预测酸奶日销量 y,x1 和 x2 是影响日销量的两个因素。应提前采集的数据有:一段时间内,每日的 x1 因素、x2 因素和销量 y_。采集的数据尽量多。
在本例中用销量预测产量,最优的产量应该等于销量。由于目前没有数据集,所以拟造了一套数据集。利用 Tensorflow 中函数随机生成 x1、 x2,制造标准答案 y_ = x1 + x2,为了更真实,求和后还加了正负 0.05 的随机噪声。
我们把这套自制的数据集喂入神经网络,构建一个一层的神经网络,拟合预测酸奶日销量的函数。
#coding:utf-8 #预测多或预测少的影响一样 #0导入模块,生成数据集 import tensorflow as tf import numpy as np BATCH_SIZE = 8 SEED = 23455 rdm = np.random.RandomState(SEED)#基于seed产生随机数,产生数据集 X = rdm.rand(32,2)#随机数返回300行2列的矩阵,表示300组坐标点 Y_ = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X]#判断如果两个坐标的平方和小于2,给Y赋值1,其余赋值0 #1定义神经网络的输入、参数和输出,定义前向传播过程。 x = tf.placeholder(tf.float32, shape=(None, 2))#占位 y_ = tf.placeholder(tf.float32, shape=(None, 1))#占位 w1= tf.Variable(tf.random_normal([2, 1], stddev=1, seed=1))#正态分布 y = tf.matmul(x, w1)#点积 #2定义损失函数及反向传播方法。 #定义损失函数为MSE,反向传播方法为梯度下降。 loss_mse = tf.reduce_mean(tf.square(y_ - y)) train_step = tf.train.GradientDescentOptimizer(0.001).minimize(loss_mse) #3生成会话,训练STEPS轮 with tf.Session() as sess: init_op = tf.global_variables_initializer()#初始化 sess.run(init_op)#初始化 STEPS = 20000#20000轮 for i in range(STEPS): start = (i*BATCH_SIZE) % 32 end = (i*BATCH_SIZE) % 32 + BATCH_SIZE sess.run(train_step, feed_dict={x: X[start:end], y_: Y_[start:end]}) if i % 500 == 0: print ("After %d training steps, w1 is: " % (i)) print (sess.run(w1), " ") print ("Final w1 is: ", sess.run(w1))
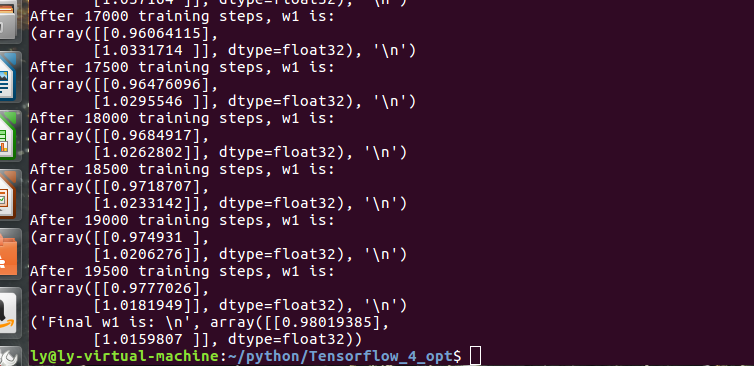
y=w1*x1+w2*x2;标准值是:y=x1+x2;
最后运行结果可知:y=0.977*x1+1.015*x2;符合标准