此文转载自:https://blog.csdn.net/weixin_49631226/article/details/110247453#commentBox
前言
本文是个人对Hashmap的一些个人见解,主要通过使用hashmap put的一些代码来阐述其底层实现原理,在面试中也会经常会用到,如有不对的地方望大家指正。
(1)先描述一下hashmap的一个底层数据结构:
Hashmap底层是由数组和链表结合实现的。如下图:
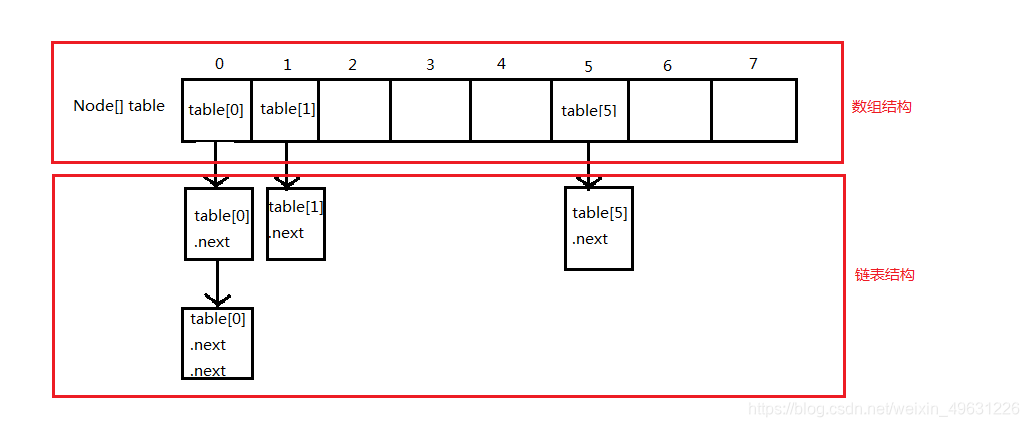
其中每个table[x](或table[x].next...)都是一个node,都是一个插入的元素
Node实体类为:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}可以看到有四个参数:hash(hash值)、key(我们平常put的key)、value(put的value)、next(hashMap数据结构图中的.next,也就是记录链表中每个元素的后继元素)
1.创建hashmap对象:Map<String,Object> map = new HashMap<>();
创建一个map对象,对象中的一些参数属性被赋予默认值,主要有参考容量(capacity)、扩容阈值(threshold)和负载因子(loadFactor),下面简单介绍一下这些参数属性的作用和关系。
(1)参考容量(capacity)
用来作为创建map对象中Node[]数组的初始长度(容量)的参考,默认为16。
可以自己指定长度,指定方式为:Map<String,Object> map = new HashMap<>(capacity);//capacity的值就是你要指定的长度
这里之所以说是参考,是因为hashmap内部有一个机制:创建map对象中Node[]数组的初始长度必须要是2的n次方(原因在2.(3)),当你设置长度是23的时候,hashmap会把初始长度设置成32。因为23在16(2的4次方)到32(2的5次方)之间,取最大的数32。
(2) 扩容阈值(threshold)和负载因子(loadFactor)
hashmap在新增元素的过程中,如果达到扩容阈值,就会扩大Node[]数组的长度
其默认值为:参考容量 * 负载因子
而负载因子的默认值为0.75,可以修改但是不建议修改。
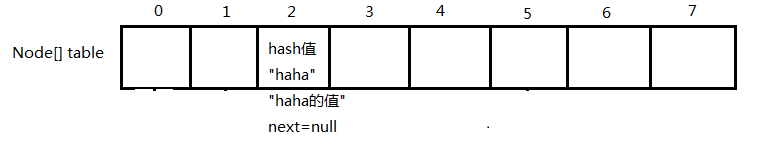
2.首次put:map.put("haha","haha的值");
将"haha的值"插入到"haha"的键的node中。
这里可以带几个问题:
元素要想把值插到数组+链表的结构中的话,首先要接触数组,然后再接触链表
那我们怎么知道要把元素放在数组的哪个位置(数组下标怎么得到)?
什么情况下会把元素放在链表里?
(1)计算出"haha"的hash值
int hash = hash("haha");(2)判断数组是否为空
判断Node[]数组是否为空,为空的话按照初始长度开辟数组空间
(3)对hash值作减一与运算得到数组下标
直接算出来的hash值可能非常大,不可能直接当作数组下标的。对此hashmap的设计者有自己的解决方案:求余
也就是:index = hash值 % 数组长度
这样的话index的值永远都在数组长度之内,也就可以作为数组下标了
但是这样做有一个缺点:效率低,于是hashmap的设计者把求余改成了一个效率更高的运算:减一与运算
也就是:index = hash值 & (数组长度-1)
为什么这样得出来的index也在数组长度之内呢?可以看下例子(由于是位运算,需要把hash值和数组长度分解成二进制,这样看的更清楚,假设它两二进制只有八位):
数组长度: 0001 0000
数组长度-1: 0000 1111
hash值: 1101 0101
与操作: 0000 0101
可以看到,数组长度-1后,前四位变成了0,跟hash值作与操作之后,hash值前四位不管是什么,都会变成0,而后四位由于对方都是1,因此得以保留下来。这样得到最后的结果永远都不会超过数组长度。
这里必须要满足一个前提条件:数组长度必须要是2的n次方。因为这样才能保证数组长度-1之后,前面为0,后面为1。
(4)把值赋给对应的node
数组下标拿到了,要插入的位置也就基本确定了。在插入之前,hashmap会去判断当前数组位置上有没有元素,由于我们这是第一次插入,因此这里就是直接插入元素。
这里插入的方式很简单,就是把node的四大参数(hash值、key、value、next)赋给当前数组位置上的node。由于是位置上第一个元素,后继没有链表元素,next的值就是null。
(5)插入后操作
插入之后,hashmap的全局变量:size,也就是已有元素数量,加一,然后看下有没有大于扩容阈值,如果大的话就要扩容。
(6)最终效果(这里设"haha"算出的index为2)
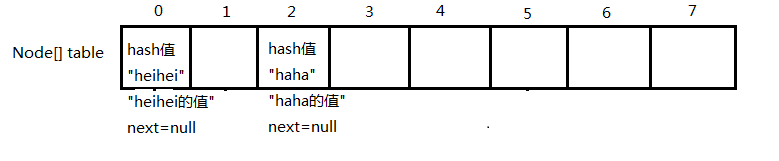
3.put不同key不同index的值:map.put("heihei","heihei的值");
这里的过程和2.一样,最终结果为(这里设"heihei"算出的index为0):
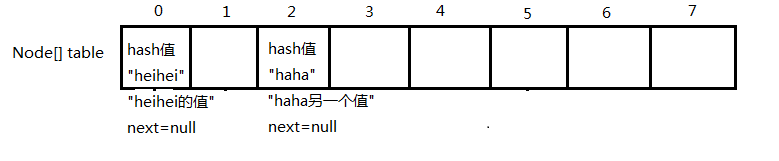
4.put相同key的值:map.put("haha","haha另一个值");
这里得到数组下标值之后,发现位置上已经有元素了,这种情况就叫做哈希碰撞
这时候,就要看看这个位置上的元素是不是同一个key,是的话就覆盖,不是的话就追加到后继链表——这就是链表的作用
怎么判断是不是同一个key呢?
(1)hash值是否相等
首先要看看计算出来的hash值是否相等,这里算出来的是相等的。
(2)两个key是否相等
hash值相等,两个key不一定相等,因为算hash值需要调用hashCode()方法,这个方法我们是可以自己复写的,可能会出现很多不同结果相等的情况。
所以我们需要通过"=="和equals()来判断两个key是否相等。这里算出来的是相等的。
为什么不直接判断是否相等,而还要先判断hash值?
因为hash值不相等,那肯定不是同一个key。算hash值相对来说速度快点,有这个先把关会大大提高效率,而不是上来就==和equals。
(3)覆盖原值
判断是同一个key,那就直接覆盖原值就行了,最终结果为:
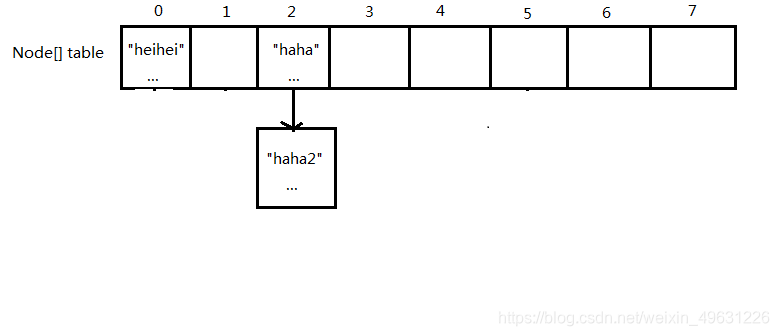
5.首次put不同key相同index的值:map.put("haha2","haha2的值")
这里假设"haha2"算出来的index和"haha"一样。
在这个前提下,自然就会出现哈希碰撞。这时候的过程也是和4.一样,区别在于在比对key的时候,发现两个key的hash值不相等,也就不是同一个key
之后自然会把这个元素插到"haha"元素后面形成链表
插入的方式很简单,就是把"haha2"元素赋给"haha"的next,"haha2"的next为null
最终结果为:
这里插入之前会进行一些判断,比如是否是红黑树等等,后面的情况会细讲。
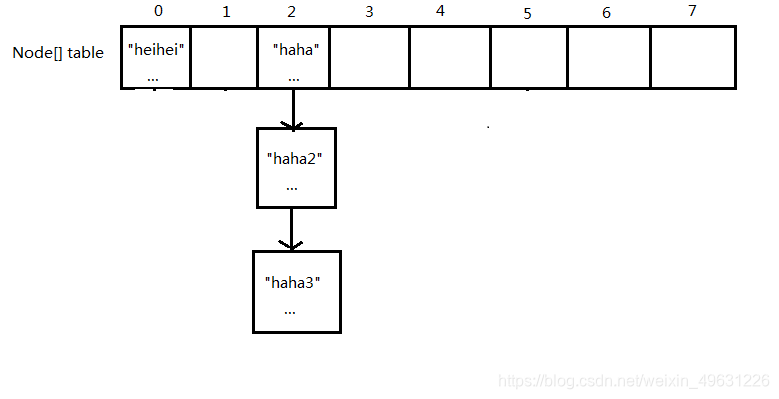
6.继续put不同key相同index的值:map.put("haha3","haha3的值")
这里假设"haha3"算出来的index和"haha"一样。
过程和5.一样,区别在于在比对的时候,会遍历当前数组位置上链表的所有元素,如果发现相同key则覆盖,没有相同key就追加到链表后面。
最终结果为:
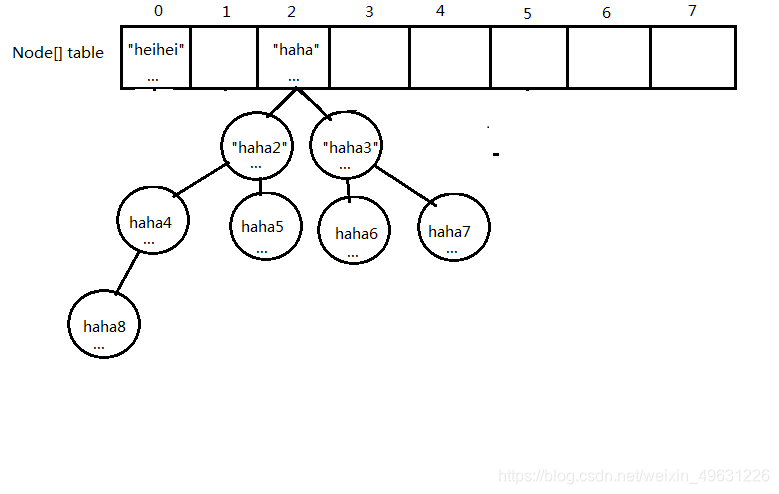
7.put到链表转成红黑树:map.put("haha8","haha8的值")
这里假设"haha8"算出来的index和"haha"一样。
这里假设链表上的元素已经有7个了。
前面我们发现,随着put的元素越来越多,哈希碰撞的次数也越来越频繁,导致链表会越来越长,这样每次put要遍历的元素也越来越多,会让hashmap的性能越来越差。
(1)链表转成红黑树
于是红黑树的解决方案就出现了。红黑树是一种能让遍历的效率更高的一种数据结构。
当链表的元素数量达到8的时候,当前链表自动转成红黑树的形式存储,能大大提升遍历效率。
(2)扩容机制
除了红黑树,还有没有什么解决方案可以提高性能呢?
有——扩容机制
之所以链表越来越长,是因为哈希碰撞的次数太频繁了。那我们可以通过降低这种次数来提升性能。扩容可以做到这一点。
扩容是增加数组的长度,这样我们就有更多的空间去分配链表的位置,哈希碰撞的次数就会少很多。
类似于我们去餐厅吃饭,位置越多我们吃上饭的概率就越大,而不用老是等位(遍历)。
hashmap的扩容过程简单来说就是新建一个长度为原来2倍(因为要满足2的n次方)的数组Node[],然后把旧数组+链表上的元素全部转移到新的Node[]上
链表长度为8的时候一定会转成红黑树吗?
不一定,如下代码:
if (tab == null || (n = tab.length) < 64) resize(); else //转成红黑树可以看到会先做判断,满足扩容条件会先扩容,不扩容再转成红黑树。
(3)最终效果("haha8"put进去对应链表转成了红黑树)
8.总结
Hashmap 执行put的时候有以下几个步骤:
