NameNode与Secondary NameNode
很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,其实并不是在这样。文章Secondary Namenode - What it really do? (需翻墙)写的很通俗易懂,现将其翻译如下:
Secondary NameNode:它究竟有什么作用?
在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一。从它的名字上看,它给人的感觉就像是NameNode的备份。但它实际上却不是。
很多Hadoop的初学者都很疑惑,Secondary NameNode究竟是做什么的,而且它为什么会出现在HDFS中。
因此,在这篇文章中,我想要解释下Secondary NameNode在HDFS中所扮演的角色。
从它的名字来看,你可能认为它跟NameNode有点关系。没错,你猜对了。因此在我们深入了解Secondary NameNode之前,我们先来看看NameNode是做什么的。
NameNode
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
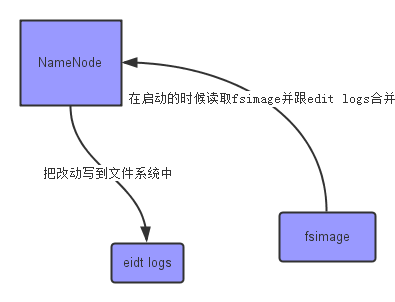
上面的这张图片展示了NameNode怎么把元数据保存到磁盘上的。这里有两个不同的文件:
fsimage - 它是在NameNode启动时对整个文件系统的快照
edit logs - 它是在NameNode启动后,对文件系统的改动序列
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。
但是在生产集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。
在这种情况下就会出现下面一些问题:
edit logs文件会变的很大,怎么去管理这个文件是一个挑战。
NameNode的重启会花费很长时间,因为有很多改动[笔者注:在edit logs中]要合并到fsimage文件上。
如果NameNode挂掉了,那我们就丢失了很多改动因为此时的fsimage文件非常旧。
因此为了克服这个问题,我们需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。
这跟Windows的恢复点是非常像的,Windows的恢复点机制允许我们对OS进行快照,这样当系统发生问题时,我们能够回滚到最新的一次恢复点上。
现在我们明白了NameNode的功能和所面临的挑战 - 保持文件系统最新的元数据。那么,这些跟Secondary NameNode又有什么关系呢?
Secondary NameNode
SecondaryNameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
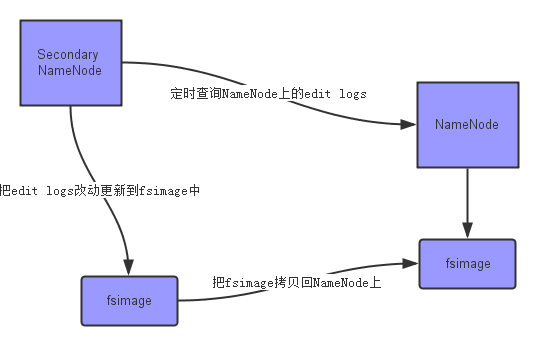
上面的图片展示了Secondary NameNode是怎么工作的。
首先,它定时到NameNode去获取edit logs,并更新到fsimage上。[笔者注:Secondary NameNode自己的fsimage]
一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。这也是它在社区内被认为是检查点节点的原因。
现在,我们明白了Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。
所以从现在起,让我们养成一个习惯,称呼它为检查点节点吧。
这篇文章基本上已经清楚的介绍了Secondary NameNode的工作以及为什么要这么做。
最后补充一点细节,是关于NameNode是什么时候将改动写到edit logs中的?
这个操作实际上是由DataNode的写操作触发的,当我们往DataNode写文件时,DataNode会跟NameNode通信,告诉NameNode什么文件的第几个block放在它那里,NameNode这个时候会将这些元数据信息写到edit logs文件中。
NameNode HA与Secondary NameNode
在hadoop2.0之前,namenode只有一个,存在单点问题(虽然hadoop1.0有secondarynamenode,checkpointnode,buckcupnode这些,但是单点问题依然存在),在hadoop2.0引入了HA机制。
hadoop2.0的HA机制官方介绍了有2种方式,一种是NFS(Network File System)方式,另外一种是QJM(Quorum Journal Manager)方式。
2 基本原理
hadoop2.0的HA 机制有两个namenode,一个是active namenode,状态是active;另外一个是standby namenode,状态是standby。
两者的状态是可以切换的,但不能同时两个都是active状态,最多只有1个是active状态。只有active namenode提供对外的服务,standby namenode是不对外服务的。
active namenode和standby namenode之间通过NFS或者JN(journalnode,QJM方式)来同步数据。
active namenode会把最近的操作记录写到本地的一个edits文件中(edits file),并传输到NFS或者JN中。
standby namenode定期的检查,从NFS或者JN把最近的edit文件读过来,然后把edits文件和fsimage文件合并成一个新的fsimage,合并完成之后会通知active namenode获取这个新fsimage。
active namenode获得这个新的fsimage文件之后,替换原来旧的fsimage文件。
这样,保持了active namenode和standby namenode的数据的实时同步,standby namenode可以随时切换成active namenode(譬如active namenode挂了)。
而且还有一个原来hadoop1.0的secondarynamenode,checkpointnode,buckcupnode的功能:合并edits文件和fsimage文件,使fsimage文件一直保持更新。
所以启动了hadoop2.0的HA机制之后,secondarynamenode,checkpointnode,buckcupnode这些都不需要了。
3 NFS方式
NFS作为active namenode和standby namenode之间数据共享的存储。active namenode会把最近的edits文件写到NFS,而standby namenode从NFS中把数据读过来。
这个方式的缺点是,如果active namenode或者standby namenode有一个和NFS之间网络有问题,则会造成他们之前数据的同步出问题。
4 QJM(Quorum Journal Manager )方式
QJM的方式可以解决上述NFS容错机制不足的问题。active namenode和standby namenode之间是通过一组journalnode(数量是奇数,可以是3,5,7...,2n+1)来共享数据。
active namenode把最近的edits文件写到2n+1个journalnode上,只要有n+1个写入成功就认为这次写入操作成功了,然后standby namenode就可以从journalnode上读取了。
可以看到,QJM方式有容错的机制,可以容忍n个journalnode的失败。
5 主备节点的切换
active namenode和standby namenode可以随时切换。当active namenode挂掉后,也可以把standby namenode切换成active状态,成为active namenode。
可以人工切换和自动切换。人工切换是通过执行HA管理的命令来改变namenode的状态,从standby到active,或者从active到standby。
自动切换则在active namenode挂掉的时候,standby namenode自动切换成active状态,取代原来的active namenode成为新的active namenode,HDFS继续正常工作。
主备节点的自动切换需要配置zookeeper。active namenode和standby namenode把他们的状态实时记录到zookeeper中,zookeeper监视他们的状态变化。
当zookeeper发现active namenode挂掉后,会自动把standby namenode切换成active namenode。
6 实战tips
- QJM方式有明显的优点,一是本身就有fencing的功能,二是通过多个journal节点增强了系统的健壮性,所以建议在生成环境中采用QJM的方式。
- journalnode消耗的资源很少,不需要额外的机器专门来启动journalnode,可以从hadoop集群中选几台机器同时作为journalnode。