单表操作
添加记录
1 方法一: 实例化Book类 进行添加记录 2 3 book_obj = Book(id=1,title='python',price=101,pub_date='2014-02-13',publish="华夏出版社") 4 book_obj.save() # 此方法添加之后必须有 save 操作 ,否则数据不会增加 5 6 方法二: 使用Book的 object管理器的create方法添加记录 7 obj = Book.objects.create(title='C++',price=89,pub_date='2014-12-03',publish='海浪出版社') 8 print(obj.title )
查询表记录API
(1). all()方法:查询所有数据 返回一个Queryset对象
(2).first() 和 last()方法: 返回第一个和最后一个对象 返回值:models对象 调用者: Queryset
(3). filter(**kwargs):返回和筛选条件相匹配的对象 调用者:object管理器 返回值:Queryset对象
(4).get(**kwargs)方法: 返回与所给筛选条件相匹配的model对象 调用者:object管理器 返回值:model对象
(5). exclude(**kwargs)方法:排除符合条件的数据 调用者:Queryset对象 返回值:Queryset对象
(6). order_by(**kwargs)方法:根据条件进行排序 调用者:Queryset对象 返回值:Queryset对象
(7).count()方法:对数据计数(可加约束) 调用者:object管理器 返回值:int数值
(8).exist()方法:判断数据是否为空 调用者:Queryset对象 返回值:bool类型
(9).value()方法:通过内循环获取对应字段的数据 调用者:object管理器或者Queryset对象 返回值:Queryset对象(其中数据以字典的形式存储)
(10).value_list()方法:通过内循环获取对应字段的数据 调用者:object管理器或者Queryset对象 返回值:Queryset对象(其中数据以元组的形式存储)
(11).distinct()方法:对于数据中的某一字段进行去重 调用者:Queryset对象 返回值:Queryset对象(其中数据以字典的形式存储)


1 obj = Book.objects.all() 2 print(obj) # 返回Queryset列表对象 :[obj1,obj2,obj3,....] 3 print(type(obj)) 4 5 for i in obj: 6 print(i.title) 7 8 ''' 9 遍历书名: 10 python 11 java 12 lua 13 lua 14 lua 15 C++ 16 ''' 17 print(obj[0].title,obj[1].title) # python java
first_obj = Book.objects.all().first() last_obj = Book.objects.all().last() print(first_obj,last_obj) # Book object (1) Book object (6) # 相当于 first_obj = Book.objects.all()[0] print(first_obj) # Book object (1)
book_list = Book.objects.filter(publish='海龟出版社') print(book_list) # <QuerySet [<Book: Book object (2)>, <Book: Book object (3)>, <Book: Book object (4)>, <Book: Book object (5)>]> fir_obj = Book.objects.filter(publish='海龟出版社').first() # Book object (2) last_obj = Book.objects.filter(publish='海龟出版社').last() # Book object (5)
# 只有结果为一时才有效 查询结果为空或者为多者时都会报错 obj = Book.objects.get(title='python') # model对象 :Book object (1) print(obj.title) # python # obj = Book.objects.get(title='lua') # 查询结果为多者报错:get() returned more than one Book -- it returned 3!
book_list = Book.objects.all().exclude(title='python') # 单条件排除 book_list=Book.objects.all().exclude(title='C++',publish="海浪出版社") # 多条件排除 # for book in book_list: # print(book.publish)
obj = Book.objects.all().order_by("title") # 单条件排序 obj2 = Book.objects.all().order_by("title","price") # 多条件排序
res = Book.objects.all().count() print(res,{"type":type(res)}) # 6 {'type': <class 'int'>}
ret = Book.objects.all().exists() print(ret,{"type":type(ret)}) # True {'type': <class 'bool'>}
ret1 = Book.objects.all().values("title") # 等于 ret1 = Book.objects.values("title") ret2 = Book.objects.all().values("title",'price') print(ret1,{"type":type(ret1)}) # # <QuerySet [{'title': 'python'}, {'title': 'java'}, {'title': 'lua'}, {'title': 'Go'}, {'title': 'C#'}, {'title': 'C++'}]> {'type': <class 'django.db.models.query.QuerySet'>} print(ret2,{"type":type(ret2)}) # <QuerySet [{'title': 'python', 'price': Decimal('101.00')}, {'title': 'java', 'price': Decimal('100.00')}, {'title': 'lua', 'price': Decimal('99.00')}, {'title': 'Go', 'price': Decimal('68.00')}, {'title': 'C#', 'price': Decimal('70.00')}, {'title': 'C++', 'price': Decimal('89.00')}]> {'type': <class 'django.db.models.query.QuerySet'>}
ret1 = Book.objects.all().values_list("title") # ret1 = Book.objects.values("title") # 同上 ret2 = Book.objects.all().values_list("title", 'price') # print(ret1, {"type": type(ret1)}) # <QuerySet [('python',), ('java',), ('lua',), ('Go',), ('C#',), ('C++',)]> {'type': <class 'django.db.models.query.QuerySet'>} print(ret2, {"type": type(ret2)}) # <QuerySet [('python', Decimal('101.00')), ('java', Decimal('100.00')), ('lua', Decimal('99.00')), ('Go', Decimal('68.00')), ('C#', Decimal('70.00')), ('C++', Decimal('89.00'))]> {'type': <class 'django.db.models.query.QuerySet'>}
ret = Book.objects.all() print(ret) ret1 = Book.objects.values('price') print(ret1) ret2 = Book.objects.values('price').distinct() print(ret2) ''' 结果: ret: <QuerySet [<Book: Book object (1)>, <Book: Book object (2)>, <Book: Book object (3)>, <Book: Book object (4)>, <Book: Book object (5)>, <Book: Book object (6)>]> ret1: <QuerySet [{'price': Decimal('100.00')}, {'price': Decimal('100.00')}, {'price': Decimal('99.00')}, {'price': Decimal('68.00')}, {'price': Decimal('70.00')}, {'price': Decimal('89.00')}]> ret2: <QuerySet [{'price': Decimal('100.00')}, {'price': Decimal('99.00')}, {'price': Decimal('68.00')}, {'price': Decimal('70.00')}, {'price': Decimal('89.00')}]> '''
========================= 单表查询之模糊查询 =========================
数值方面模糊查询
(1). price__lt 查询价格小于80的数据
ret1 = Book.objects.filter(price__lt=80) print(ret1) # <QuerySet [<Book: Book object (4)>, <Book: Book object (5)>]>
(2). price__gt 查询价格大于70的数据
ret2 = Book.objects.filter(price__gt=70) print(ret2) # <QuerySet [<Book: Book object (1)>, <Book: Book object (2)>, <Book: Book object (3)>, <Book: Book object (5)>, <Book: Book object (6)>]>
(3).查询价格大于70且价格小于80的数据
ret3 = Book.objects.filter(price__gt=70,price__lt=80,) print(ret3) # <QuerySet [<Book: Book object (5)>]>
(4).查询价格为列表中的数据
ret4 = Book.objects.filter(price__in=[100,200]) print(ret4) # <QuerySet [<Book: Book object (1)>]>
======== 内容方面模糊查询
===包含方面查询:
(1).查询title字段包含小写字母”o“的数据 区分大小写
ret1 = Book.objects.filter(title__contains="o") print(ret1) # <QuerySet [<Book: Book object (5)>, <Book: Book object (6)>]> # 查询title字段包含小写字母”O“的数据 ret2 = Book.objects.filter(title__contains="O") print(ret2) # <QuerySet []> # 没有数据显示为空
(2).不区分大小写查询
ret = Book.objects.filter(title__icontains="O") print(ret) # <QuerySet []>
===开头结尾查询:
1、查询以”C“为开头的数据 区分大小写
ret1 = Book.objects.filter(title__startswith='C') print(ret1) # <QuerySet [<Book: Book object (5)>, <Book: Book object (6)>]>
2、查询以”c“为开头的数据 区分大小写
ret1 = Book.objects.filter(title__startswith='c') print(ret1) # <QuerySet []>
3、查询以”c“为开头的数据 不区分大小写
ret1 = Book.objects.filter(title__istartswith='c') print(ret1) # <QuerySet [<Book: Book object (5)>, <Book: Book object (6)>]>
4、查询以”n“为结尾的数据 区分大小写
ret1 = Book.objects.filter(title__endswith='n') print(ret1) # <QuerySet [<Book: Book object (1)>]>
5、查询以”N“为结尾的数据 区分大小写
ret1 = Book.objects.filter(title__endswith='N') print(ret1) # <QuerySet []>
6、查询以”N“为结尾的数据 不区分大小写
ret1 = Book.objects.filter(title__iendswith='N') print(ret1) # <QuerySet [<Book: Book object (1)>]>
========== 日期方面查询
1、 查询年份为2014
ret1 = Book.objects.filter(pub_date__year=2014,) print(ret1) # <QuerySet [<Book: Book object (1)>, <Book: Book object (6)>]>
2、 查询年份为2014 月份为12
ret2=Book.objects.filter(pub_date__year=2014,pub_date__month=12) print(ret2) # <QuerySet [<Book: Book object (6)>]>
3、 查询年份为2014 月份为12 天数为3的数据
ret3 = Book.objects.filter(pub_date__year=2014,pub_date__month=12,pub_date__day=3) print(ret3) # <QuerySet [<Book: Book object (6)>]>
删除记录和修改记录
1、 删除:delete()方法 调用者:Queryset对象 和 model对象
ret = Book.objects.filter(title="C++").delete() # Queryset对象调用 print(ret) # (1, {'app01.Book': 1}) ret1 = Book.objects.filter(publish="海洋出版社").first().delete() # Queryset对象调用 print(ret1) # (1, {'app01.Book': 1})
2、 修改记录:update()方法 调用者: Queryset对象
ret = Book.objects.filter(title="C#").update(price=99)# print(ret) # 2
多表操作
数据库关系:
- 一对一
- 一对多
- 多对多
一、创建模型
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
模型建立如下:
class Publish(models.Model): ''' 出版社信息表 ''' nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) city = models.CharField(max_length=32) tel = models.IntegerField() email = models.EmailField() class Book(models.Model): ''' 书籍表 ''' nid = models.AutoField(primary_key=True) title = models.CharField(max_length=32) price = models.DecimalField(decimal_places=2,max_digits=8) pub_date = models.DateField() # 与Publish表建立一对多的关系 外键建立在多的一方:ForeignKey(to="关系表",to_field="关联字段",on_delete=models.CASCADE) publish = models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE) # 与Author表建立多对多的关系 ManyToManyField(to="关系表",) authors = models.ManyToManyField(to="Author",) class AuthorDetail(models.Model): ''' 作者详情表 ''' nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) email = models.EmailField(max_length=32) addr = models.CharField(max_length=32) class Author(models.Model): ''' 作者表 ''' nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) # 与作者详情表为一对一关系 使用OneToOneField(to="关系表",to_field="关联字段",on_delete=models.CASCADE) # 在django 2.0 以上版本 需要加上 on_delete=models.CASCADE # 不然会报错 ”TypeError: __init__() missing 1 required positional argument: 'on_delete'“ authordetail = models.OneToOneField(to="AuthorDetail",to_field="nid" ,on_delete=models.CASCADE) # 在django 2.0 以上版本 需要加上 on_delete=models.CASCADE
注意:
在django 2.0 以上版本 需要加上 “ on_delete=models.CASCADE ”, 不然会报错 ”TypeError: __init__() missing 1 required positional argument: 'on_delete'“
执行命令后生产表如下:

其中表“app01_book_authors” 是ORM根据models中的关联关系生成的,不是我们手动创建的
# 与Author表建立多对多的关系 ManyToManyField(to="关系表",) authors = models.ManyToManyField(to="Author",)
注意事项:
- 表的名称myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称
- id 字段是自动添加的
- 对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
- 这个例子中的CREATE TABLE SQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。
- 定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加models.py所在应用的名称。
- 外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None
一、添加记录:
(1)一对一添加
# 添加出版社信息(单表) pub = Publish.objects.create(nid=1,name="人民出版社",city="北京",tel=1234456,email="12156@qq.com") pub = Publish.objects.create(name="海南出版社",city="海南",tel=1232316,email="2421356@qq.com")
数据库数据:

(2)一对多添加
往书籍Book表中添加数据,并关联出版社Publish表
# 方式一 # book_obj = Book.objects.create(nid=2,title="java",price=480,pub_date="2018-05-06",publish_id=1) # print(book_obj.title) # print(book_obj.price) # print(book_obj.publish) # print(book_obj.publish.city) # print(book_obj.publish.email) # print(book_obj.publish.tel) # print(book_obj.publish.tel) # print(book_obj.publish_id) # 方式二 # 先取出一个Publish对象pub_obj 然后让publish=pub_obj Django会根据book表里的publish关系获取到对应的出版社id 然后进行关联 # pub_obj = Publish.objects.filter(nid=1).first() # book_obj = Book.objects.create(title="lua",price=12312,pub_date="2011-02-16",publish=pub_obj) # # print(book_obj.publish) # Publish object (1) # print(book_obj.publish.city) # 北京 # print(book_obj.publish.email) # 12156@qq.com # print(book_obj.publish.tel) # 1234456 # print(book_obj.publish_id) # 1
数据库数据:表app01_book

(3)多对多添加
现在往作者表:Author、作者详情表AuthDetail中添加数据,并进行关联
# 创建作者信息 AuthorDetail.objects.create(email="123123@qq.com",addr="sdfasdf") AuthorDetail.objects.create(email="421233@qq.com",addr="gesdf") AuthorDetail.objects.create(email="23145@qq.com",addr="hainan") AuthorDetail.objects.create(email="34212@qq.com",addr="beijing") Author.objects.create(name="Tom",authordetail_id=1) Author.objects.create(name="Jane",authordetail_id=2) Author.objects.create(name="Tone",authordetail_id=3) Author.objects.create(name="Jin",authordetail_id=4) # 给python关联作者 book1 = Book.objects.get(title='python') book2 = Book.objects.get(title='java') book1.authors.add(1) book1.authors.add(2) # 上面两步等同于 # book1.authors.add(*[1,2]) book2.authors.add(2,3) # 解决关联信息 book1.authors.remove(1) # 单条解除 book1.authors.clear() # 全部解除 print(book2.authors.all()) # <QuerySet [<Author: Tom>, <Author: Jin>]>
表app01_author:
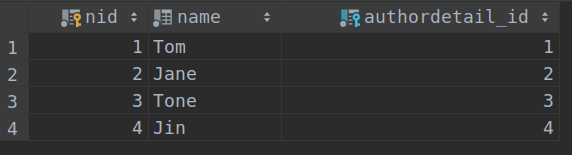
表app01_authordetail :
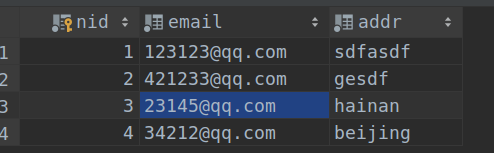
表app01_book_authors :
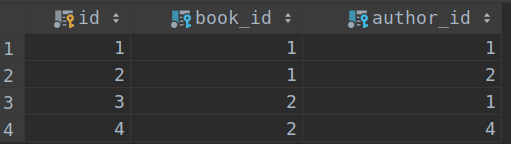
二、查询记录:
=========================基于对象的跨表查询===========================
正反向查询:
''' 查询分为正向和反向查询 比如表A和表B 关联属性在A中 根据字段进行查询:obj.关联属性 正向查询: A----------------------->B 根据表名进行查询:obj.表名小写_set.all() 反向查询: B------------------------>A '''
一对多查询
''' 一对多: 正向查询: Book--------------->Publish book_obj.publish 反向查询: Publish --------------->Book pub_obj.book_set ''' # 表Book和表Publish(一对多) 关联属性publish在Book中 # 查询书名python的出版社名字(正向查询) book = Book.objects.filter(title='python').first() # 获取Book对应的对象 print(book.publish.name) # 人民出版社 # 查询人民出版社的出版的所有书籍名字(反向查询) pub_obj = Publish.objects.filter(name="人民出版社").first() # 获取Publish对应的对象 ret = pub_obj.book_set.all() # 获取对应的书籍 print(ret) # <QuerySet [<Book: python>, <Book: java>, <Book: go>, <Book: lua>]>
多对多查询
''' 多对多: 正向查询: Book--------------->Author book_obj.authors 反向查询: Author --------------->Book author_obj.book_set.all() ''' # 查询书籍python的所有作者名字(正向查询) book_obj = Book.objects.filter(title="python").first() ret = book_obj.authors.all() print(ret) # <QuerySet [<Author: Tom>, <Author: Jane>]> # 查询书籍Tom的所有书籍名字(反向查询) author_obj = Author.objects.filter(name="Tom").first() ret = author_obj.book_set.all() print(ret) # <QuerySet [<Book: java>, <Book: python>]>
一对一查询
''' 一对一: 因为是一对一关系 所以查询结果是唯一的 正向查询: Author--------------->Authordetail book_obj.authordetail 反向查询: Authordetail --------------->Author authordetail_obj.author ''' # 查询Tom的地址 author_obj = Author.objects.filter(name="Tom").first() print(author_obj.authordetail.addr) # sdfasdf # 查询邮箱为23145@qq.com的姓名和年龄 authordetail_obj = AuthorDetail.objects.filter(email="23145@qq.com").first() print(authordetail_obj.author.name) # Tone
=========================基于双下滑线的模糊查询 ========================
查询方式:
''' 正向查询用字段 反向查询用 "表名小写__属性“ 从而告诉ORM引擎 join 哪张表 '''
一对多:
查询书名为python的出版社名字
''' sql语句查询: select app01_publish.name from app01_book inner join app01_publish on app01_book.title="python" and app01_book.nid = app01_publish.nid; '''
方式1 通过Book表join与其关联的Publish表,属于正向查询;再按照字段 publish 告知ORM join Publish表
ret1 = Book.objects.filter(title="python").values("publish__name") print(ret1) # <QuerySet [{'publish__name': '人民出版社'}]>
方式二:通过Publish表join与其关联的Book表,属于反向查询;再按照表名小写 book__title 告知ORM引擎 join Book表
ret2 = Publish.objects.filter(book__title="python").values("name") print(ret2) # <QuerySet [{'name': '人民出版社'}]>
两种方式的sql语句:
方式1 打印的sql语句: (0.001) SELECT "app01_publish"."name" FROM "app01_book" INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."nid") WHERE "app01_book"."title" = 'python' LIMIT 21; args=('python',) 方式2 打印的sql语句: (0.000) SELECT "app01_publish"."name" FROM "app01_publish" INNER JOIN "app01_book" ON ("app01_publish"."nid" = "app01_book"."publish_id") WHERE "app01_book"."title" = 'python' LIMIT 21; args=('python',)
从sql语句可以看出 ,两种方式的sql语句都是一样的 只不过顺序颠倒了下
多对多:
现在用双下划线查询上面的例子:
# 查询书籍python的所有作者名字(正向查询) # 方式一:通过Book表join与其关联的Author表 属于正向查询;再通过字段”authors“告知ORM join Author表 ret = Book.objects.filter(title="python").values("authors__name") print(ret) # <QuerySet [{'authors__name': 'Tom'}, {'authors__name': 'Jane'}]> # 方式二:通过Author表join与其关联的Book表,属于反向查询;按表名小写book告知ORM引擎join book_authors表 ret = Author.objects.filter(book__title="python").values("name") print(ret) # <QuerySet [{'name': 'Tom'}, {'name': 'Jane'}]>
一对一
# 查询Jane的addr # 方式一:通过Author表join与其关联的Authordetail表 属于正向查询;再按照字段authordetail 告知ORM join Authordetail表表 ret = Author.objects.filter(name="Jane").values("authordetail__addr") print(ret) # <QuerySet [{'authordetail__addr': 'gesdf'}]> # 方式一:通过Authordetail表join与其关联的Author表 属于反向查询;再按照表明小写“author 告知ORM join Author表 ret = AuthorDetail.objects.filter(author__name="Jane").values("addr") print(ret) # <QuerySet [{'addr': 'gesdf'}]>
连续跨表查询
查询地址以“h”开头的所有作者出版的 书籍以及出版社名称
方式一:
''' 拆分:以作者为根 查询对应的书籍名称以及其出版社名称 查询地址以“h”开头的所有作者 出版的书籍以及出版社名称 涉及的表 :Author,AuthorDetail,Book,Publish Author与AuthorDetail有关联 且属于正向查询 所以使用字段 authordetail 找出对应的作者 --> Author.objects.filter(authordetail__addr__startswith="h") Author与Book有关联,且属于反向查询,所以使用小写表名获取书籍名称 --> values("book__title") Author和Publish没有关联,所以需要使用连续跨表查询 values("book__publish__name") '''
ret = Author.objects.filter(authordetail__addr__startswith="h").values("book__title","book__publish__name") print(ret) # <QuerySet [{'book__title': 'java', 'book__publish__name': '人民出版社'}]>
方式二:
''' 拆分:以书籍为根 查询关系:Book --> Author --> AuthorDetail --> Publish 查询地址以“h”开头的所有作者出版的书籍 以及出版社名称 涉及的表 :Author,AuthorDetail,Book,Publish Book与AuthorDetail没有关联 所以需要使用连续跨表查询 --> Book.objects.filter(authors__authordetail__addr__startswith="h") Book与Publish有关联,且属于正向查询 所以使用字段 publish 获取出版社名字-> values('title',"publish__name") '''
ret = Book.objects.filter(authors__authordetail__addr__startswith="h").values('title',"publish__name") print(ret) # <QuerySet [{'title': 'java', 'publish__name': '人民出版社'}]>
聚合查询
aggregate():聚合管理器, 需配合聚合函数使用 (Avg,Max,Min,Count,..)
注意:aggregate() 返回的是一个字典 不再是Queryset集合
示例:
from django.db.models import Avg,Max,Min,Count # 导入聚合函数 ret = Book.objects.all().aggregate(Avg("price")) print(ret) # {'price__avg': Decimal('3335.5')} price__avg是ORM根据聚合函数和属性以双下划线拼成的,也可以自定义键名 ret = Book.objects.all().aggregate(avg_price=Avg("price")) print(ret) # {'avg_price': Decimal('3335.5')} ret = Book.objects.all().aggregate(Max("price"),Min("price"),Count("price")) # 获取最高价格和最低价格 书籍数量 print(ret) # {'price__max': Decimal('12312'), 'price__min': Decimal('100'), 'price__count': 4}
分组查询
单表分组查询:
先创建一个员工表:
class Empers(models.Model): ''' 员工信息详情表 ''' nid = models.AutoField(primary_key=True) department = models.CharField(max_length=32) name = models.CharField(max_length=32) email = models.EmailField(max_length=32) salary = models.IntegerField() provience = models.CharField(max_length=32)
添加数据:
Empers.objects.create(name="join",email="sdsfs21@qq.com",salary="5333",department="开发部",provience="北京") Empers.objects.create(name="tom",email="52342s21@qq.com",salary="5377",department="开发部",provience="上海") Empers.objects.create(name="jane",email="21321@qq.com",salary="6000",department="销售部",provience="天津") Empers.objects.create(name="爱尔兰新",email="efas21@qq.com",salary="12000",department="后勤部",provience="北京")
查询示例:
# 查询所有部门及其员工的平均薪资 ret = Empers.objects.values("department").annotate(Avg("salary")) print(ret) # <QuerySet [{'department': '后勤部', 'salary__avg': 12000.0}, {'department': '开发部', 'salary__avg': 5355.0}, {'department': '销售部', 'salary__avg': 6000.0}]> # 查询所有省份及其员工的人数 ret = Empers.objects.values("provience").annotate(Count("name")) print(ret) # <QuerySet [{'provience': '上海', 'name__count': 1}, {'provience': '北京', 'name__count': 2}, {'provience': '天津', 'name__count': 1}]>
总结:
ORM语法:单表模型.objects.values("group by的字段").annotate(聚合函数(“字段”))
单表模型.objects.values("group by的字段") 相当于 sql语句的:“select * from 表名 group by 字段”
注意:
在单表查询中annotate是以前面的字段进行分组统计的,如果分组的字段包含主键,因为主键是唯一的,所以分组就是没有意义的
多表分组查询:
示例1:
''' Book 表: nid title pub_date publish_id price 1 python 2018-05-06 1 100 2 java 2018-05-06 1 480 3 go 2018-08-26 1 450 4 lua 2011-02-16 1 12312 Publish 表: nid name city tel email 1 人民出版社 北京 1234456 12156@qq.com 14 海南出版社 海南 1232316 2421356@qq.com 15 天津出版社 天津 2311312 34221356@qq.com # 查询所有书籍及其出版社的名字 sql语句查询: select Book.title,Publish.name from Book inner join Publish on Book.publish_id = Publish.nid # 查询每个出版社的名字及其出版书籍的个数 sql语句查询: 先join两张表: select * from app01_book inner join app01_publish on app01_book.publish_id = app01_publish.nid nid title pub_date publish_id price nid name city tel email 1 python 2018-05-06 1 100 1 人民出版社 北京 1234456 12156@qq.com 2 java 2018-05-06 14 480 14 海南出版社 海南 1232316 2421356@qq.com 3 go 2018-08-26 1 450 1 人民出版社 北京 1234456 12156@qq.com 4 lua 2011-02-16 1 12312 1 人民出版社 北京 1234456 12156@qq.com 分组查询sql语句: select app01_publish.name,Count("title") from app01_book inner join app01_publish on app01_book.publish_id = app01_publish.nid group by app01_publish.nid 结果: id name Count("title") 1 人民出版社 3 2 海南出版社 1 '''
现在使用ORM语句进行查询:
# 方式一:通过主键进行分组 然后再获取想要的字段 # ret = Publish.objects.values("nid").annotate(c=Count("book__title")) # print(ret) # <QuerySet [{'nid': 1, 'c': 3}, {'nid': 14, 'c': 1}, {'nid': 15, 'c': 0}]> ret = Publish.objects.values("nid").annotate(c=Count("book__title")).values("name","c") print(ret) # <QuerySet [{'name': '人民出版社', 'c': 3}, {'name': '海南出版社', 'c': 1}, {'name': '天津出版社', 'c': 0}]> # 方式二:直接根据需分组的字段进行分组 ret = Publish.objects.values("name").annotate(c=Count("book__title")) print(ret) # <QuerySet [{'name': '人民出版社', 'c': 3}, {'name': '天津出版社', 'c': 0}, {'name': '海南出版社', 'c': 1}]>
示例二:查询每一个作者的名字以及出版过的书籍的最高价格
''' sql语句查询: select name,Max("app01_book".price) from app01_author inner join app01_authordetail on app01_author.authordetail_id = app01_authordetail.nid inner join app01_book on app01_author.nid = app01_book.nid group by app01_author.name ''' ret = Author.objects.values("pk").annotate(max_price=Max("book__price")).values("name","max_price") print(ret) # <QuerySet [{'name': 'Tom', 'max_price': Decimal('480')}, {'name': 'Jane', 'max_price': Decimal('480')}, {'name': 'Tone', 'max_price': Decimal('480')}, {'name': 'Jin', 'max_price': Decimal('480')}]> # 等同于下面语句 ret = Author.objects.all().annotate(max_price=Max("book__price")).values("name","max_price") print(ret) # <QuerySet [{'name': 'Tom', 'max_price': Decimal('480')}, {'name': 'Jane', 'max_price': Decimal('480')}, {'name': 'Tone', 'max_price': Decimal('480')}, {'name': 'Jin', 'max_price': Decimal('480')}]> ret = Author.objects.annotate(max_price=Max("book__price")).values("name","max_price") print(ret) # <QuerySet [{'name': 'Tom', 'max_price': Decimal('480')}, {'name': 'Jane', 'max_price': Decimal('480')}, {'name': 'Tone', 'max_price': Decimal('480')}, {'name': 'Jin', 'max_price': Decimal('480')}]>
总结:
多表分组模型:
模型一:
Author.objects.values("pk"). annotate(max_price=Max("book__price")). values("name","max_price") 关键字“每一个”后的表.objects.values("分组字段").annotate.(聚合函数("关联表__统计字段")).values("需要展示的字段")
模型二:
Author.objects.all(). annotate(max_price=Max("book__price")).values("name","max_price")
关键字“每一个”后的表.objects.all().annotate.(聚合函数("关联表__统计字段")).values("需要展示的字段")
注意:all()可加可不加,结果都是一样的 不同之处在于下面的写法 values(“”)中的字段可以取根表的所有字段以及统计的字段
解析:以 关键字“每一个”后的表 为根,通过values()进行分组;
然后通过分组管理器(annotate)配合聚合函数获取“关联表的统计字段”的数据
最后使用values("字段")获取需要的字段数据
extra方法:
在Django中,有些时间查询语句是ORM无法完成转换的,就像获取在datatime中的年月日,直接从数据库是无法查询的,我们可以个extra方法
格式: extra(select = {"自定义字段":“date_format(‘时间字段’,'%%Y-%%m-%%d')”}):
extra是将Queryset对象增加 一个自定义的字段,返回的结果还是Queryset对象。
date_list = Article.objects.filter(user=user).extra(select={"y_m_date":"date_format(create_time,'%%Y/%%m/%%d')"}).values("y_m_date").annotate(c=Count("nid")).values_list("y_m_date","c")
print(date_list)
#结果
<QuerySet [('2020/03/23', 1)]>
TruncMonth方法
除了extra方法之外,Django还给我们封装了一个”TruncMonth “方法
from django.db.models.functions import TruncMonth

在上图中, TruncMont把“timestamp”进行截取,只截取到月份,然后赋值给month,原理和extra一样,也是增加了一个键值对,返回的也是Queryset对象
ret = models.Article.objects.filter(user=user).annotate(month=TruncMonth("create_time")).values("month").annotate( c=Count("nid")).values_list("month", "c") print("ret----->",ret) # 结果 <QuerySet [(datetime.datetime(2020, 3, 1, 0, 0), 1)]>
===================== F与Q查询 ==================
F查询:
# 查询评论数大于阅读数的书籍 ret = Book.objects.all().filter(comment_num__gt=F("read_num")) print(ret) # <QuerySet [<Book: python>, <Book: go>]> # 将所有书籍的价格增加20 ret = Book.objects.update(price=F("price")+20)
Q查询:
Q有三种关联方式:且、或、非
且:和符号 “ & 匹配使用,用户连接多个参数
或:和符号 ”|“ 匹配使用,用于选择多个条件中的一个
非:和符号”~“ 匹配使用,用户否定某条件,后面必须跟 ”|“符号
示例:
from django.db.models import Q # 查询书名为python 且 价格为120的书籍 python 120 #方式一:正常写法 ret = Book.objects.filter(title="python",price=220).values("title","price") print(ret) # <QuerySet [{'title': 'python', 'price': Decimal('220.00')}]>
# 方式二:使用 Q ret = Book.objects.filter(Q(title="python") & Q(price=220)).values("title","price") print(ret) # <QuerySet [{'title': 'python', 'price': Decimal('220.00')}]> # 查询书名为python 或者 价格为120的书籍 ret = Book.objects.filter(Q(title="python") | Q(price=120)).values("title","price") print(ret) # <QuerySet [{'title': 'python', 'price': Decimal('220.00')}]> # 查询书名非python 或者 价格为120的书籍 ret = Book.objects.filter(~Q(title="python") | Q(price=120)).values("title","price") print(ret) # <QuerySet [{'title': 'java', 'price': Decimal('600.00')}, {'title': 'go', 'price': Decimal('220.00')}, # {'title': 'lua', 'price': Decimal('12432.00')}]>