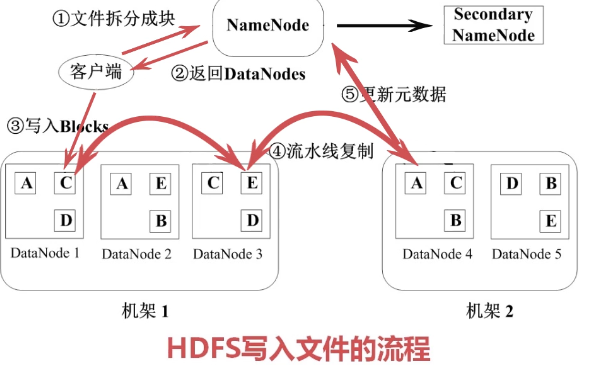
4.HDFS特点
- 数据冗余,硬件容错(允许运行在廉价机上的容错)
- 流式的数据访问(一次写入多次读取,写入之后不被修改,要修改只能删除后写入新的块)
- 存储大文件(如果太多小文件会使NameNode的负载压力比较大)
适用性和局限性
- 适合数据批量读写,吞吐量高
- 不适合交互式应用,低延迟很难满足(不适合数据库)
- 适合一次写入多次读取,顺序读写
- 不支持多用户并发写相同文件