ZK是什么?
分布式服务框架,主要用来解决分布式应用中数据管理问题;如统一命名服务,集群管理,分布式应用配置管理等
zk是一个数据库,是一个拥有文件系统特点的数据库
是一个 解决了数据一致性问题的分布式数据库
是一个具有发布,订阅(watch)功能的分布式数据库
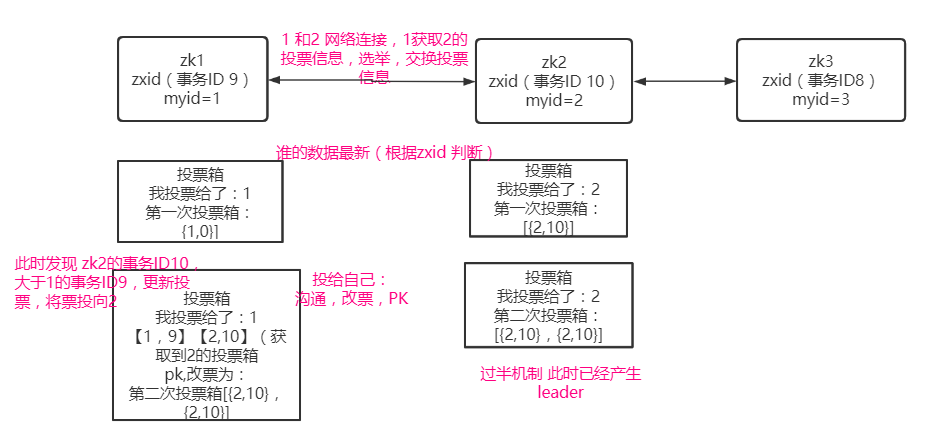
集群何时选取Leader?
- 集群启动时选择Leader(服务器启动)
- Leader挂掉时选举
- follower挂掉后Leader发现没有过半follower跟随自己-不能对外提供服务(领导者选举)
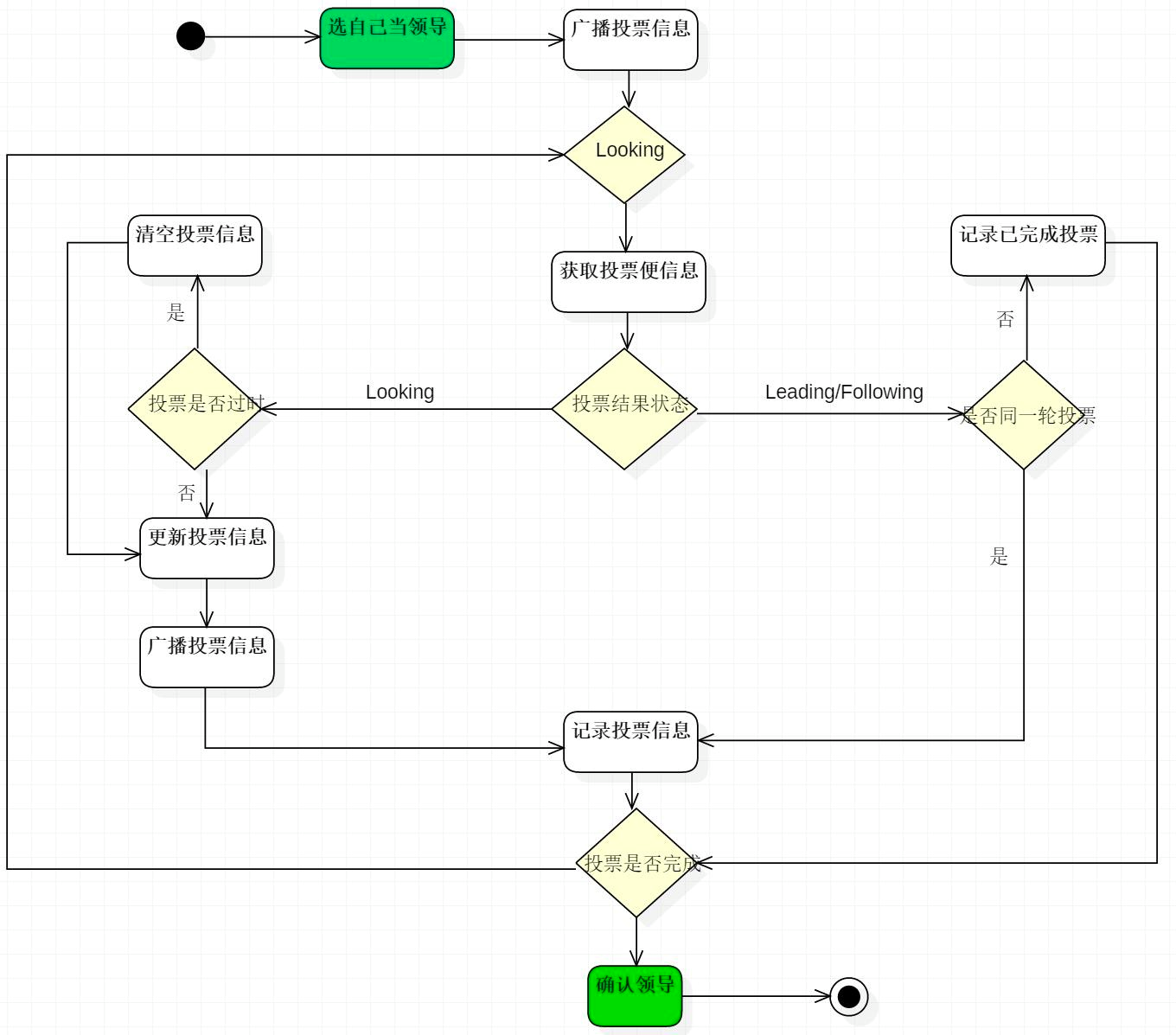
如何选举?
投票->改票->选票

一致性?2PC机制,zk是保证CP
弱一致
强一致
最终一致
如何解决一致性问题?2PC机制
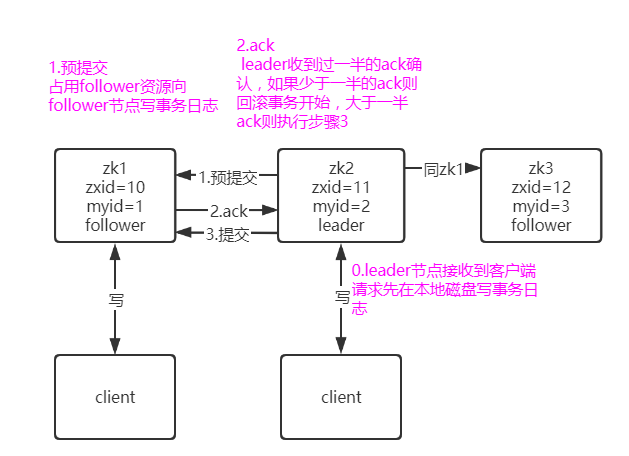
事务请求:事务性请求:create ,set ,deLete,update, 生成事务日志,zxid(自增的)
- 预提交占用follower资源(占用资源:其实是在follower节点上面写一条事务日志,事务日志先持久化到硬盘)
- 接收到大于一半的ack
- 提交:将磁盘内容读更新到内存的DataTree
事务请求,Leader 接受请求,然后将数据同步给其他节点,如果同步过程中异常,有一半(3个节点, 有一个成功)其他都异常则回滚改该请求,少于一半(3个节点, 有两个成功)则提交事务,整个集群挂掉,再次启动的时候 会主动同步数据
非事务性请求:get,exists,读请求是直接返回本节点数据
数据同步?启动时候同步数据
ZAB协议? 保证一致性
就是规定:如何领导选举,过半机制, 2pc的内容如何提交,数据同步等
问题?
过半机制当有一台已经收到ack ,另外响应慢怎么办?过一半提交, 少于一半则回滚
当提交的时候是所有Folower都提交之后,Leader才提交吗?
Leader会把要发送的数据放到队列里面,循环follower节点从队列里面获取数据发送(线程异步发送),然后提交自己节点数据包,如果follower节点发送比较慢,不会影响最终Leader响应用户的速度(不会等待所有follower节点都执行成功,follower节点是异步执行的)
查看谁是Leader? status
为什么是 >n/2 而不是>=haLf ? 担心有两个Leader
zk 保证的是CP机制
为什么是推荐奇数节点?过半机制
5 台机器可以有2台挂掉
6台机器也可以有2台挂掉 那为什么要用6台呢?
zk有哪些节点:
- Leader节点
- follower机器越多:提高读性能,降低写性能(第一:选举Leader,每多一个follower都需要投票 ,第二:每个follower都需要发送ack请求)那怎么提高性能?使用观察者节点
- 观察者节点(obser):可以处理读写请求(写请求转发给Leader,读请求直接返回本节点数据),不参与Leader选举投票,提高读请求,不影响写请求性能
Leader是如何提交的,即如何submit?
- 发送follower提交请求(事务ID)将数据包发入到队列里面,有单独线程发送submit请求给follower
- 同步信息给观察者节点(是直接发送数据包)
- Leader节点提交
synchronized public void processAck(long sid, long zxid, SocketAddress followerAddr) { if ((zxid & 0xffffffffL) == 0) { /* * We no longer process NEWLEADER ack by this method. However, * the learner sends ack back to the leader after it gets UPTODATE * so we just ignore the message. */ return; } if (lastCommitted >= zxid) { // The proposal has already been committed return; } Proposal p = outstandingProposals.get(zxid); if (p == null) { LOG.warn("Trying to commit future proposal: zxid 0x{} from {}", Long.toHexString(zxid), followerAddr); return; } p.ackSet.add(sid); if (self.getQuorumVerifier().containsQuorum(p.ackSet)){ if (zxid != lastCommitted+1) { LOG.warn("Commiting zxid 0x{} from {} not first!", Long.toHexString(zxid), followerAddr); LOG.warn("First is 0x{}", Long.toHexString(lastCommitted + 1)); } outstandingProposals.remove(zxid); if (p.request != null) { toBeApplied.add(p); } if (p.request == null) { LOG.warn("Going to commmit null request for proposal: {}", p); } //follower 发送事务ID commit(zxid); //obser 直接发送数据包 inform(p); //leader 执行commit zk.commitProcessor.commit(p.request); if(pendingSyncs.containsKey(zxid)){ for(LearnerSyncRequest r: pendingSyncs.remove(zxid)) { sendSync(r); } } } }
量大,服务器压力大。需要用到分布式,集群。
三台机器,一个请求如何落到一台机器上?如何协调工作
zookeeper 解决了各服务之间协调工作的内容如下图:

端口 默认2181
1.Leader-follower-observer
2.Leader选取 :?有哪些算法?
既然是分布式,集群,一个请求只能有一台机器接接收并处理,其他机器如何同步消息?
数据同步怎么办?事务请求走Leader,非事务走所有节点,增删改有Leader节点处理,处理完同步到非Leader;使用了节点zab协议(原子广播协议):数据同步,Leader选取,原子广播。
Zookeeper集群中,当某一个集群节点接收到一个写请求操作时,该节点需要将这个写请求操作发送给其他节点,以使其他节点同步执行这个写请求操作,从而达到各个节点上的数据保持一致,也就是数据一致性。我们通常说Zookeeper保证CAP理论中的CP就只这个意思。何为CAP
Zookeeper集群底层是怎么保证数据一致性的,用的两阶段提交+过半机制来保证的。
事务性请求包括:更新操作、新增操作、删除操作。
非事务性请求:查询操作。
ZK有哪些节点?
zookeeper:文件类型的树形目录结构
有序节点:顺序递增
持久化节点:永久存储,存储在磁盘上
临时节点:会话结束即删除节点,不能有子节点,存在冲突:比如 临时节点下在建立了持久节点怎么办,如果在建立个临时节点,生命周期不一样怎么办?
树形结构: 每个节点是 key-vaLue
数据在磁盘中的表示
假设我们现在在Zookeeper中有一个数据节点,节点名为/datanode,内容为125,该节点是持久化节点,所以该节点信息会保存在文件中。
方法一:

方法二:快照+事务日志
当前快照:

当前事务日志:

Zookeeper集群中的节点在处理事务性请求时,需要将事务操作同步给其他节点,事务操作是一定要进行持久化的,以便在同步给其他节点时出现异常进行补偿。实际上事务日志还运行数据进行回滚,这个在两阶段提交中也是非常重要的。持久性节点存储在磁盘上每次查询需要IO操作,Zookeeper为了提高数据的查询速度,会在内存中也存储一份数据
数据在内存中的表示
Zookeeper中的数据在内存中的表示类似一颗树,必须以/开头,一颗具有父子层级的多叉树,在Zookeeper源码中叫DataTree:
请求处理逻辑
请看下图:

请注意,对于上图,Zookeeper真正的底层实现,zk1是Leader,zk2和zk3是Learner,是根据领导者选举选出来的。
非事务性请求直接读取DataTree上的内容,DataTree是在内存中的,所以会非常快。
zookeeper 应用:
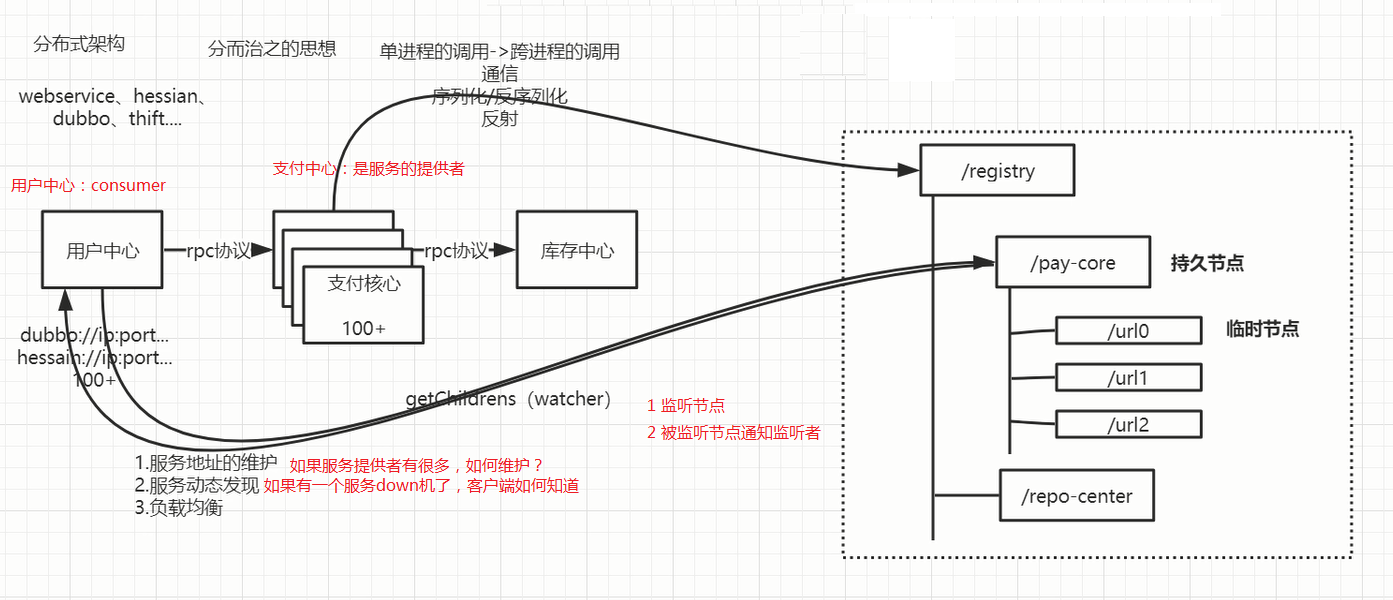
1.分布式锁:(节点抢占,顺序节点)
- 节点抢占 :同级节点是唯一的(同时创建同一个节点,多个应用创建肯定只有一个成功)失败的节点怎么办?watcher:客户端可以监控某一个节点的变化
- 监听方式3中:get exists getchiLdren 设置监控: get /mic true 对mic 节点监控 监控删除事件如 app2可以watcher app1新建的节点事件,如果app1新建的节点有修改会给所有监控对象app2,app3发通知(只触发一次,如果失败则丢掉事件)会发生 惊群问题?会触发所有节点
- 顺序节点:创建顺序节点,最小节点获取锁 1 2 3 ;2监控1 3监控2 ,每个节点监控上一个节点

2.服务注册:
各个服务通信:rpc协议远程过程服务调用rpc 协议有 hession,dubbo,webservice 框架,服务直接通信用到:序列化/反序列化,反射