1.分布式文件系统存储副本的方式
1).客户端负责写所有副本。例如每个block要存3个副本,客户端要将3个副本都存到DataNode上才算成功
2).客户端是负责写一个副本。剩下的副本由NameNode负责,DataNode向其他DataNode复制(形成一个管道),复制和客户端写block是异步的
2.具体的切分block由客户端负责
1.NameNode元数据管理机制
1.客户端上传文件时,NN首先往edits.log文件中记录元数据操作日志
2.客户端开始上传文件,完成后返回成功信息给NN,NN就在内存中写入这次上传操作新产生的元数据信息
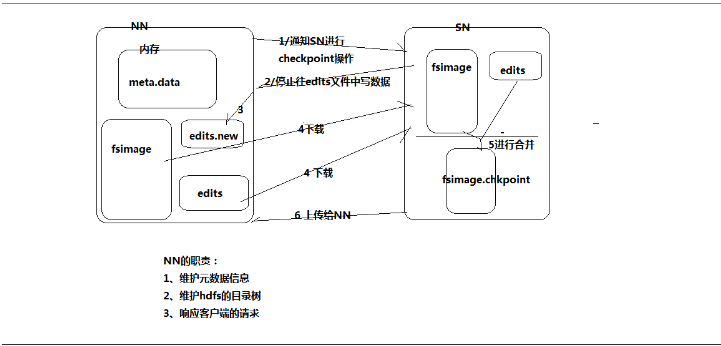
3.每当editor.log写满时,需要将这一段时间新的元数据信息刷到fsimage中去(将edits.log中的数据域fsimage做合并)

合并需要做运算,为了减轻NN的压力,由SecondaryNameNode来做这次操作。如下图:
2.DataNode的作用
1.提供真实文件数据的存储服务。
2.文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.
dfs.block.size
3.不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间
4.Replication。多复本。默认是三个。