一、初始化数据库
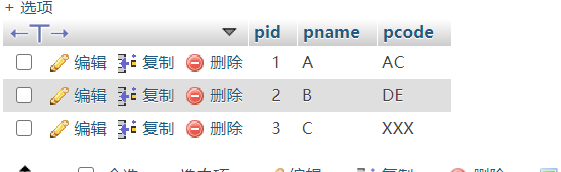
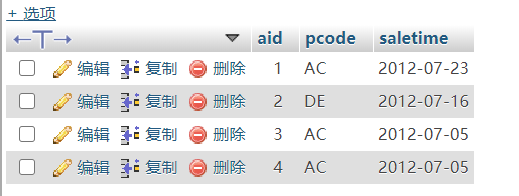
1、Tbl_Product产品表,Tbl_Sales_Detail销售详情表
CREATE DATABASE Test CREATE TABLE `Tbl_Product` ( `pid` int(4) NOT NULL auto_increment, `pname` char(20) default NULL, `pcode` char(20) default NULL, PRIMARY KEY (`pid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `Tbl_Sales_Detail` ( `aid` int(4) NOT NULL auto_increment, `pcode` char(20) default NULL, `saletime` date default NULL, PRIMARY KEY (`aid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `Tbl_Product` VALUES ('1', 'A', 'AC'); INSERT INTO `Tbl_Product` VALUES ('2', 'B', 'DE'); INSERT INTO `Tbl_Product` VALUES ('3', 'C', 'XXX'); INSERT INTO `Tbl_Sales_Detail` VALUES ('1', 'AC', '2012-07-23'); INSERT INTO `Tbl_Sales_Detail` VALUES ('2', 'DE', '2012-07-16'); INSERT INTO `Tbl_Sales_Detail` VALUES ('3', 'AC', '2012-07-05'); INSERT INTO `Tbl_Sales_Detail` VALUES ('4', 'AC', '2012-07-05');
查询两个数据表情况
SELECT * FROM Tbl_Product
SELECT * FROM Tbl_Sales_Detail
2、实现查询的链接
常用查询
SQL语句执行的时候是有一定顺序的。理解这个顺序对SQL的使用和学习有很大的帮助。 1、from 先选择一个表,或者说源头,构成一个结果集。 2、where 然后用where对结果集进行筛选。筛选出需要的信息形成新的结果集。 3、group by 对新的结果集分组。 4、having 筛选出想要的分组。 5、select 选择列。 6、order by 当所有的条件都弄完了。最后排序。
多表联查
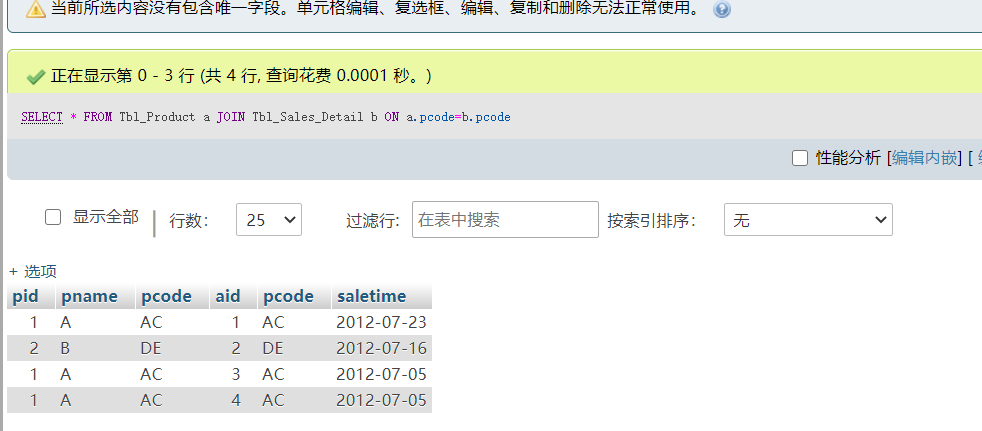
left join左连接(是返回左表中所有的行及右表中符合条件的行)
容易误区 查询是以a表为主,就去匹配a表的数据,那么查询数据的条数就等于a表这种是错误的。
而是a表为主查询,(1、每行遍历匹配满足条件的数据,最后合计,2、不满足条件,就默认null))
SELECT * FROM Tbl_Product a LEFT JOIN Tbl_Sales_Detail b ON a.pcode=b.pcode
如图:

right join右连接,是返回右表中所有的行及左表中符合条件的行。
(反过来,以b为主表,每行去遍历匹配查询(1、每行遍历匹配满足条件的数据,最后合计,2、不满足条件,就默认null))
SELECT * FROM Tbl_Product a RIGHT JOIN Tbl_Sales_Detail b ON a.pcode=b.pcode
如图:
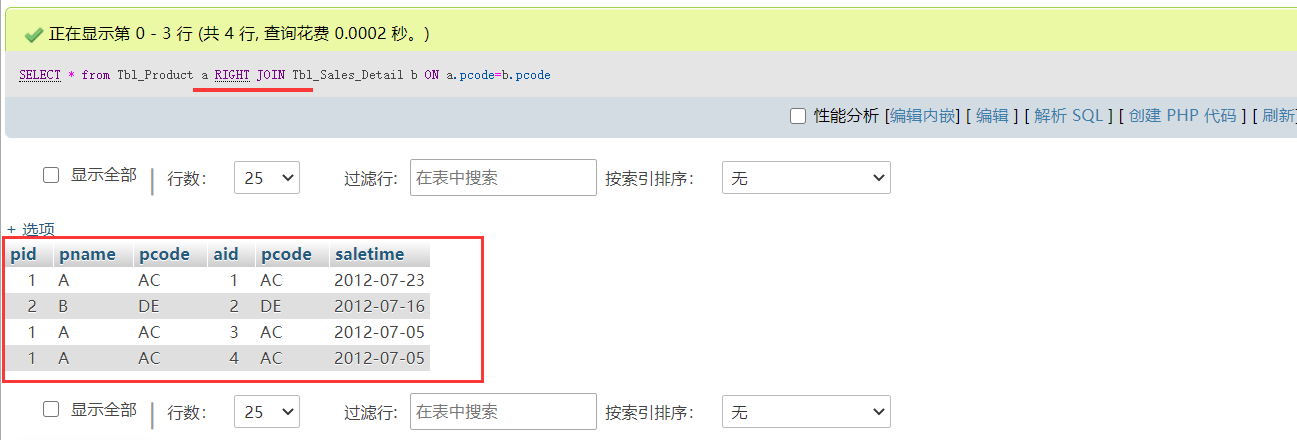
细节:查询 pid pname 虽然改了 right 但是 查出的字段顺序 还是 没有改变
比如 INSERT INTO `Tbl_Sales_Detail` VALUES ('5', 'SS', '2012-07-23');

inner join(等值连接) 只返回两个表中联结字段相等的行 可以简写 join 查询

简写
select * from Tbl_Product,Tbl_Sales_Detail
select * from Tbl_Product inner join Tbl_Sales_Detail
select * from Tbl_Product join Tbl_Sales_Detail
//加条件和不加条件不一样
union:联合的意思,即把两次或多次查询结果合并起来。 union会去掉重复的行。
(select * from Tbl_Sales_Detail order by aid) union (select * from Tbl_Sales_Detail order by aid)
如图
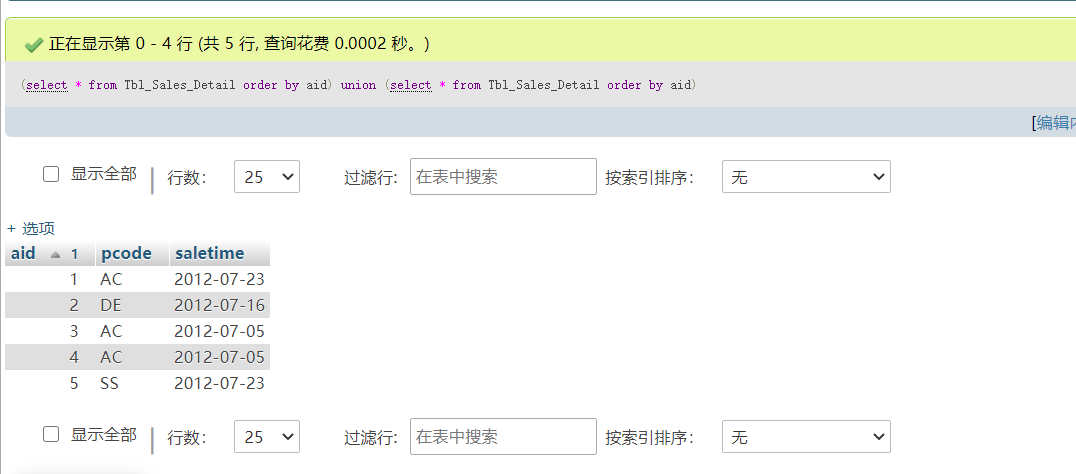
如果不想去掉重复的行,可以使用union all。

可以看出,字段数没变,变动的只是行数