在学习汉江独钓一书后,打算总结一下内核编程应该注意的事项,以及有关的一些基础知识。第一次接触内核编程,还真是很生疏,很多东西不能一下马上消化。这里做个回顾总结,好加深自己的印象。
## 1、内核编程环境
这里涉及到两个模式:内核模式和用户模式。这个可以和CPU的等级联系到一块:ring0,ring1,ring2,ring3,特权等级依次降低,最底层ring0层拥有最高的特权等级。而windows简化了这样的特权等级层次次关系,分成了内核层和用户层,对应的就是内核模式和用户模式。平时我们所编写的应用程序,运行后,在windows下就会生成一个对应的进程,针对的是单个进程进行程序的编写,受到了隔离保护的,运行环境受到操作系统的保护,很多底层的问题无需考虑,这使得编写应用程序变得相当容易。
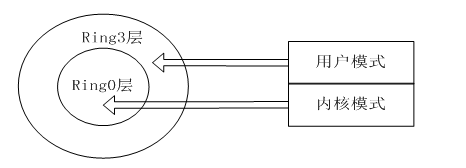
【图】CPU特权等级和windows层次对应关系
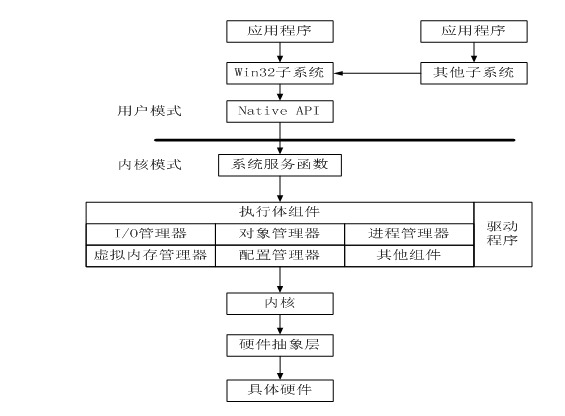
【图】windows结构
所谓的内核模式,实际上就是不受操作系统管制的最底层结构,为操作系统提供各项服务的核心部件。在这里,理论上可以实现任何可以想到的功能,而不受到操作系统的制约,也正因为如此,问题也就产生了,面对共享的内存空间、共享资源,如何进行同步操作就成了一个关键的问题。再者,内核结构很多都是不公开的,并且又没有操作系统的保护,所以一点系统出错,就是直接蓝屏或死机,这给内核调试带来了很大的麻烦。
windows一般都是用系统进程来加载内核模块的,但这并不是说内核代码始终运行在System进程里,也就是说当DriverEntry被调用时,一般是位于System进程中的,其他时候则不一定。内核模块位于内核空间,而内核空间又被所有的进程共享。因此,内核模块实际上位于任何一个进程空间中。但是任意一段代码的任意一次执行,一定是位于某个进程空间中的。而至于这是哪一个进程,取决于请求的来源、处理的过程等。
## 2、常用数据类型
一般来说,在进行内核编程时,应当遵守WDK的编码习惯,虽然这并不是必须的,但是如果不这么做,有可能还是会导致一些不稳定性的问题。比如unsigned long 在64bit 环境下为8字节、而在32bit 环境下是4字节,这个时候要把数据写到磁盘上时,到底写4个字节还是8个字节呢?问题也就出现了,所以WDK重新定义了这个类型,为ULONG。
以下是一些常用的数据类型的转换关系:
- unsigned long --- ULONG
- unsigned char --- UCHAR
- unsigned int --- UINT
- void --- VOID
- unsigned long * ---- PULONG
- unsigned char * --- PUCHAR
- unsigned int * --- PUCHAR
- void* ---PVOID
- char* --- PCHAR
- ........
当然也不仅仅是这些,一般来说,指针前面加上P,unsigned 对应 U,基本类型名不便只是换成了大写(例如char --- CHAR),当然这只是我个人见到的,也不排除有特例,我这么对应一般都没有什么问题。
函数一般都会返回操作的状态,以说明操作的情况,内核中这个类型是NTSTATUS。调用函数时一般这样做:
NTSTATUS status; status = function(..); if(NT_SUCCESS(status)){... 操作成功后要做的事情 ...}
NT_SUCCESS() 可以判断操作时候成功,当谈status还有其他的状态,可以查看WDK。
驱动力字符串一般用一个结构来保存,是一个宽字符串:
typedef struct _UNICODE_STRING{
USHORT Length; // Buffer的字节长度,实际存储的长度
USHORT MaximumLength; //Buffer的最大长度,即开辟的空间大小
PWSTR Buffer;//存储字符的缓冲区
}UNICODE_STRING *PUNICODE_STRING;
## 3、一些重要的数据结构
驱动编程中,比较重要的几个数据结构是:驱动对象(DRIVER_OBJECT)、设备对象(DEVICE_OBJECT)和请求(IRP)。
a. 一个驱动对象代表一个驱动程序,或者说一个内核模块。
b. 设备对象是由驱动创建的,一个驱动可以对应多个设备对象,设备对象是唯一能接收请求的实体。
c.windows内核中各部件的通信,是通过请求来完成的,来自用户层的相关操作,会被IO管理器翻译成请求(IRP或者与其等效的其它形式),处理这一个个的请求也就完成相应的操作。
关于这三个对象的结构可以在wdm.h中找到。这里给出重要数据结构的关系图:
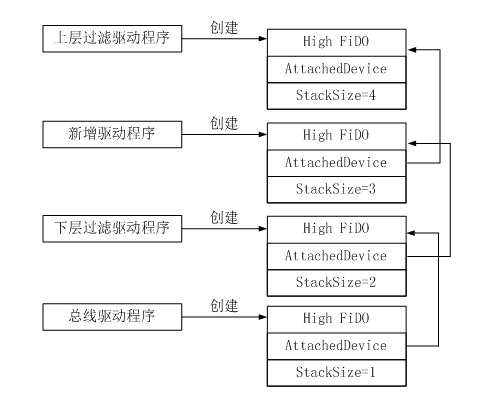
【图】设备栈结构,驱动垂直结构
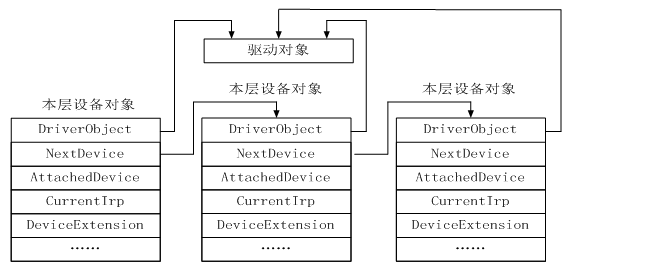
【图】驱动的水平结构,一个驱动可以闯将对个设备对象,这些设备构成一个链表结构
## 4、常用函数,以及内核API的学习
编写内核程序的时候,尽量使用内核API,虽然类似于wcscpy、memcpy等函数也可以用,但这些函数没有长度的检查,很容易发生溢出错误,应该避免使用。
主要的函数前缀有:Rtl-, Io-, Ke-, Zw-, Nt-, Ps-等。
有以下几类:
Ex系列--分配内存,获取互斥体等:
ExAllocatePool,分配内存
ExFreePool,释放内存
ExAcquireFastMutex获取一个快速互斥体
ExReleaseFastMutex释放一个快速互斥体
ExRaiseStatus抛出异常
Zw--Nt系列文件操作函数:
ZwCreateFile--创建文件
ZwWriteFile--写文件
ZwReadFile--读取文件
ZwQueryDirectoryFile--查询目录
ZwDeviceIoControlFile--发出设备控制请求
ZwCreateKey--打开一个注册表键
ZwQueryValueKey--读取一个注册表键
Rtl系列字符串操作函数:
RtlInitUnicodeString--初始化一个Unicode字符串
RtlCopyUnicode--拷贝字符串
RtlAppendUnicodeToString--追加字符串到另一个字符串
RtlStringCbPrintf--将字符打印到字符串中,相当于格式化字符串
RtlCopyMemory--拷贝内存
RtlMoveMemory--移动内存数据块
RtlZeroMemory--内存数据块清零
RtlCompareMemory--比较内存
RtlGetVersion--得到当前windows版本
Io开头的IO管理函数:
IoCreateFile--打开文件,比ZwCreateFile函数更加底层
IoCreateDevice--生成一个设备对象
IoCallDriver发送请求
IoCompleteRequest--完成IRP请求
IoCopyCurrentIrpStackLocationToNext--讲当前IRP栈空间拷贝到下一个栈空间
IoSkipCurrentIrpStackLocationToNext--跳过当前IRP栈空间
IoGetCurrentIrpStackLocation--得到当前IRP栈空间。
对于详细的说明可以查看WDK的帮助文档,API很多,我们不肯能全都记住,常使用,常动手,常查帮助,是很好的学习方法。见一个学一个,不记得就立即查帮助。相关的结构也可以直接查看WDK的头文件,这里可以查到帮助文档中没有的一些信息哦!!
## 5、Womdows的驱动开发模型
NT(KDM)、WDM、WDF(WDM的升级版)
## 6、WDK编程中的特殊性
调用源:沿着该函数往上走,再也不能找到其调用者,则这个函数就是调用源,一般的个单线程函数的调用源只有一个,也就是主函数,比如我们常见的main函数。而在内核编程中,一个函数往往有多个调用源,主要可以追溯到的调用源有以下几个:入口函数DriverEntry、卸载函数DriverUnload;各种分发函数;处理请求时的完成函数;其它回调函数。
在内核中,一个函数有可能同时被多个线程调用,这个是有就好保证多线程的安全性,也就是在输入相同的情况下要保证输出是相同的。多线程安全性可以依据以下几个规则进行判断:
- 可能运行于多线程环境下的函数,必须是多线程安全的。
- 如果函数A的所有调用源都是运行于单线程的,那么函数A也是运行于单线程的。
- 如果函数A的调用源中,其中有一个可能运行于多线程环境下,并且在调用路径上没有将多线程序列化成单线程,那么函数A也是可能运行于多线程环境下的。
- 如果函数A的所有可能出现多线程的调用路径上都被单线程化了,那么函数A就是单线程环境下的。
- 只是用函数内部资源,则函数是多线程安全的
- 如果函数在访问全局变量或者静态变量的操作采用强制的同步手段进行限制,可以等同于使用内部变量(上一条规则成立)。
内核代码主要调用源运行环境:
DriverEntry、DriverUnload 单线程 —— 这两个函数由系统进程的单一线程调用,不会出现多线程同步调用的情况
各种分发函数 多线程 —— 没有文档能保证分发函数不会被多线程同步调用,分发函数不会和DriverEntry同步,但是可能和DriverUnload同步
完成函数 多线程 —— 完成函数随时可能被未知的线程调用
各种NDIS回调函数 多线程 —— 随时可能被位置的线程调用
代码的中断级:
Windows为CPU的运行状态定义了许多的级别,即IRQL,任一时间中,CPU总是运行在其中的某一级别,各个级别规定了CPU能做哪些事情,哪些不可以做。高中断级可以抢占低中断级。
级别定义如下:
#define PASSIVE_LEVEL 0 ;级别最低,CPU在用户层,或刚进内核运行于管理层时就运行在此级别上
#define LOW_LEVEL 0 ;
#define APC_LEVEL 1 ;比PASSIVE_LEVEL略高,运行APC函数(进程与线程)时需要的级别
#define DISPATCH_LEVEL 2 ;相当于cpu运行在内核层,线程切换时级别从此下降
#define PROFILE_LEVEL 27 ;级别3以上用于硬件中断。
#define CLOCK1_LEVEL 28
#define CLOCK2_LEVEL 28
#define IPI_LEVEL 29
#define POWER_LEVEL 30
#define HIGH_LEVEL 31
两个规则:
- 如果在调用路径上没有特殊情况(导致中断级的提高或者降低),则一个函数执行时的中断级和它的调用源的中断级相同。
- 如果在调用路径上又获取自旋锁,则中断级随之升高,释放自旋锁,中断级随之下降。
处于高中断级中的函数不能调用处于低中断级中的API,若dispach级想调用passive级上的AIP,可以另创建一个线程专门执行。
其他:
函数定义中,变量的类型前常常会有:IN、OUT这样的字符,这些字符被定义成空,起到说明性的作用,IN表示输入参数,OUT表示输出参数。
PAGED_CODE(),进行分页测试,只要级别不高于APC_LEVEL,其代码都允许换出,若发现更高级的中断发出缺页中断,则发出异常,让编程者知道。
指定函数位置的预编译指令:
#pragma alloc_text(INIT, DriverEntry) #pragma alloc_text(INIT, DriverUnload) #pragma alloc_text(PAGE,NdisProtUnload) .... ....
这个宏仅仅用来指定某个函数的可执行代码在编译出来后在sys文件中的位置。内核模块编译出来后是一个PE文件的sys文件,这个文件的代码段(text段)中有不同的节(Section),不同的节被加载到内存中之后处理情况不同。主要有3个节:
- INIT节:在初始化完毕之后就被释放,不再占用内存空间。
- PAGE节:位于可分页交换的内存空间,这些空间在内存紧张的时候可以被交换到磁盘上以节省空间。
- PAGELK节:不适用预编译指定的时候,默然的状态。加载后位于不可分页交换的内存空间中。
VOID ASSERT( Expression ); —— 这个宏用于测试一个表达式,如果这个表达式的值是false,它就终止,并跳出到内核调试器。
## 7、课后习题
(1)内核编程环境和用户应用程序编程环境有哪些不同?
编程模式可分为两种:用户模式和内核模式。
其中用户应用程序的编程采用的是用户模式,这里都是在操作系统的隔离环境中完成的,也就是说对于这个模式来说不用考虑通用寄存器,内存是共享的,可通过操作系统实现进程间的资源共享,这属于单进程编程,利用的都是进程内的资源,不用担心会产生什么冲突。
内核编程使用的是内核模式编程,其内核属于操作系统的一个模块供各个进程调用,在内核空间中资源都是共享的并且不受操作系统的限制,很容易发生冲突。
(2)Windows有哪几种驱动开发模型?它们的发展现状如何?
model是根据操作系统的类型不同而取名的,有KDM(windows NT),WDM(windows 98 —— windows 2000),WDF(WDM的升级版),一脉相承的,不用担心过时。
(3)什么是用户空间?什么事内核空间?
进程的空间实际上被分成两个部分,一部分是进程独立使用的用户空间,一部分是容纳操作系统内核的内核空间。具体到4G内存控件的32位windows系统上,低2G是用户空间,高2G是内核空间。
(4)内核模块运行在什么进程环境下?
内核模块无处不在,内核模块属于操作系统的一个部分,为各进程提供服务,也就是说每个进程中都有可能运行有内核模块,但是内核模块一般是通过系统system进程进行加载的。
(5)请简述驱动对象、设备对象、请求之间的关系。
驱动对象、设备对象、请求
内核编程采用的是面向对象的编程思想来进行编程的,把每个事物都看成一个对象。而驱动对象可以说是一个驱动程序也可以说是一个内核模块。设备对象是唯一能接受请求的对象,而设备对象是在内核模块中建立的,也就是说设备对象属于驱动对象,设备对象在接收到请求以后交由驱动对象的分发函数进行处理。请求,内核模块之间的交互都是通过一个个的请求实现的,比如说申请资源、读取信息等,一般使用IRP请求,一个请求有可能要历经多个设备,所以需要暂时存储中间变量的栈空间。
(6)请简述如何判断对一个全局变量的访问是否要加自旋锁或者互斥体使之序列化。
当一个程序有可能会运行在多线程环境下的时候就需要保证其是多线程安全的,也就是说不能出现线程冲突。对一个全局变量的访问时候要加自旋锁或互斥体使之序列化,取决于被使用的变量是否影响到保证多线程的安全。
(7)请简述如何估计当前代码的中断级。
1、如果调用途径没有特殊情况,中断级和调用源一样
2、获自旋锁中断级升高,失自旋锁中断级降低