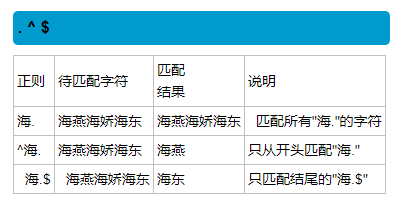
模块分为三种:
1.内置模块:python安装时自带的。
2.扩展模块:别人写的,需要安装之后可以直接使用,如django,tornado等。
3.自定义模块:自己写的模块。
序列化模块
序列指字符串,序列化就是将字典、列表转换成字符串的过程。
1.json模块 所有编程语言通用,支持的数据类型有限,只支持数字、字符串、序列、字典,不支持除了str数据类型之外key,json中所有字符串都用双引号“”。
功能:
1)dumps和loads 在内存中操作数据,用于网络传输和多个字典。
dumps 序列化:数据转换成字符串。
loads 反序列化:字符串转回原数据类型。
import json dict = {'name':'yuan','age':18} ret = json.dumps(dict) print(type(ret),ret) #<class 'str'> {"name": "yuan", "age": 18} res = json.loads(ret) print(type(res),res) #<class 'dict'> {'name': 'yuan', 'age': 18}
dict1 = {'name':'yuan','age':18}
dict2 = {'name':'alex','age':20}
dict3 = {'name':'jin','age':25}
f = open('log1','a',encoding='utf-8')
str1 = json.dumps(dict1)
f.write(str1+'
')
str2 = json.dumps(dict2)
f.write(str2+'
')
str3 = json.dumps(dict3)
f.write(str3+'
')
f.close()
f = open('log1','r',encoding='utf-8')
for i in f:
print(json.loads(i.strip()))
f.close()
2)dump 和 load 在文件中操作数据,用于一个数据直接存在文件里
dump :数据写入文件。
load:文件中的字符串转换成数据读出。
dict = {'name':'yuan','age':18}
f = open('log','w',encoding='utf-8')
json.dump(dict,f)
f.close()
with open('log','r',encoding='utf-8') as f:
ret = json.load(f)
print(ret)
2.pickle模块 只能在python语言的程序之间传递数据,支持python的所有数据类型,序列化结果是bytes类型。
dumps,loads,dump,load和json用法一样
可以直接写入读取多行
dict1 = {'name':'yuan','age':18}
dict2 = {'name':'alex','age':20}
dict3 = {'name':'jin','age':25}
f = open('log3','wb')
pickle.dump(dict1,f)
pickle.dump(dict2,f)
pickle.dump(dict3,f)
f.close()
f = open('log3','rb')
while True:
try:
print(pickle.load(f))
except EOFError:
break
序列化自定义类对象
class A: def __init__(self,name,age): self.name = name self.age = age a = A('alex',80) import pickle ret = pickle.dumps(a) print(ret) obj = pickle.loads(ret) print(obj.__dict__) f = open('log4','wb') pickle.dump(a,f) f.close() f = open('log4','rb') obj = pickle.load(f) print(obj.__dict__)
3.shelve模块 只支持python,针对文件操作
import shelve f = shelve.open('log5') f['key'] = {'int':10, 'float':9.5,'str':'Sample data'} f.close() f1 = shelve.open('log5') existing = f1['key'] f1.close() print(existing) f2 = shelve.open('log5') f2['key']['int'] = 50 #不能修改已有结构中的值 f2['key']['new'] = 'new'# 不能在已有的结构中添加新的项 f2['key'] = 'new' #但是可以覆盖原来的结构 existing = f2['key'] f2.close() print(existing)
hashlib模块
特点:
1)提供摘要算法,将字符串转换成数字,不同的字符串转换的数字一定不同。
2)一段字符串直接进行摘要和分成几段进行摘要的结果是相同的。
3)摘要过程不可逆。
用途:文件的一致性校验(md5),密文验证的时候加密(md5和sha)。
1.md5通用算法
import hashlib m = hashlib.md5() m.update('123456'.encode('utf-8')) print(m.hexdigest()) # 打印十六进制 m = hashlib.md5('wahahah'.encode('utf-8')) #加盐 m.update('123456'.encode('utf-8')) print(m.hexdigest()) username = 'yuan' #动态加盐 m = hashlib.md5(username.encode('utf-8')) m.update('123456'.encode('utf-8')) print(m.hexdigest()) #d3f17b4a0cf89aaa4ad56828e6bf9523
2.sha算法
用法和md5一样,安全系数更高,后面的数字越大安全系数越高,结果越长计算时间越长
m = hashlib.sha1() m.update('123456'.encode('utf-8')) print(m.hexdigest())
文件一致性校验
import hashlib #引用hashlib模块 def check(filename): #创建一个函数 md5obj = hashlib.md5() #创建一个md5算法对象 with open(filename,'rb') as f: #以读的形式打开文件得到一个文件句柄 while True: content = f.read(1024) #读出文件内容,可以分成几段摘要 if content: md5obj.update(content) # else: break return md5obj.hexdigest() #返回十六进制的字符串 ret1 = check('file1') ret2 = check('file2') print(ret1) print(ret2)
configparse模块 配置文件模块
logging模块 记录日志模块
collections模块 增加扩展数据类型
time时间模块
random模块
生成随机验证码
import random def id_code(num): ret = '' for i in range(num): number = str(random.randint(0,9)) alph_num1 = random.randint(65,90) alph_num2 = random.randint(97,122) alph1 = chr(alph_num1) alph2 = chr(alph_num2) choice = random.choice([number,alph1,alph2]) ret += choice return ret print(id_code(6))
sys 模块
1.sys.argv:以脚本的形式执行一个文件的时候可以加一些参数,主要用于执行脚本前的登录和指定脚本的启动模式
两个用法:
1)执行脚本前的登录
import sys print(sys.argv) #返回一个列表,列表第一项是当前文件所在的路径 if sys.argv[1] == 'alex' and sys.argv[2] == '1234': #设置两个参数 print('登录成功') else: sys.exit() 在以脚本的形式执行时直接输入两个参数就可以了

2)制定脚本的启动模式
import sys #引用sys模块 import logging #引用记录日志模块 inp = sys.argv[1] if len(sys.argv) > 1 else 'WARNING' #如果sys.argv的长度大于1,inp等于sys.argv的第一项,否则inp等于warning logging.basicConfig(level=getattr(logging,inp)) #登录日志级别设置为inp num = int(input('>>>')) #输入数字 logging.debug(num) #设置打印级别为debug a = num * 100 logging.debug(a) b = a - 10 logging.debug(b) c = b + 5 print(c)
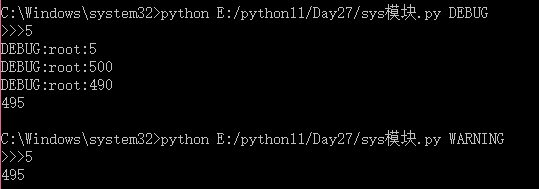
2.sys.path 导入模块的时候从这个路径获取。
3.sys.exit() 退出程序。
4.sys.version 查看当前python解释器版本。
5.sys.platform 查看当前操作系统。
os模块
os模块是与操作系统交互的一个接口
''' os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd os.curdir 返回当前目录: ('.') os.pardir 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') 可生成多层递归目录 os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() 删除一个文件 os.rename("oldname","newname") 重命名文件/目录 os.stat('path/filename') 获取文件/目录信息 os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/" os.linesep 输出当前平台使用的行终止符,win下为" ",Linux下为" " os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") 运行shell命令,直接显示 os.popen("bash command).read() 运行shell命令,获取执行结果 os.environ 获取系统环境变量 os.path os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。 即os.path.split(path)的第二个元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是绝对路径,返回True os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 os.path.getsize(path) 返回path的大小 '''
re模块
正则表达式
概念:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
主要用于:表单验证—使用一些规则来检测字符串是否符合要求。
爬虫—从一段字符串中找到符合要求的内容。
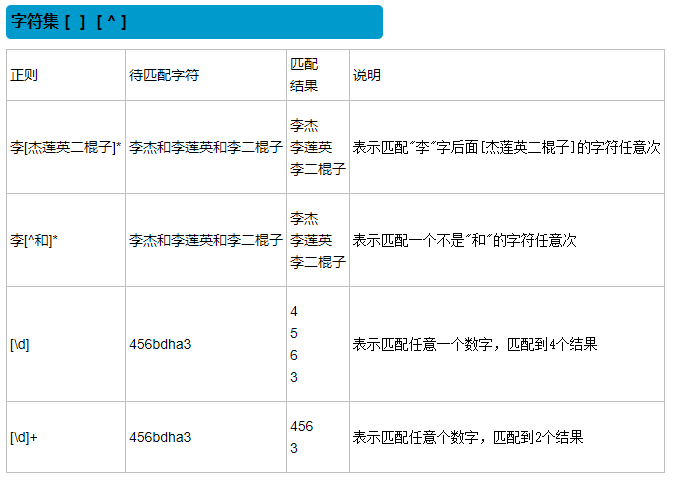
字符组:在同一个位置可能出现的各种字符组成了一个字符组,用[ ]表示,一个字符组只能匹配一个字符。
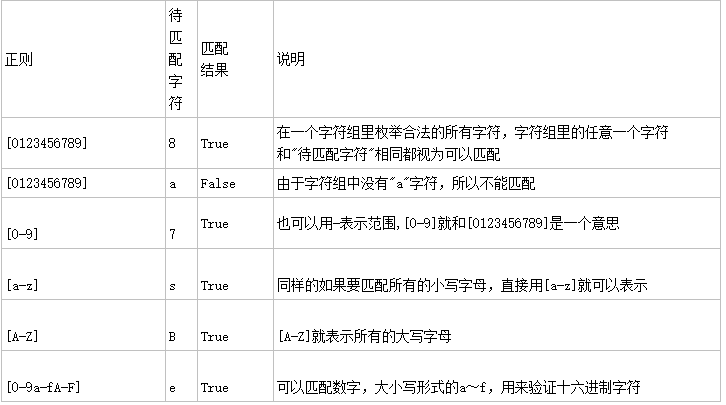
字符
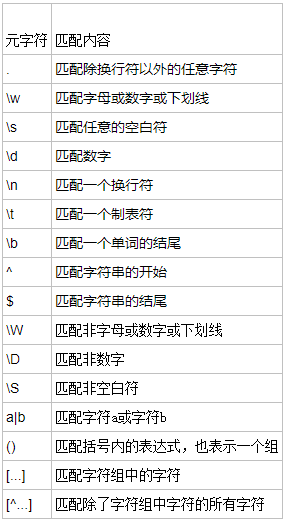
量词