zoukankan
html css js c++ java
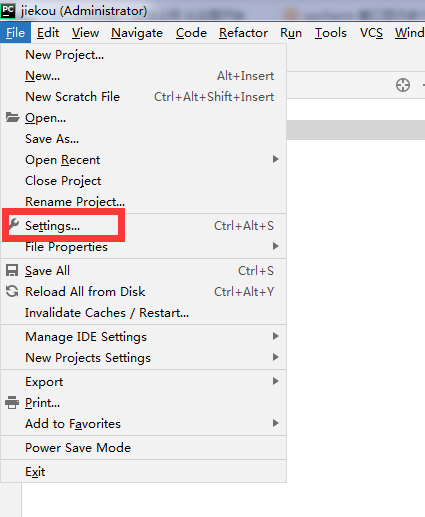
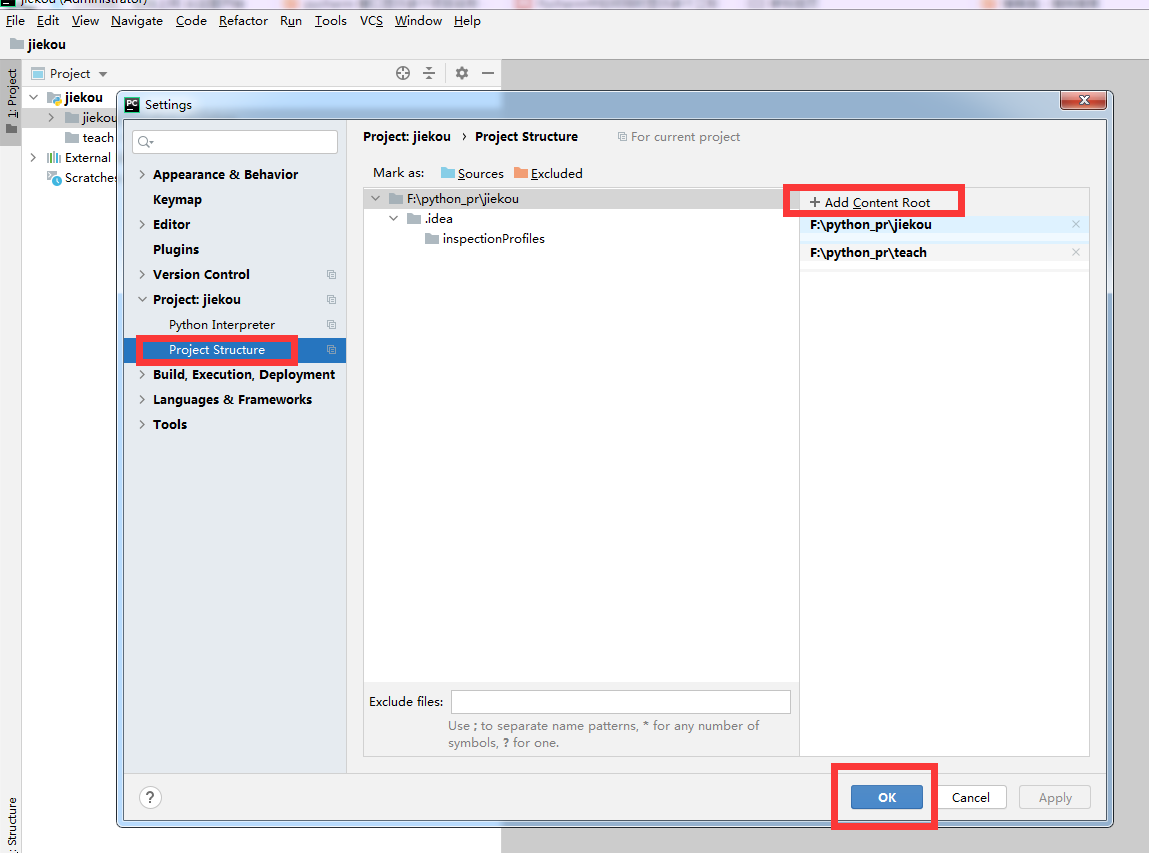
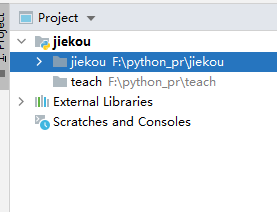
Pycharm中如何同时显示多个工程名?(python接口自动化)
第一步
第二步
第三步:完成
查看全文
相关阅读:
HashMap put原理详解(基于jdk1.8)
适合 C++ 新手学习的开源项目——在 GitHub 学编程
连续肝了好几天,终于把Java面试必备最重要的基础知识【Java集合】知识点总结整理出来了。
「精选」史上最全Java工程师面试题汇总,没有之一,不接受反驳!
想拿到10k-40k的offer,这些技能必不可少!作为程序员的你了解吗?
QuickBI助你成为分析师-数据建模(一)
Java Web整合开发(36) -- Web Service框架XFire
查找
CentOS7下RabbitMQ服务安装配置
php rabbitmq操作类及生产者和消费者实例代码 转
原文地址:https://www.cnblogs.com/fanxianhua/p/13884604.html
最新文章
48万奖金等你瓜分! 2019华为开发者大赛全栈开放!
项目中常用的19条MySQL优化
DevOps组织I&O专业人员新角色分析与技能提升
智能大航海时代,华为云持续推进全球数字化进程
【nodejs原理&源码赏析(4)】深度剖析cluster模块源码与node.js多线程(上)
80万辆车“云上飞驰”的背后
是时候理解下HTTPS及背后的加密原理了
Spring Boot 最流行的 16 条实践解读!
一个经典面试题:如何保证缓存与数据库的双写一致性?
00032_ArrayList集合的遍历
热门文章
CentOS, FreeBSD, Ubuntu LTS 维护风格的简单比较
例说Linux内核链表(一)
近期对招聘Android开发者的一些思考
设计模式C++实现——模板方法模式
Codeforces Round #207 (Div. 1) B. Xenia and Hamming(gcd的运用)
.net批量下载文件
来晚了,秋招五投大厂,成功拿下三家Offer,最终入职美团,分享我的美团1-4面(Java岗)
Fastjson常用API
Java.awt实现一个简单的围棋
简单工厂模式
Copyright © 2011-2022 走看看