1 Using lxml 2 By default this library uses Python's standard ElementTree module for parsing XML, but it can be configured to use lxml module instead when importing the library. The resulting element structure has same API regardless which module is used for parsing. 3 The main benefits of using lxml is that it supports richer xpath syntax than the standard ElementTree and enables using Evaluate Xpath keyword. It also preserves the doctype and possible namespace prefixes saving XML. 4 The lxml support is new in Robot Framework 2.8.5.
Robot framework--内置库xml学习(一)
学习XML内置库,我认为需要掌握以下几个知识点:
第一:内置库的概念?有哪些内置库,大概都有什么关键字?有区分版本吗?跟RF版本有关么?为什么内置库有些需要import,有些不需要import?
第二:XML内置库使用的是python的哪个标准库?对这个标准库需要有哪些基本的了解?
第三:内置库是怎么构建起来的?基本关键字是否能灵活的使用?
第四:有时候可能需要稍微修改下内置库,比如增加一些关键字等,该怎么修改?
1、内置库的概念
内置库在官网上称为standard library,即标准库;其他比如:seleniumlibrary、androidlibrary等,官网称为external library,即外部库,第三方库。
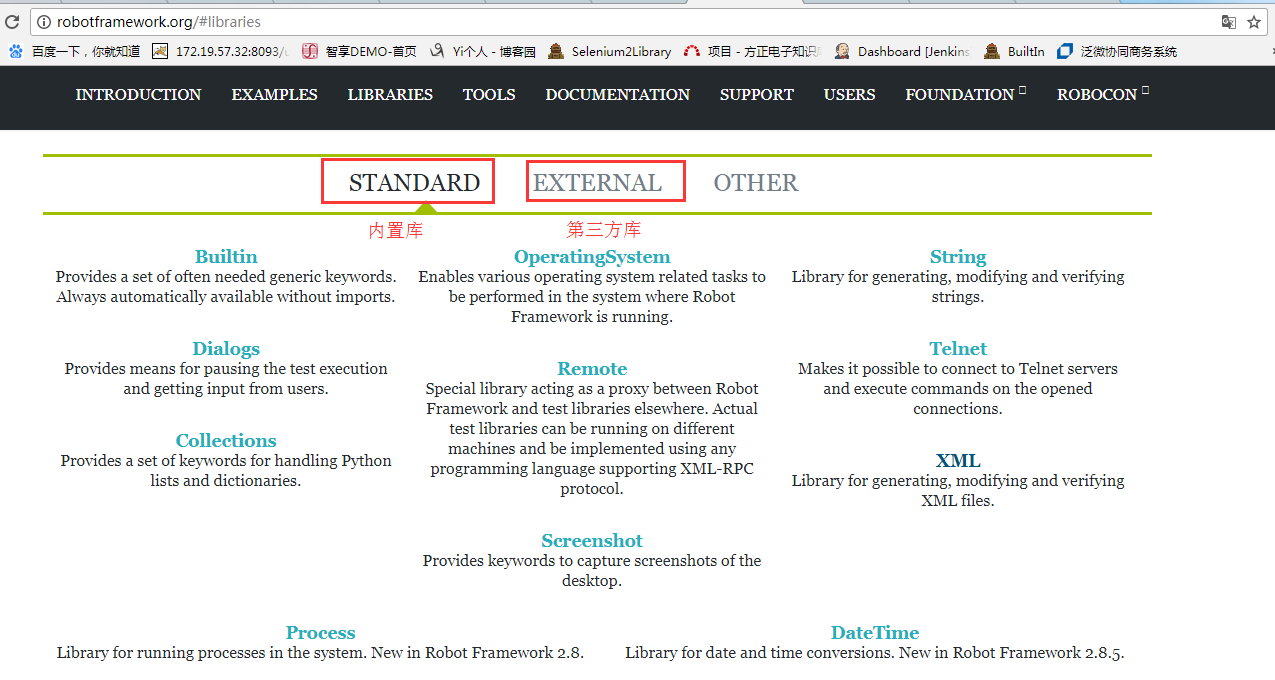
(1)对于标准库,这些库直接绑定在robot framework内,在python安装目录下libsite-packages
obotlibraries下可以看到,无需在下载。
(2)对于外部库,需要根据个人或者公司需要,下载之后安装导入才能使用的。
对于标准库,又分两类,类似于builtin库是robot framework自动加载到内存的,安装后按下F5就能直接使用,不需要import;而xml库需要在再次import才能正常使用。因为BuiltIn library 提供了很多常用的关键字,比如Should Be Equal,Convert To Integer等,所以RF就把这个常用的库自动加载到了内存。
不同版本的RF,支持不同的内置库而且相同的内置库里的关键字可能也是不一样的,以RF3.0(使用命令robot --version查看RF版本)为例,3.0是目前最新的RF的版本,支持很多的内置库,查看python安装目录下Libsite-packages obot下的py文件,可以看到:
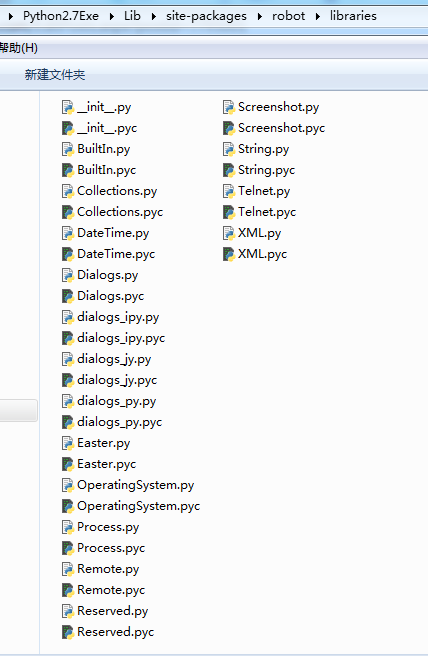
基本官网写的10个标准库都能在这里面找到相应的py文件。BuiltIn,Collections,DateTime,Dialogs,Process,OperatingSystem,Remote(没有关键字,暂时不算在内),Screenshot,String,Telnet,XML.这11个库,有些是在RF2.0的时候就已经有了的,最晚的DateTime,Process,XML是在RF2.8之后才内置的,也就是说如果当前使用的是RF2.8之前的版本,内置库是无法直接import XML就是使用的,需要下载安装才能使用,这点需要注意下,不同的RF版本,相同的标准库之间也是会细微的区别,这需要仔细的去查看保准库内每个版本的使用文档。

2、11个标准库的简介

这个表的来源是来自官网的,官网的用户手册文档已经描述的非常详细了。学习的时候可以详细的查看官网的相关文档。
3、XML内置库的学习
从内置库的XML的源码可以看出,RF使用的是ETree来对xml进行解析的,部分源码如下:
1 import copy 2 import re 3 import os 4 5 try: 6 from lxml import etree as lxml_etree 7 except ImportError: 8 lxml_etree = None 9 10 from robot.api import logger 11 from robot.libraries.BuiltIn import BuiltIn 12 from robot.utils import (asserts, ET, ETSource, is_string, is_truthy, 13 plural_or_not as s) 14 from robot.version import get_version 15 16 17 should_be_equal = asserts.assert_equal 18 should_match = BuiltIn().should_match 19 20 21 class XML(object): 22 ROBOT_LIBRARY_SCOPE = 'GLOBAL' 23 ROBOT_LIBRARY_VERSION = get_version() 24 _xml_declaration = re.compile('^<?xml .*?>') 25 def __init__(self, use_lxml=False): 26 use_lxml = is_truthy(use_lxml) 27 if use_lxml and lxml_etree: 28 self.etree = lxml_etree 29 self.modern_etree = True 30 self.lxml_etree = True 31 else: 32 self.etree = ET 33 self.modern_etree = ET.VERSION >= '1.3' 34 self.lxml_etree = False 35 if use_lxml and not lxml_etree: 36 logger.warn('XML library reverted to use standard ElementTree ' 37 'because lxml module is not installed.') 38 39 40 def parse_xml(self, source, keep_clark_notation=False): 41 with ETSource(source) as source: 42 tree = self.etree.parse(source) 43 if self.lxml_etree: 44 strip = (lxml_etree.Comment, lxml_etree.ProcessingInstruction) 45 lxml_etree.strip_elements(tree, *strip, **dict(with_tail=False)) 46 root = tree.getroot() 47 if not is_truthy(keep_clark_notation): 48 NameSpaceStripper().strip(root) 49 return root
python提供了几个标准库都可以对xml进行解析,之前我使用的是DOM,基于RF使用的是ETree,便开始学习了下ETree的开发文档。学习对XML文件的操作,那肯定也得对XML本身有最基本的了解,比如XML的用途,树结构,节点类型(DOM),带命名空间的xml。下面是部分的知识点的总结:
xml是一种可扩展的标记语言。要求标记需要成对的出现(有时候会进行简写<b/>)。一个典型的xml文档如下所示:
1 <example> 2 <first id="1">text</first> 3 <second id="2"> 4 <child/> 5 </second> 6 <third> 7 <child>more text</child> 8 <second id="child"/> 9 <child><grandchild/></child> 10 </third> 11 </example>
A. 整个xml文档是一个文档节点,属于根节点,比如上述文档的<example>节点就是一个根节点,一个xml文件只能有一个根节点,否则解析的时候胡报错的
B.每个 XML 标签是一个元素节点,比如<first> 和<second>, <third>都属于元素节点,却属于<example>的子节点。
C.attribute值:表示节点元素的属性值,比如first 有一个属性id,属性值为1;second也有id属性,属性值为2,而third没有属性。
D.Text值:表示元素中的文本内容。比如:first 的text值就为1;second没有,third也没有;
一个xml还包含其他的内容:比如处理指令和一些注释;在python的etree标准库解析的过程中,是直接把这二个给剔除掉了。有兴趣的可以根据官网给出的开发文档,把常用的一些方法都敲一遍,主要的还是使用2个类 Element Objects和ElementTree Objects。
4、xml官网学习
1 XML 2 3 Library version: 3.0.2 4 Library scope: global 5 Named arguments: supported 6 Introduction 7 8 Robot Framework test library for verifying and modifying XML documents. 9 As the name implies, XML is a test library for verifying contents of XML files. In practice it is a pretty thin wrapper on top of Python's ElementTree XML API. 10 The library has the following main usages: 11 Parsing an XML file, or a string containing XML, into an XML element structure and finding certain elements from it for for further analysis (e.g. Parse XML and Get Element keywords). 12 Getting text or attributes of elements (e.g. Get Element Text and Get Element Attribute). 13 Directly verifying text, attributes, or whole elements (e.g Element Text Should Be and Elements Should Be Equal). 14 Modifying XML and saving it (e.g. Set Element Text, Add Element and Save XML). 15 Table of contents 16 Parsing XML 17 Using lxml 18 Example 19 Finding elements with xpath 20 Element attributes 21 Handling XML namespaces 22 Boolean arguments 23 Shortcuts 24 Keywords
介绍Robot Framework测试库,用于验证和修改XML文档。顾名思义,XML是用于验证XML文件内容的测试库。 实际上,它是Python的ElementTree XML API的一个非常薄的包装器。库有以下主要用途:将XML文件或包含XML的字符串解析为XML元素结构,并从中找出某些元素以供进一步分析(例如,解析XML和获取元素关键字)。获取元素的文本或属性(例如获取元素文本和获取元素属性)。直接验证文本,属性或整个元素(例如元素文本应该与元素应该相等)。修改XML并保存(例如设置元素文本,添加元素和保存XML)。
1 Parsing XML 2 XML can be parsed into an element structure using Parse XML keyword. It accepts both paths to XML files and strings that contain XML. The keyword returns the root element of the structure, which then contains other elements as its children and their children. Possible comments and processing instructions in the source XML are removed. 3 XML is not validated during parsing even if has a schema defined. How possible doctype elements are handled otherwise depends on the used XML module and on the platform. The standard ElementTree strips doctypes altogether but when using lxml they are preserved when XML is saved. With IronPython parsing XML with a doctype is not supported at all. 4 The element structure returned by Parse XML, as well as elements returned by keywords such as Get Element, can be used as the source argument with other keywords. In addition to an already parsed XML structure, other keywords also accept paths to XML files and strings containing XML similarly as Parse XML. Notice that keywords that modify XML do not write those changes back to disk even if the source would be given as a path to a file. Changes must always saved explicitly using Save XML keyword. 5 When the source is given as a path to a file, the forward slash character (/) can be used as the path separator regardless the operating system. On Windows also the backslash works, but it the test data it needs to be escaped by doubling it (\). Using the built-in variable ${/} naturally works too. 6 解析XML 7 可以使用Parse XML关键字将XML解析为元素结构。它接受XML文件和包含XML的字符串的路径。关键字返回结构的根元素,然后包含其他元素作为其子元素和子元素。源XML中的可能注释和处理指令将被删除。 8 即使定义了模式,XML在分析过程中也不会被验证。如何处理doctype元素,否则取决于使用的XML模块和平台。标准ElementTree完全去除doctypes,但是当使用lxml时,保存XML时会保留它们。 IronPython用doctype解析XML根本不被支持。 9 由Parse XML返回的元素结构以及由Get Element等关键字返回的元素可用作其他关键字的源参数。除已经解析的XML结构之外,其他关键字也接受XML文件的路径和包含XML的字符串,类似于解析XML。请注意,修改XML的关键字不会将这些更改写回到磁盘,即使源将作为文件的路径提供。必须始终使用保存XML关键字保存更改。 10 当源被指定为文件的路径时,无论操作系统如何,正斜杠字符(/)都可以用作路径分隔符。在Windows上,反斜杠也可以工作,但是它需要通过加倍(\)来转义测试数据。使用内置变量$ {/}自然也可以。
使用lxml
默认情况下,这个库使用Python的标准ElementTree模块来解析XML,但是当导入库时,它可以被配置为使用lxml模块。 无论使用哪个模块解析,生成的元素结构都具有相同的API。
使用lxml的主要好处是它支持比标准ElementTree更丰富的xpath语法,并支持使用Evaluate Xpath关键字。 它还保留了doctype和保存XML的可能的名称空间前缀。
lxml支持是Robot Framework 2.8.5中的新功能。
1 Example 2 The following simple example demonstrates parsing XML and verifying its contents both using keywords in this library and in BuiltIn and Collections libraries. How to use xpath expressions to find elements and what attributes the returned elements contain are discussed, with more examples, in Finding elements with xpath and Element attributes sections. 3 In this example, as well as in many other examples in this documentation, ${XML} refers to the following example XML document. In practice ${XML} could either be a path to an XML file or it could contain the XML itself. 4 <example> 5 <first id="1">text</first> 6 <second id="2"> 7 <child/> 8 </second> 9 <third> 10 <child>more text</child> 11 <second id="child"/> 12 <child><grandchild/></child> 13 </third> 14 <html> 15 <p> 16 Text with <b>bold</b> and <i>italics</i>. 17 </p> 18 </html> 19 </example> 20 ${root} = Parse XML ${XML} 21 Should Be Equal ${root.tag} example 22 ${first} = Get Element ${root} first 23 Should Be Equal ${first.text} text 24 Dictionary Should Contain Key ${first.attrib} id 25 Element Text Should Be ${first} text 26 Element Attribute Should Be ${first} id 1 27 Element Attribute Should Be ${root} id 1 xpath=first 28 Element Attribute Should Be ${XML} id 1 xpath=first 29 Notice that in the example three last lines are equivalent. Which one to use in practice depends on which other elements you need to get or verify. If you only need to do one verification, using the last line alone would suffice. If more verifications are needed, parsing the XML with Parse XML only once would be more efficient.
例
下面的简单示例演示解析XML并验证其内容,使用此库中的关键字以及BuiltIn和Collections库中的关键字。讨论如何使用xpath表达式来查找元素以及返回元素包含的属性,以及使用xpath和Element属性部分查找元素的更多示例。
在本例中,以及本文档中的许多其他示例中,$ {XML}引用以下示例XML文档。实际上,$ {XML}既可以是XML文件的路径,也可以包含XML本身。
<实例>
<first id =“1”>文字</ first>
<second id =“2”>
<子/>
</秒>
<第三>
<child>更多文字</ child>
<second id =“child”/>
<子> <孙子/> </子>
</第三>
<HTML>
<P>
带有<b>粗体</ b>和<i>斜体</ i>的文本。
</ p>
</ HTML>
</示例>
$ {root} =解析XML $ {XML}
应该是等于$ {root.tag}的例子
$ {first} =首先获取元素$ {root}
应该等于$ {first.text}文本
字典应包含密钥$ {first.attrib} id
元素文本应该是$ {first}文本
元素属性应该是$ {first} id 1
元素属性应该是$ {root} id 1 xpath = first
元素属性应该是$ {XML} id 1 xpath = first
注意在这个例子中最后三行是等价的。在实践中使用哪一个取决于您需要获取或验证的其他元素。如果您只需要进行一次验证,单单使用最后一行就足够了。如果需要更多的验证,只用解析XML解析XML将会更有效率。
1 Finding elements with xpath 2 ElementTree, and thus also this library, supports finding elements using xpath expressions. ElementTree does not, however, support the full xpath syntax, and what is supported depends on its version. ElementTree 1.3 that is distributed with Python 2.7 supports richer syntax than earlier versions. 3 The supported xpath syntax is explained below and ElementTree documentation provides more details. In the examples ${XML} refers to the same XML structure as in the earlier example. 4 If lxml support is enabled when importing the library, the whole xpath 1.0 standard is supported. That includes everything listed below but also lot of other useful constructs. 5 Tag names 6 When just a single tag name is used, xpath matches all direct child elements that have that tag name. 7 ${elem} = Get Element ${XML} third 8 Should Be Equal ${elem.tag} third 9 @{children} = Get Elements ${elem} child 10 Length Should Be ${children} 2 11 Paths 12 Paths are created by combining tag names with a forward slash (/). For example, parent/child matches all child elements under parent element. Notice that if there are multiple parent elements that all have child elements, parent/child xpath will match all these child elements. 13 ${elem} = Get Element ${XML} second/child 14 Should Be Equal ${elem.tag} child 15 ${elem} = Get Element ${XML} third/child/grandchild 16 Should Be Equal ${elem.tag} grandchild 17 Wildcards 18 An asterisk (*) can be used in paths instead of a tag name to denote any element. 19 @{children} = Get Elements ${XML} */child 20 Length Should Be ${children} 3 21 Current element 22 The current element is denoted with a dot (.). Normally the current element is implicit and does not need to be included in the xpath. 23 Parent element 24 The parent element of another element is denoted with two dots (..). Notice that it is not possible to refer to the parent of the current element. This syntax is supported only in ElementTree 1.3 (i.e. Python/Jython 2.7 and newer). 25 ${elem} = Get Element ${XML} */second/.. 26 Should Be Equal ${elem.tag} third 27 Search all sub elements 28 Two forward slashes (//) mean that all sub elements, not only the direct children, are searched. If the search is started from the current element, an explicit dot is required. 29 @{elements} = Get Elements ${XML} .//second 30 Length Should Be ${elements} 2 31 ${b} = Get Element ${XML} html//b 32 Should Be Equal ${b.text} bold 33 Predicates 34 Predicates allow selecting elements using also other criteria than tag names, for example, attributes or position. They are specified after the normal tag name or path using syntax path[predicate]. The path can have wildcards and other special syntax explained above. 35 What predicates ElementTree supports is explained in the table below. Notice that predicates in general are supported only in ElementTree 1.3 (i.e. Python/Jython 2.7 and newer). 36 Predicate Matches Example 37 @attrib Elements with attribute attrib. second[@id] 38 @attrib="value" Elements with attribute attrib having value value. *[@id="2"] 39 position Elements at the specified position. Position can be an integer (starting from 1), expression last(), or relative expression like last() - 1. third/child[1] 40 tag Elements with a child element named tag. third/child[grandchild] 41 Predicates can also be stacked like path[predicate1][predicate2]. A limitation is that possible position predicate must always be first.
用xpath查找元素
ElementTree,也就是这个库,支持使用xpath表达式查找元素。然而,ElementTree不支持完整的xpath语法,支持的内容取决于它的版本。与Python 2.7分布的ElementTree 1.3支持比早期版本更丰富的语法。
受支持的xpath语法如下所述,ElementTree文档提供了更多细节。在示例中,$ {XML}引用与前面示例中相同的XML结构。
如果在导入库时启用了lxml支持,则支持整个xpath 1.0标准。这包括下面列出的一切,但也有很多其他有用的结构。
标签名称
当仅使用单个标签名称时,xpath将匹配具有该标签名称的所有直接子元素。
$ {elem} =获取元素$ {XML}的三分之一
应该等于$ {elem.tag}第三
@ {children} =获取元素$ {elem}孩子
长度应该是$ {children} 2
路径
路径是通过将标记名称与正斜杠(/)组合来创建的。例如,父/子匹配父元素下的所有子元素。请注意,如果有多个父元素都具有子元素,则父/子xpath将匹配所有这些子元素。
$ {elem} =获取元素$ {XML}秒/子
应该是平等$ {elem.tag}孩子
$ {elem} =获取元素$ {XML}第三/子/孙
应该等于$ {elem.tag}孙子
通配符
星号(*)可用于路径而不是标签名称来表示任何元素。
@ {children} =获取元素$ {XML} * / child
长度应该是$ {children} 3
当前元素
当前元素用点(。)表示。通常,当前元素是隐式的,不需要包含在xpath中。
父元素
另一个元素的父元素用两个点(..)表示。请注意,不可能引用当前元素的父元素。这个语法仅在ElementTree 1.3(即Python / Jython 2.7和更新版本)中被支持。
$ {elem} =获取元素$ {XML} * /秒/ ..
应该等于$ {elem.tag}第三
搜索所有子元素
两个正斜杠(//)意味着搜索所有子元素,而不仅仅是直接子元素。如果搜索从当前元素开始,则需要一个明确的点。
@ {elements} =获取元素$ {XML}。// second
长度应该是$ {elements} 2
$ {b} =获取元素$ {XML} html // b
应该等于$ {b.text}大胆
谓词
谓词允许使用标记名称以外的其他标准来选择元素,例如属性或位置。它们是在使用语法path [predicate]的标准名称或路径之后指定的。路径可以有通配符和上面解释的其他特殊语法。
下表说明了ElementTree支持的谓词。请注意,一般来说谓词仅在ElementTree 1.3(即Python / Jython 2.7及更新版本)中受支持。
谓词匹配示例
@attrib具有属性attrib的元素。第二[@id]
@ attrib =“value”属性attrib具有值的元素。 * [@ ID = “2”]
在指定位置放置元素。位置可以是一个整数(从1开始),表达式last()或像last() - 1的相对表达式。third / child [1]
标签具有子元素名称标签的元素。第三/儿童[孙子]
谓词也可以像路径[predicate1] [predicate2]一样堆叠。一个限制是可能的位置谓词必须始终是第一位的。