求每一个订单中成交金额最大的那一笔 top1
数据
Order_0000001,Pdt_01,222.8
Order_0000001,Pdt_05,25.8
Order_0000002,Pdt_05,325.8
Order_0000002,Pdt_03,522.8
Order_0000002,Pdt_04,122.4
Order_0000003,Pdt_01,222.8
Order_0000003,Pdt_01,322.8
pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId> <artifactId>MapReduceCases</artifactId> <packaging>jar</packaging> <version>1.0</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> </properties> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.1.40</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.36</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <appendAssemblyId>false</appendAssemblyId> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>cn.itcast.mapreduce.top.one.TopOne</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>assembly</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
package cn.itcast.mapreduce.top.one; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; /** * * */ public class OrderBean implements WritableComparable<OrderBean> { private Text itemid; private DoubleWritable amount; public OrderBean() { } public OrderBean(Text itemid, DoubleWritable amount) { set(itemid, amount); } public void set(Text itemid, DoubleWritable amount) { this.itemid = itemid; this.amount = amount; } public Text getItemid() { return itemid; } public DoubleWritable getAmount() { return amount; } public int compareTo(OrderBean o) { int cmp = this.itemid.compareTo(o.getItemid()); if (cmp == 0) { cmp = -this.amount.compareTo(o.getAmount()); } return cmp; } public void write(DataOutput out) throws IOException { out.writeUTF(itemid.toString()); out.writeDouble(amount.get()); } public void readFields(DataInput in) throws IOException { String readUTF = in.readUTF(); double readDouble = in.readDouble(); this.itemid = new Text(readUTF); this.amount = new DoubleWritable(readDouble); } @Override public String toString() { return itemid.toString() + " " + amount.get(); } }
package cn.itcast.mapreduce.top.one; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * */ public class ItemidGroupingComparator extends WritableComparator { protected ItemidGroupingComparator() { super(OrderBean.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { OrderBean abean = (OrderBean) a; OrderBean bbean = (OrderBean) b; //��item_id��ͬ��bean����Ϊ��ͬ���Ӷ�ۺ�Ϊһ�� return abean.getItemid().compareTo(bbean.getItemid()); } }
package cn.itcast.mapreduce.top.one; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Partitioner; public class ItemIdPartitioner extends Partitioner<OrderBean, NullWritable> { @Override public int getPartition(OrderBean key, NullWritable value, int numPartitions) { //ָ return (key.getItemid().hashCode() & Integer.MAX_VALUE) % numPartitions; } }
package cn.itcast.mapreduce.top.one; import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.sun.xml.bind.v2.schemagen.xmlschema.List; /** * ����secondarysort�������ÿ��item����������ļ�¼ * * @author AllenWoon */ public class TopOne { static class TopOneMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> { OrderBean bean = new OrderBean(); /* Text itemid = new Text(); */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = StringUtils.split(line, ","); bean.set(new Text(fields[0]), new DoubleWritable(Double.parseDouble(fields[2]))); context.write(bean, NullWritable.get()); } } static class TopOneReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> { @Override protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // job.setJarByClass(TopOne.class); //告诉框架,我们的程序所在jar包的位置 job.setJar("/root/TopOne.jar"); job.setMapperClass(TopOneMapper.class); job.setReducerClass(TopOneReducer.class); job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); FileInputFormat.setInputPaths(job, new Path("/top/input")); FileOutputFormat.setOutputPath(job, new Path("/top/output1")); // FileInputFormat.setInputPaths(job, new Path(args[0])); // FileOutputFormat.setOutputPath(job, new Path(args[1])); // ָ��shuffle��ʹ�õ�GroupingComparator�� job.setGroupingComparatorClass(ItemidGroupingComparator.class); // ָ��shuffle��ʹ�õ�partitioner�� job.setPartitionerClass(ItemIdPartitioner.class); job.setNumReduceTasks(1); job.waitForCompletion(true); } }
创建文件夹
hadoop fs -mkdir -p /top/input
上传数据
hadoop fs -put top.txt /top/input
运行
hadoop jar TopOne.jar cn.itcast.mapreduce.top.one.TopOne
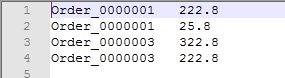
运行结果

topN
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId> <artifactId>MapReduceCases</artifactId> <packaging>jar</packaging> <version>1.0</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> </properties> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.1.40</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.36</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <appendAssemblyId>false</appendAssemblyId> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass>cn.itcast.mapreduce.top.n.TopN</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>assembly</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
package cn.itcast.mapreduce.top.n; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.WritableComparable; /** * ������Ϣbean��ʵ��hadoop�����л����� */ public class OrderBean implements WritableComparable<OrderBean> { private Text itemid; private DoubleWritable amount; public OrderBean() { } public OrderBean(Text itemid, DoubleWritable amount) { set(itemid, amount); } public void set(Text itemid, DoubleWritable amount) { this.itemid = itemid; this.amount = amount; } public Text getItemid() { return itemid; } public DoubleWritable getAmount() { return amount; } public int compareTo(OrderBean o) { int cmp = this.itemid.compareTo(o.getItemid()); if (cmp == 0) { cmp = -this.amount.compareTo(o.getAmount()); } return cmp; } public void write(DataOutput out) throws IOException { out.writeUTF(itemid.toString()); out.writeDouble(amount.get()); } public void readFields(DataInput in) throws IOException { String readUTF = in.readUTF(); double readDouble = in.readDouble(); this.itemid = new Text(readUTF); this.amount = new DoubleWritable(readDouble); } @Override public String toString() { return itemid.toString() + " " + amount.get(); } /* * @Override public int hashCode() { * * return this.itemid.hashCode(); } */ @Override public boolean equals(Object obj) { OrderBean bean = (OrderBean) obj; return bean.getItemid().equals(this.itemid); } }
package cn.itcast.mapreduce.top.n; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; /** * ���ڿ���shuffle�����reduce�˶�kv�Եľۺ��� */ public class ItemidGroupingComparator extends WritableComparator { protected ItemidGroupingComparator() { super(OrderBean.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { OrderBean abean = (OrderBean) a; OrderBean bbean = (OrderBean) b; //��item_id��ͬ��bean����Ϊ��ͬ���Ӷ�ۺ�Ϊһ�� return abean.getItemid().compareTo(bbean.getItemid()); } }
package cn.itcast.mapreduce.top.n; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Partitioner; public class ItemIdPartitioner extends Partitioner<OrderBean, NullWritable> { @Override public int getPartition(OrderBean key, NullWritable value, int numPartitions) { //ָ��item_id��ͬ��bean������ͬ��reducer task return (key.getItemid().hashCode() & Integer.MAX_VALUE) % numPartitions; } }
package cn.itcast.mapreduce.top.n; import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.shell.Count; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.sun.xml.bind.v2.schemagen.xmlschema.List; /** * ����secondarysort�������ÿ��item����������ļ�¼ */ public class TopN { static class TopNMapper extends Mapper<LongWritable, Text, OrderBean, OrderBean> { OrderBean v = new OrderBean(); Text k = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] fields = StringUtils.split(line, ","); k.set(fields[0]); v.set(new Text(fields[0]), new DoubleWritable(Double.parseDouble(fields[2]))); context.write(v, v); } } static class TopNReducer extends Reducer<OrderBean, OrderBean, NullWritable, OrderBean> { int topn = 1; int count = 0; @Override protected void setup(Context context) throws IOException, InterruptedException { Configuration conf = context.getConfiguration(); topn = Integer.parseInt(conf.get("topn")); } @Override protected void reduce(OrderBean key, Iterable<OrderBean> values, Context context) throws IOException, InterruptedException { for (OrderBean bean : values) { if ((count++) == topn) { count = 0; return; } context.write(NullWritable.get(), bean); } } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); // ָ������classpath�µ��û��Զ��������ļ� // conf.addResource("userconfig.xml"); // System.out.println(conf.get("top.n")); // Ҳ����ֱ���ô��������ò���ݸ�mapreduce�����ڲ�ʹ�� conf.set("topn", "2"); Job job = Job.getInstance(conf); // job.setJarByClass(TopN.class); //告诉框架,我们的程序所在jar包的位置 job.setJar("/root/TopOne.jar"); job.setMapperClass(TopNMapper.class); job.setReducerClass(TopNReducer.class); job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(OrderBean.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(OrderBean.class); FileInputFormat.setInputPaths(job, new Path("/top/input")); FileOutputFormat.setOutputPath(job, new Path("/top/outputn")); // ָ��shuffle��ʹ�õ�partitioner�� job.setPartitionerClass(ItemIdPartitioner.class); job.setGroupingComparatorClass(ItemidGroupingComparator.class); job.setNumReduceTasks(1); job.waitForCompletion(true); } }
打包并运行

运行
hadoop jar TopN.jar cn.itcast.mapreduce.top.n.TopN
运行结果 n=2