工作中经常会使用sql分组,总结三个方法:
1、distinct
在 SQL 中,关键字 distinct 用于返回唯一不同的值。其语法格式为:
SELECT DISTINCT 列名称 FROM 表名称
假设有一个表“CESHIDEMO”,包含两个字段,分别 NAME 和 AGE,具体格式如下:

观察以上的表,咱们会发现:拥有相同 NAME 的记录有两条,拥有相同 AGE 的记录有三条。如果咱们运行下面这条 SQL 语句,
/** * 其中 PPPRDER 为 Schema 的名字,即表 CESHIDEMO 在 PPPRDER 中 */ select name from PPPRDER.CESHIDEMO
将会得到如下结果:
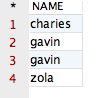
观察该结果,咱们会发现在以上的四条记录中,包含两条 NAME 值相同的记录,即第 2 条记录和第 3 条记录的值都为“gavin”。那么,如果咱们想让拥有相同 NAME 的记录只显示一条该如何实现呢?这时,就需要用到 distinct 关键字啦!接下来,运行如下 SQL 语句,
select distinct name from PPPRDER.CESHIDEMO
将会得到如下结果:

观察该结果,显然咱们的要求得到实现啦!但是,咱们不禁会想到,如果将 distinct 关键字同时作用在两个字段上将会产生什么效果呢?既然想到了,咱们就试试呗,运行如下 SQL 语句,
select distinct name, age from PPPRDER.CESHIDEMO
得到的结果如下所示:
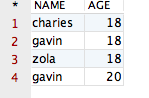
观察该结果,哎呀,貌似没有作用啊?她将全部的记录都显示出来了啊!其中 NAME 值相同的记录有两条,AGE 值相同的记录有三条,完全没有变化啊!但事实上,结果就应该是这样的。因为当 distinct 作用在多个字段的时候,她只会将所有字段值都相同的记录“去重”掉,显然咱们“可怜”的四条记录并不满足该条件,因此 distinct 会认为上面四条记录并不相同。空口无凭,接下来,咱们再向表“CESHIDEMO”中添加一条完全相同的记录,验证一下即可。添加一条记录后的表如下所示:

再运行如下的 SQL 语句,
select distinct name, age from PPPRDER.CESHIDEMO
得到的结果如下所示:
观察该结果,完美的验证了咱们上面的结论。
此外,有一点需要大家特别注意,即:关键字 distinct 只能放在 SQL 语句中所有字段的最前面才能起作用,如果放错位置,SQL 不会报错,但也不会起到任何效果。
2、row_number() over()
在 oracle数据库中,为咱们提供了一个函数 row_number() 用于给数据库表中的记录进行标号,在使用的时候,其后还跟着一个函数 over(),而函数 over() 的作用是将表中的记录进行分组和排序。两者使用的语法为:
ROW_NUMBER() OVER(PARTITION BY COLUMN1 ORDER BY COLUMN2)
意为:将表中的记录按字段 COLUMN1进行分组,按字段 COLUMN2 进行排序,其中
PARTITION BY:表示分组ORDER BY:表示排序
接下来,咱们还用表“CESHIDEMO”中的数据进行测试。首先,给出没有使用 row_number() over() 函数时查询的结果,如下所示:
然后,运行如下 SQL 语句,
得到的结果如下所示:

从上面的结果可以看出,其在原表的基础上,多了一列标有数字排序的列。那么反过来分析咱们运行的 SQL 语句,发现其确实按字段 AGE 的值进行分组了,也按字段 NAME 的值进行排序啦!因此,函数的功能得到了验证。
接下来,咱们就研究如何用 row_number() over() 函数实现“去重”的功能。通过观察上面的结果,咱们可以发现,如果以 NAME 分组,以 AGE 排序,然后再取每组的第一个记录或许就可以实现“去重”的功能啊!那么试试看,运行如下 SQL 语句,
/* * 其中 rn 表示最后添加的那一列 */ select * from (select PPPRDER.CESHIDEMO.*, row_number() over(partition by name order by age desc) rn from PPPRDER.CESHIDEMO) where rn = 1
运行后,得到的结果如下所示:

3、group by
GROUP BY语句用来与聚合函数(aggregate functions such as COUNT, SUM, AVG, MIN, or MAX.)联合使用来得到一个或多个列的结果集。
语法如下:
SELECT column1, column2, ... column_n, aggregate_function (expression)
FROM tables
WHERE predicates
GROUP BY column1, column2, ... column_n;
举例
比如说我们有一个学生表格(student),包含学号(id),课程(course),分数(score)等等多个列,我们想通过查询得到每个学生选了几门课程,此时我们就可以联合使用COUNT函数与GROUP BY语句来得到这一结果
SELECT id, COUNT(course) as numcourse
FROM student
GROUP BY id
因为我们是使用学号来进行分组的,这样COUNT函数就是在以学号分组的前提下来实现的,通过COUNT(course)就可以计算每一个学号对应的课程数。
注意
因为聚合函数通过作用于一组数据而只返回一个单个值,因此,在SELECT语句中出现的元素要么为一个聚合函数的输入值,要么为GROUP BY语句的参数,否则会出错。
例如,对于上面提到的表格,我们做一个这样的查询:
SELECT id, COUNT(course) as numcourse, score
FROM student
GROUP BY id
此时查询便会出错,错误提示如下:
Column ‘student.score' is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
出现以上错误的原因是因为一个学生id对应多个分数,如果我们简单的在SELECT语句中写上score,则无法判断应该输出哪一个分数。如果想用score作为select语句的参数可以将它用作一个聚合函数的输入值,如下例,我们可以得到每个学生所选的课程门数以及每个学生的平均分数:
SELECT id, COUNT(course) as numcourse, AVG(score) as avgscore
FROM student
GROUP BY id
HAVING
HAVING语句通常与GROUP BY语句联合使用,用来过滤由GROUP BY语句返回的记录集。
HAVING语句的存在弥补了WHERE关键字不能与聚合函数联合使用的不足。
语法:
SELECT column1, column2, ... column_n, aggregate_function (expression)
FROM tables
WHERE predicates
GROUP BY column1, column2, ... column_n
HAVING condition1 ... condition_n;
同样使用本文中的学生表格,如果想查询平均分高于80分的学生记录可以这样写:
SELECT id, COUNT(course) as numcourse, AVG(score) as avgscore
FROM student
GROUP BY id
HAVING AVG(score)>=80;
在这里,如果用WHERE代替HAVING就会出错
select t.a , min(t.b) , t.c from table t
group by t.a,t.c