本小节,我们仅考虑一种特征词选择框架IG(infomation Gain)。

采用两种概率建模
第一种我们称之为经典的概率建模。也就是被公认采纳的那一种。
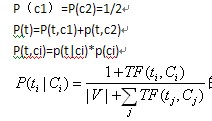
也就是说该种方法认为 每个类别的概率可以根据训练语料中两个类别的文章数目来估计,由于我的实验中两类数目相等所以各为二分之一。
文章是连接词语与类别的桥梁。因此在计算 TF(t,C)的时候,有可以根据文档是由多变量伯努利分布生成(一),还是多项式分布生成(二)。有两种概率计算方式。在(一)的情况下,仅考虑一个词在文章中是否出现,出现则为1,否则则为0。在(二)的情况下不仅要考虑一个词在文章中是否出现,而且要考虑其出现的次数。
下面给出情况一和情况二下的实验结果:
情况一:

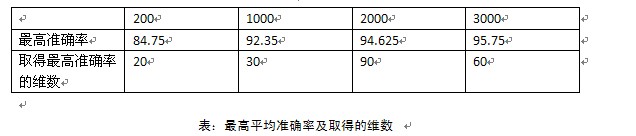
情况二


对比后发现,取得最高准确率的值和维度都是一样的。不仅如此,
其实在两种情况下计算的各个文档规模,在各个特征维度上的5次交叉验证的平均准确率也是惊人的一致(大家不要怀疑我伪造数据哈,没有这个必要)
两种方法计算的平均准确率如下(图片只显示了部分,最后我会将准确率数据打包上传)
