一、概念理解:
elasticsearch 是一个搜索引擎,同时也是一个分布式的数据库。因为不仅能提供搜索的功能,还能存储搜索需要的索引库,文档字段等。
一般都简称为 ES 服务。
二、原理:
1,爬取内容 :获取源数据
2,分词:将数据内容中无意义的词去掉,建立有效的索引
3,建立倒排索引,根据内容反向搜索标题的索引。
大概原理介绍可以参考以下链接
https://developer.51cto.com/art/201904/594615.htm
三、基本术语:
文档(Document)
ElasticSearch(简称 ES) 是面向文档的,文档是所有可搜索数据的最小单位。
给大家举几个例子,让大家更形象地理解什么是文档:
- 日志文件中日志项
- 一本电影的具体信息、一张唱片的详细信息
- MP3 播放器里的一首歌、一篇 PDF 文档中的具体内容
- 一条客户数据、一条商品分类数据、一条订单数据
大家可以把文档理解为关系型数据库中的一条记录。
在 ES 中文档会被序列化成 JSON 格式,保存在 ES 中,JSON 对象由字段组成,其中每个字段都有对应的字段类型(字符串/数组/布尔/日期/二进制/范围类型)。
在 ES 中,每个文档都有一个 Unique ID,可以自己指定 ID 或者通过 ES 自动生成。
索引(Index)
索引简单来说就是相似结构文档的集合,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称,一个索引可以包含很多文档,一个索引就代表了一类类似的或者相同的文档,比如说建立一个商品索引,里面可能就存放了所有的商品数据,也就是所有的商品文档。每一个索引都是自己的 Mapping 定义文件,用来去描述去包含文档字段的类型,分片(Shard)体现的是物理空间的概念,索引中的数据分散在分片上。
在一个的索引当中,可以去为它设置 Mapping 和 Setting,Mapping 定义的是索引当中所有文档字段的类型结构,Setting 主要是指定要用多少的分片以及数据是怎么样进行分布的。
索引在不同的上下文会有不同的含义,比如,在 ES 当中,索引是一类文档的集合,这里就是名词;同时保存一个文档到 ES 的过程也叫索引(indexing),抛开 ES,提到索引,还有可能是 B 树索引或者是倒排索引,倒排索引是 ES 中一个重要的数据结构,会在以后的文章进行讲解。
分片(Shard)
由于单台机器无法存储大量数据,ES 可以将一个索引中的数据切分为多个分片(Shard),分布在多台服务器上存储。有了分片就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。
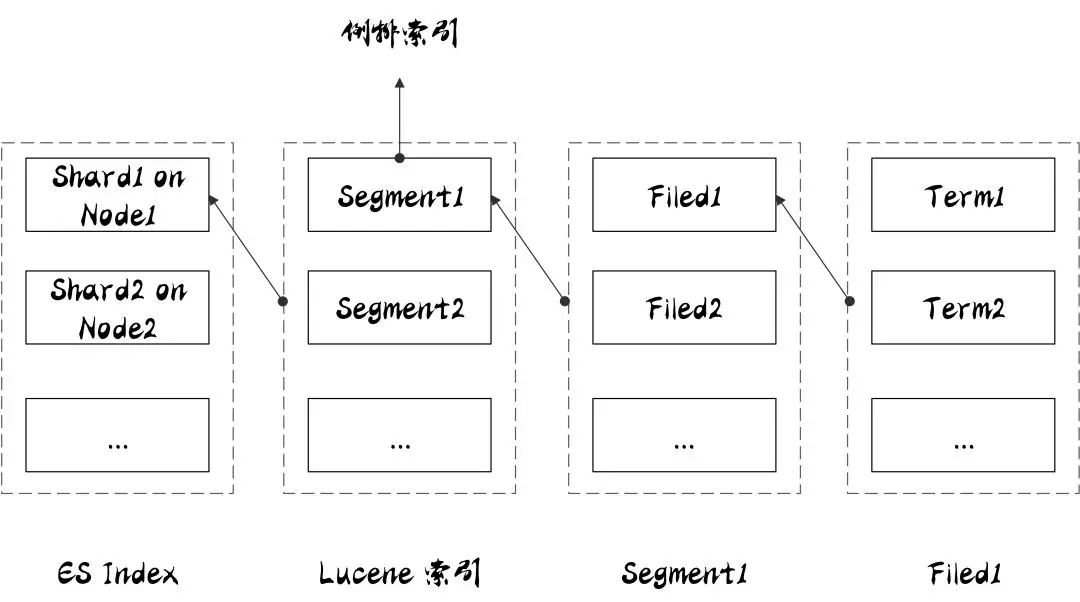
索引与分片的关系如上图所示,一个 ES 索引包含很多分片,一个分片是一个 Lucene 的索引,它本身就是一个完整的搜索引擎,可以独立执行建立索引和搜索任务。Lucene 索引又由很多分段组成,每个分段都是一个倒排索引。 ES 每次 refresh 都会生成一个新的分段,其中包含若干文档的数据。在每个分段内部,文档的不同字段被单独建立索引。每个字段的值由若干词(Term)组成,Term 是原文本内容经过分词器处理和语言处理后的最终结果(例如,去除标点符号和转换为词根)。
分片分为两类,一类为主分片(Primary Shard),另一类为副本分片(Replica Shard)。
主分片主要用以解决水平扩展的问题,通过主分片,就可以将数据分布到集群上的所有节点上,一个主分片就是一个运行的 Lucene 实例,当我们在创建 ES 索引的时候,可以指定分片数,但是主分片数在索引创建时指定,后续不允许修改,除非使用 Reindex 进行修改。
副本分片用以解决数据高可用的问题,也就是说集群中有节点出现硬件故障的时候,通过副本的方式,也可以保证数据不会产生真正的丢失,因为副本分片是主分片的拷贝,在索引中副本分片数可以动态调整,通过增加副本数,可以在一定程度上提高服务查询的性能(读取的吞吐)。
四、主要配置和安装启动
- config/elasticsearch.yml 主配置文件
node.name: es-node-1 #集群节点名字设置
path.data: /data/es #设置数据存储路径,默认是es下的data文件夹
path.logs: /var/log/es-logs #设置日志路径,默认是es下的logs文件夹
network.host: 0.0.0.0 #允许从任意ip访问elasticsearch
cluster.name: my-es-cluster #设置es集群的名字
cluster.initial_master_nodes: ["es-node-1"] #设置集群初始化master节点
#index.number_of_shards: 5 # 设置索引的分片数,默认为5
#index.number_of_replicas: 1 # 设置索引的副本数,默认为1:
- 启动es节点
需要非root账号启动,创建账号命令:
groupadd es
useradd es -g es -p es 创建账号名 es ,指定主组 es,创建密码 es。
给 es 账号文件夹权限
切换 es 账号,然后进入到他的/bin目录中,执行./elasticsearch命令启动,加上-d 参数后台启动。
如果启动报错,需要修改参数时,可以修改/etc/sysctl.conf 、/etc/security/limits.conf文件,或者使用ulimt 命令更改系统参数。
- 关闭es进程
需要把es自带的jdk配置到环境变量中,然后直接时jps命令找到elasticsearch的进程,kill掉即可。
vim /etc/profile
export ES_JAVA_HOME=/usr/local/es/elasticsearch-7.15.2/jdk
export PATH=$PATH:$ES_JAVA_HOME/bin
保存后使用 source /etc/profile 使环境变量生效
使用jps 命令找出java相关的进程