(转载请注明出处,作者:finallyliuyu)
前言:
经了解,园子里有很多已经工作,但是对信息检索和自然语言处理感兴趣的同仁,也有很多相关领域的从业者。目前本人正在从事文本特征选择方面的研究。所以打算写一系列有关此方向的科普型博客,和大家分享见解。也希望在算法的理解方面和业内人士多多交流。
此系列的计划是介绍各种特征词选择方法,参考自Yiming Yang 1997年的论文"A comparative Study on Feature Selection in TextCategorization"。
更确切地说是采用中文语料库(语料库来源:搜狗开放语料库 要特此对搜狗实验室的无私奉献表示感谢)对Yiming Yang此篇论文中的见解进行实际验证。
陆游有一句诗"纸上得来终觉浅,觉知此事要躬行"。所以才有了此系列博客。此系列博客将不仅介绍各种特征词选择算法的效率,还会提供已经处理好的语料库(libsvm数据格式 注语料库使用者请注明语料来源:网友finallyliuyu提供 )供研究者,学习者下载。写此博客有两个目的:一:像我一样的初级学习者,不用在耗尽眼力从黑白色的教科书、论文中那些没有颜色区分的图中寻找关于各种特征词选择方法效率的蛛丝马迹了。在这一系列博文中,你将看到彩色的图片,得到对此类问题的第一手直观的理解。更重要的,你也有下载语料库,自己调用libsvm分类,调用matlab画图,来体验下各种特征词选择算法的"魅力"。二。我们也有开源的libsvm格式数据,以后的libsvm初级使用者,将不再只局限于它的网站上给出的那些分类材料。三,所有的语料库由于博客园上传能力有限,将放在csdn下载频道,无任何积分即可下载
鉴于本人理工科背景出身,且文笔拙劣,有叙述不清楚的地方,希望大家指正。同时也希望和欢迎大家对我的博客内容提出异议,批评和指正。
(一) 特征词选择是否有用?
有人(包括我自己在内)曾怀疑那些所谓的特征词选择算法是否真的能在减少特征维度的前提下保持或提高分类准确率?是不是特征词数目越多分类准确率越高?
请看如下几张图表。
N:代表文档集规模,M代表特征维数
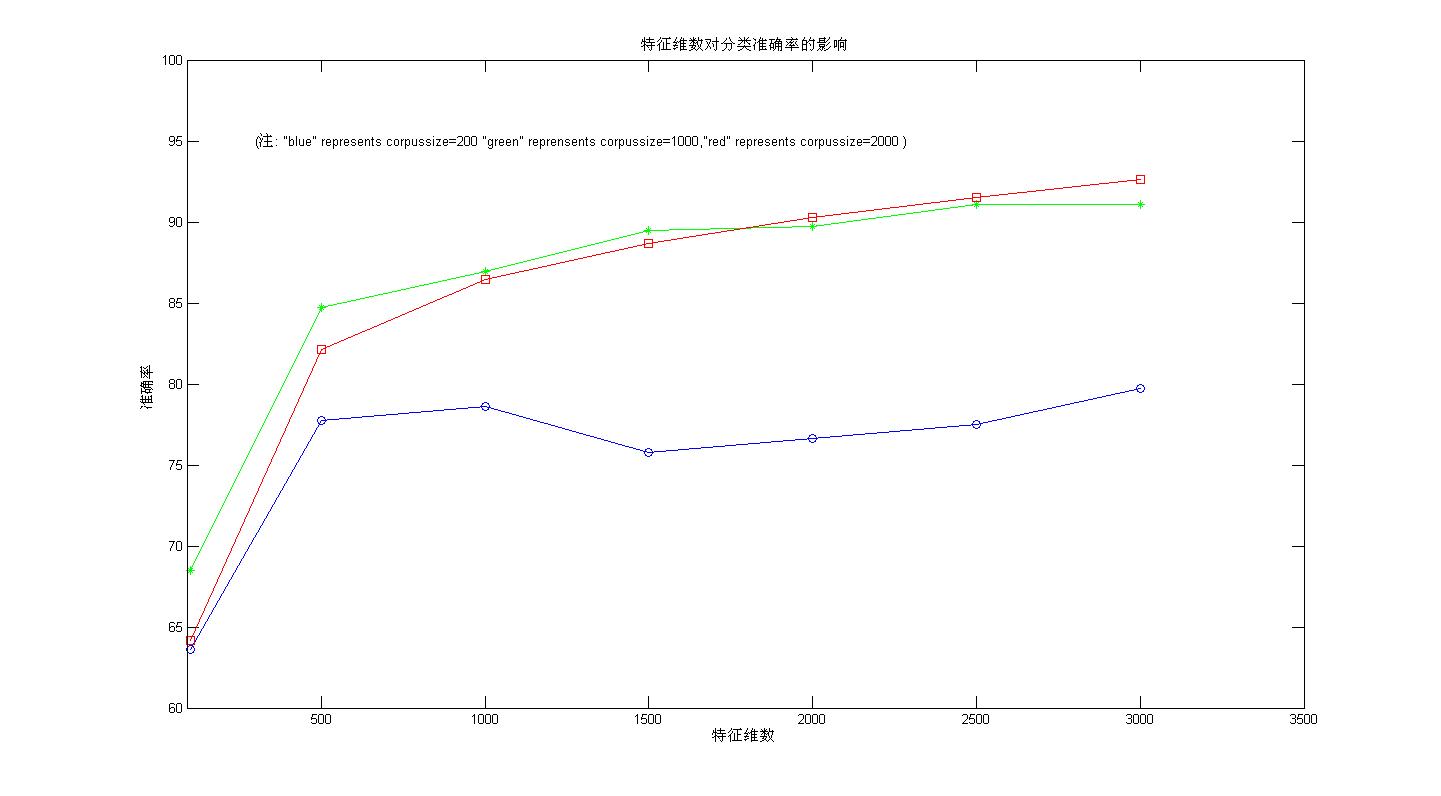
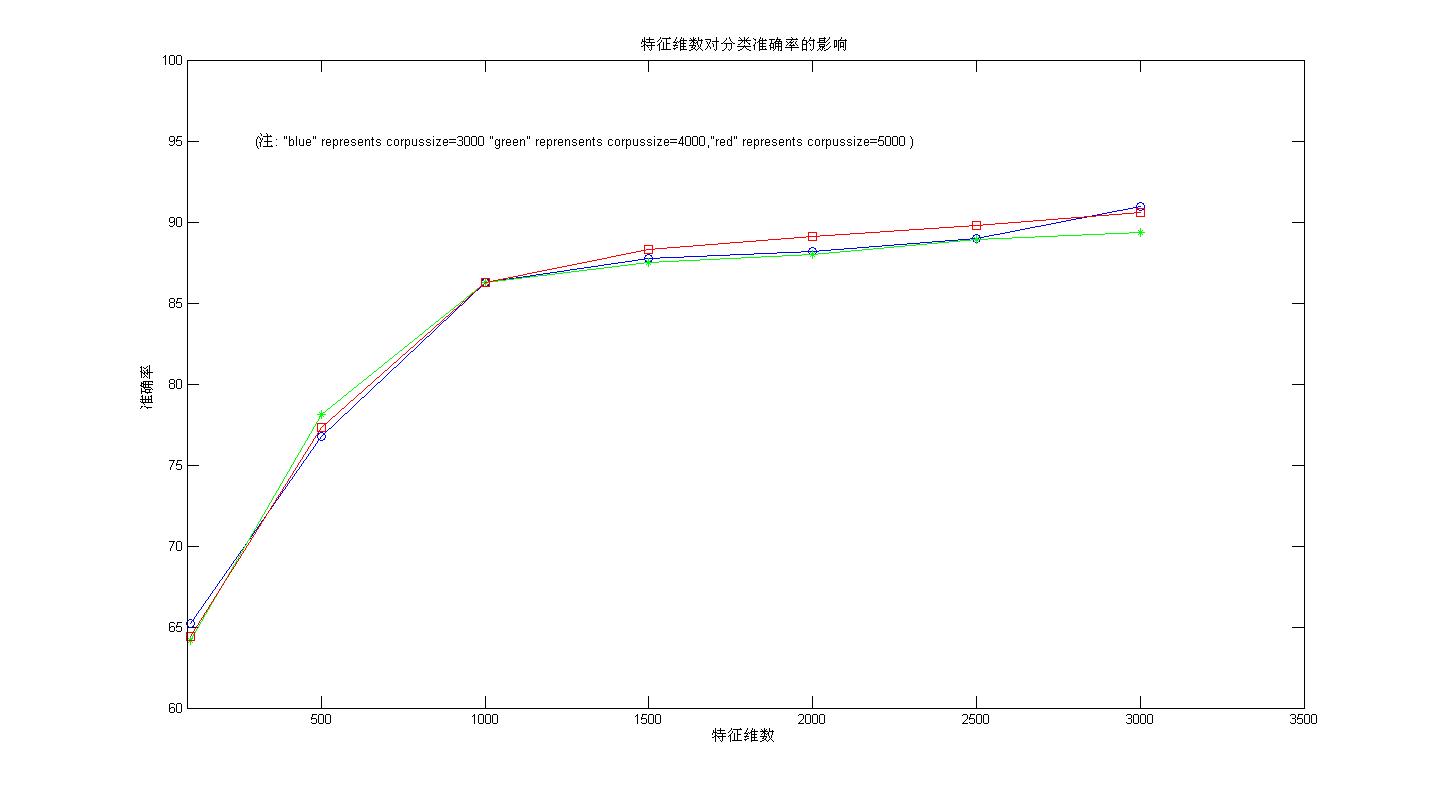
不采用任何特征词选择算法,从词袋子中顺序取M个词作为特征词的5折交叉验证准确率曲线如下图(1,2)
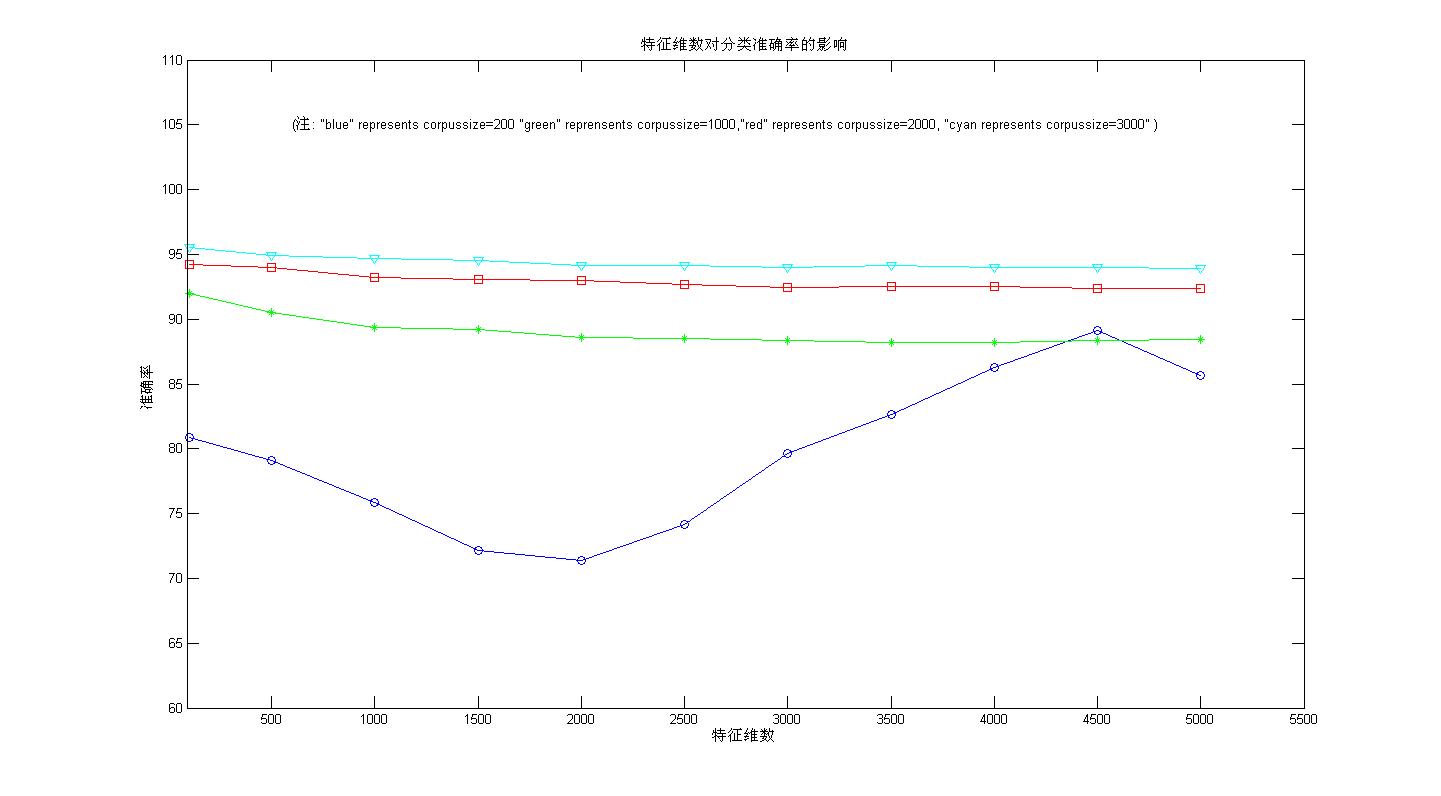
图三运用IG法选取M维特征词
从图1,图2可以看出 :
从上面两幅图可以看出:在顺序选取M个特征词(即先从第一类形成的词袋子中选词,若M>第一类形成的词袋子中的词的总数,余下的部分从第二类形成的词袋子中选)的时候,i)最低分类准确率在50%以上。这个不难理解,因为最坏的情况是所选择的M个特征词都在第一类训练文档集所形成的词袋子中那么这些词能够保证对属于第一类的测试文档有良好的预测作用;ii)随着特征词数目的增加,分类准确率总体呈上升趋势,理由“i)”中的分析,但是总体准确率不高,在特征维数为3000的时候,最高准确率为(91 +-1)%。
从图3可以看出:
特征词选择算法是有效的,经过特征词选择算法,选取的特征词能够使分类准确率得到提高 ;并不是特证词维数越高,分类准确率越高。从图2可以看出,当文档集规模》200时,分类准确率随着特征词维数的增加呈平稳下降趋势。