原来文本匹配的方式一直是用中规中矩的正则来做,最近在实际生产中由于数据量骤升,现有数据量提高了大约 3-4 倍,原本使用正则处理已经到了瓶颈,这次又有增量对生产来说可谓雪上加霜,而且随着正则词越加越多,匹配效率也越来越差,数据量的激增再加上正则词越加越多,提升生产的匹配效率已是迫在眉睫。
最近一段时间我也一直再搞这部分,现在初见成效,在测试新方法匹配过程中,发现有的长正则匹配效率甚至提高了 100 倍,而且是越长文本 越长正则 提升越高。
本次就来聊聊这次优化正则的经历,需要代码的朋友直接到文末下载即可。
1 准备阶段:AC多模匹配
在谈优化正则前,我们先要知道 AC多模匹配 的概念,AC 多模匹配重点在于 字典树 和 它的失败节点匹配算法(KMP模式匹配),字典树我们都很熟悉,假设有 "aaa ,abc,bcd,cab,cad" 这几个字符串需要存储,它们在字典树中的位置这里以一张图做个简单的示意:
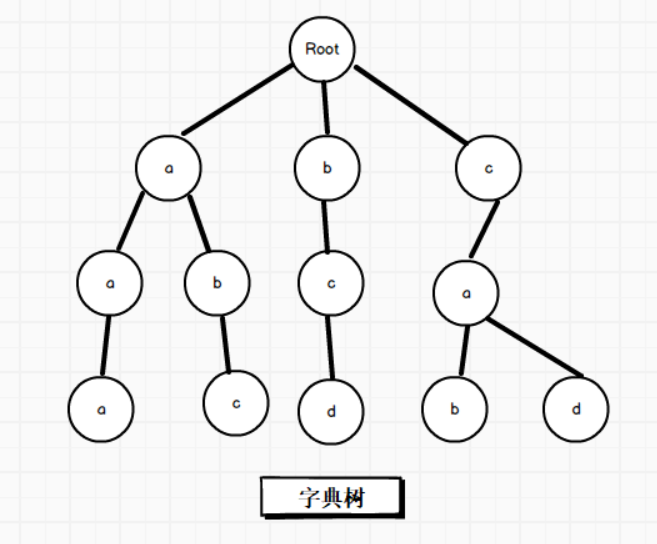
而设置失败指针后的示意图如下所示:
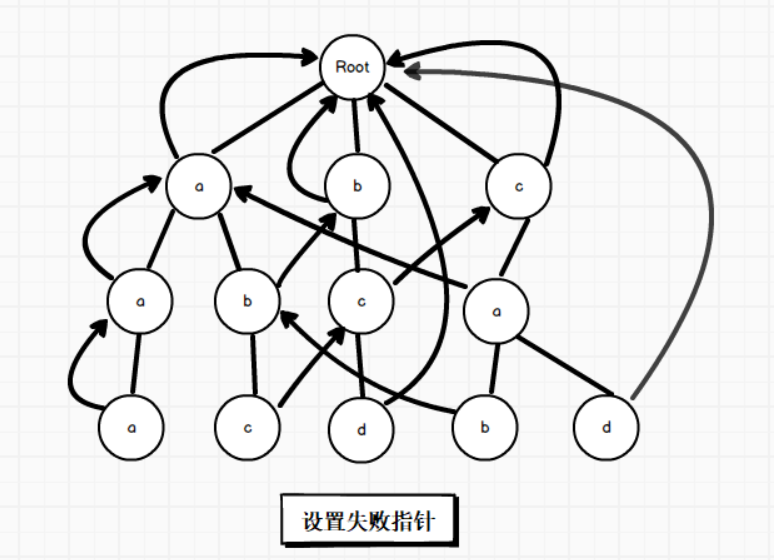
可以看到通过AC多模的方式进行匹配明显比普通遍历式查找效率要高,它将查找方式变为纵向,并且失败指针的引入使得一条分支匹配失败后不用再回到起点,顺着失败指针继续查找,如果沿着失败指针一直找到根节点都没找到,那说明在字典树中肯定没有这个字符。
2 改造阶段:正则拆分
正则拆分举例:
长正则实例(截取了代码中的一部分):
.*(网站|中断|网络传输|非正常(停|死)机|异常(停|死)机|滥用.{0,4}职权|why.?china|(翻译|拼写|书写|标志|标示|导航)(错误|不清楚|不清晰|无法辨别|模糊)){6,}.*
将以上正则拆分为两部分:
- 只有关键词部分 不带任何其他符号
示例正则拆分后只有关键词部分:
网站 中断 网络传输
- 不包含关键词的短正则
示例正则拆分的短正则部分:
非正常(停|死)机、异常(停|死)机、滥用.{0,4}职权、why.?china、(翻译|拼写|书写|标志|标示|导航)(错误|不清楚|不清晰|无法辨别|模糊)
针对只有关键词部分正则可以进行匹配优化,思路是使用 AC 多模树 匹配计数,可以看到正则最后面会标明 关键词 出现次数,{6,} 表示正则中各个关键词只要出现 6 次即可
针对拆分出的短正则,则继续使用正则常规的 Match 方法即可。
3 改造阶段:创建 AC 多模树,加载正则词
之前说过 AC 多模树重点在于 字典树和 失败匹配算法。
字典树的结构大家应该都比较熟悉,主要分为 Trie 类 和 Node 类,Tire 可以看作是树,Node 可以看作是树的节点,详细代码可在文末下载,这里我们着重看下设置失败指针的方法。
设置失败指针其实只有 两步 :
- 将深度为 1 的节点的失败指针直接指向父节点也就是根节点
- 为深度 > 1 的节点建立失败指针
构造失败指针的过程概况如下:
设一个节点的上的值为 c ,记为 start 节点 ,沿着它父节点的失败指针走,知道走到一个节点它的儿子节点中也有值为 c 的节点,将儿子节点记为 end 节点。
然后把 start 节点的失败指针指向 end 节点即可。如果一直走到 root 节点都没有找到,那就把 start 节点的失败指针指向 root 节点。
为了方便查看,我将上面的设置失败指针的图再拿下来,以深度3中的值为C的节点为例,走一下它的失败指针:

记 深度3中的值为C 的节点 为 start,沿着它父节点(深度为2的值为b的节点)的失败指针走,找到深度为1的值为b的节点,发现它的儿子节点中也有值为C的节点,儿子节点记为 end 节点,此时将 start 节点的失败指针指向 end 节点即可。
同理,深度3中的值为b的节点设置过程也是如此,d 节点由于一直找到根节点都没有匹配,所以它的失败指针指向了根节点。
4 实战阶段:两种方式进行,对比结果
使用普通正则耗时结果:

使用AC 多模耗时结果:

图片对比看到在文本长度一致情况下,两者耗时差了一个量级,效率提升几十倍。
而一些更长的正则优化后效率甚至提升了不止 100 倍。
总结一下:
对于长文本匹配长正则的情况使用常规的正则匹配方式还是比较耗时的,所以还是推荐将长正则拆分,使用 AC多模匹配的方式。
注意有的时候正则逻辑比较复杂,可能会有包含词、逻辑与或的关系,在拆分的时候要注意前后匹配的结果,优化效率的前提肯定是结果的正确性,不能为了优化而优化,如果导致了错误的结果就南辕北辙了。
参考资料 :关注公众号"大数据江湖", 后台回复 "正则优化",获取完整项目代码。
![]()
-- THE END --