Pointers are like jumps, leading wildly from one part of the data structure to another. Their introduction into high-level languages has been a step backwards from which we may never recover. — Anthony Hoare
对指针可能有最让人误解和惧怕的数据类型,因此很多程序员喜欢躲避他们.
但是指针很重要.即使不显式支持指针或使其很难应用的语言,在其背后指针也起到非常重要的作用.因此理解指针是很重要的.有几个不同的途径理解指针.
本文针对理解指针和使用指针有问题的读者.在Win32的Delphi环境下进行讨论.可能不会涉及到所有方面(例如,一个应用程序的内存不是一个大的连续区域),但出于实用目的是有所帮助的.我认为指针是很容易理解的.
内存
You probably already know what I write in this paragraph, but it is probably good to read it anyway, since it shows my view on things, which may differ a bit from your own.
指针是一个指向其他变量的变量.为解释他们,有必要先理解内存地址和变量的概念.首先先简要的解释一下计算机内存.
计算机内存简化的可以看做很长的字节行.字节是最小存储单元,包括256种不同的值(0到255).在当前32为Delphi中,内存可以看做是最大有2G字节长度的数组.字节中存储的内容与内容的解读方式有关,例如,使用方式.值97可以看做是一个byte类型的97,可以看做字符a.如果包含多个字节,可以存储更多的值.两个字节可以表示256*256中不同的值.
内存中的字节可以按编号进行访问,从0开始直到2147483647(假如有2G字节,即使你不知道这些,Windows也会试图虚拟这种效果).在这个巨大的数组中字节索引叫做地址.
也可以说:字节是内存中最小的可用地址表示的块.
事实上,内存非常复杂.有些计算机的字节不是8位,其能表示或大于或小于256种值,但Win32的Delphi不会遇到这样的计算机.内存由软件和硬件共同管理,全部的内存并非真正存在(内存管理程序处理同样与硬盘交换空间来解决这些问题),但本文中,将内存看做是字节组成的大块并在多个程序间共用有助于理解问题.
变量
变量是巨大数组中的一个或多个字节组成的存储单元,可供程序读写.有名字,类型,值及其地址进行标示.
如果声明了一个变量,编辑器将保留一块适当大小的内存区域.变量存储的具体地址由编译器及运行时代码决定.不能对变量具体存放地址做任何假设.
变量类型定义了如何使用内存存储单元.例如其定义了size (尺寸)决定占用多少字节,以及其structure(结构).例如,下图是一个内存片段.显示了起始地址在$00012344的4个字节.字节值分别为$4D, $65, $6D和$00.

注意上图虽然使用了$00012344作为起始地址,但这是杜撰的,只是为了区别其他内存位置.并不是真实反映的内存地址,其依赖于很多事情,不可预测.
数据类型决定了如何使用这些字节.例如Integer类型其值为7169357 ($006D654D),或一个array[0..3] of Char类型,表示C风格的字符串'Mem',或其他内容,如集合变量,几个单字节变量,一个小结构体, Single或Double类型的一部分等等.换句话说,在不知道存储的变量类型前,内存中存储的值的意义是无法推测的.
变量的地址是其第一个字节的地址.上图中,假设是一个Integer,其地址为 $00012344.
未初始化变量
内存对于变量来说是可以重用的.通常内存为变量预留的时间与变量的生命周期一样长.例如,函数或过程(两者总称例程)中的局部变量仅在例程运行期间可用.对象的域(也是一个变量)在对象存在期间可用.
如果声明一个变量,编译器预留出变量需要的字节数.但其中的内容是以前函数或过程使用的时候在字节中存放的.换句话说,未初始化的变量值是未定义的(但不是未定的).例如在如下简单的控制台程序中:
program uninitializedVar;
{$APPTYPE CONSOLE}
procedure Test;
var
A: Integer;
begin
Writeln(A); // uninitialized yet
A := 12345;
Writeln(A); // initialized: 12345
end;
begin
Test;
Readln;
end.
第一个显示的值(未初始化的变量A)依赖于变量A存储的地址中以前的值.本例中,显示为2147319808 ($7FFD8000) ,但在其他计算机上会显示不同的值.值是未定义的,因为其未初始化.在复杂的程序中, 尤其就指针而言这经常会导致程序瘫痪或意想不到的结果.赋值语句将变量A初始化为12345 ($00003039), 第二个值显示正常.
指针
指针也是变量.但其中不存储数值或字符,而是一个内存存储单元的地址.如果将内存看做是一个大数组,指针可以看做是这个数组中的一个入口,指向数组中另一个数组的入口索引.( If you see memory as an array,a pointer can be seen as an entry in the array which contains the index of another entry in the array.)
假设有如下的声明和初始化过程:
var
I: Integer;
J: Integer;
C: Char;
begin
I := 4222;
J := 1357;
C := 'A';
并假如有如下的内存布局:

执行完这些代码后,假如P是一个指针,
P := @I;
既有如下情形:

上图中,显示出了每个字节.通常是不必要的,因此可简化为:

这个图不能在反映出真实的内存占用大小(C看起来可I或J一样大小),但对理解指针来说足够了.
Nil
Thou shalt not follow the NULL pointer, for chaos and madness await thee at its end. — Henry Spencer
Nil 是一个特殊的指针值.可以赋值给任意类型的指针.其表示空指针(nil在拉丁语中是nihil,表示啥也没有或零;或者说NIL表示Not In List).表示指针有定义的状态,但不能访问任何值(C语言中nil表示为NULL--见上面的引用).
Nil 不执行可用的内存,但作为一个预定义的值,很多例程可以对其进行检查 (例如使用Assigned()函数).赋予了一个有效值后就无法检测了,旧指针或未初始化指针与正常的指针没有什么不同. 没有方法区别他们.程序逻辑必须确保指针或是有效的或是nil.
Delphi中, nil 的值是0,指向内存区域中的第一个字节.很明显这个字节Delphi代码是无法访问到的.除非对后台原理非常理解,通常不必关心nil等于0.nil 的值可能会在以后版本中出于某种目的进行修改.
类型指针
上例中P是Pointer类型的.意味着P包含一个地址,但不知道地址处的保存的变量信息. 指针之所以是通用的类型,指针可以解读指向的内存区域中存储的特定类型的内容.
假设有另一个指针, Q:
var
Q: ^Integer;
Q 的类型是^Integer,可以读作”指向Integer” (^Integer相当于↑Integer).即这不是一个整数,而是指向一个常用的内存存储单元.要将变量J的地址赋予Q,可以使用@ 地址操作符或定价的伪函数Addr,
Q := @J; // Q := Addr(J);

Q指向了局部地址$00012348 (指向了有变量J标识的内存存储单元).但由于Q是一个类型化指针,编译器将Q指向的内存单元看做是一个整数.Integer是Q的基本类型.
虽然很少看到使用伪函数Addr的代码,其等价于@.对于复杂的表达式@有时很难看出是作用于那个部分.而Addr使用的是函数语法,配合小括号减少了混淆:
P := @PMyRec^.Integers^[6];
Q := Addr(PMyRec^.Integers^[6]);
通过指针赋值与直接使用变量有少许不同.通常只能通过指针进行操作.如果对普通变量赋值,形式如下:
J := 98765;
将整数值98765 (十六进制$000181CD)赋予内存存储单元.使用指针Q来存取内存存储单元,必须通过间接方式,使用^操作符:
Q^ := 98765;
这叫做降低引用(dereferencing). 假想虚拟箭头指向Q中的地址(这里是$00012348)并将对其赋值.
对于结构体,如果没有异议,语法上可以省去^操作符.为了清晰,建议保留..
通常将常用的类型指针预先定义好.例如,^Integer不能用于参数传递,需要预先定义一个类型:
type
PInteger = ^Integer;
procedure Abracadabra(I: PInteger);
事实上, Pinteger类型和其他常用指针类型已经在Delphi的运行时库 (例如System和SysUtils单元)中预先定义.通常命名为P加上指向的类型名称.如果基本类型名称以T作为前缀,则忽略T.例如:
type
PByte = ^Byte;
PDouble = ^Double;
PRect = ^TRect;
PPoint = ^TPoint;
匿名变量
上例中按需定义了变量.有时无法确认是否需要一个变量,以及多少个变量.通过指针就可以使用匿名变量. 可在运行时预留内存,并返回一个指针.使用伪函数New():
var
PI: PInteger;
begin
New(PI);
New() 是一个编译器伪函数.其为PI预留基本类型大小的内存,并使PI指向这块内存区域(其中存储了内存区域的地址).变量没有名称,因此是匿名的.只能提供指针间接访问.现在可对其赋值,在函数间传递,在不需要的时候调用Dispose(PI)释放:
PI^ := 12345;
ListBox1.Add(IntToStr(PI^));
// lots of code
Dispose(PI);
end;
除了New和Dispose,也可调用更低级别的函数GetMem和FreeMem.但New 和Dispose有几个优点.他们已经知道指针的基本类型,并对内存存储单元进行必要的初始化和释放.因此无论何时都优先使用New和Dispose替代GetMem和FreeMem.
确保每个New()都有一个对应的使用相同类型和指针的Dispose()调用,否则变量就不会被正确的释放.
可能相对于直接使用变量的优点不是很明显,但对于不知道需要多少个变量的情形很有用.假如一个链接列表(see below),或一个TList. TList存储指针,如果想在List中存储Double值,可以简单的对每个值调用New()并将指针存储在Tlist中:
var
P: PDouble;
begin
while HasValues(SomeThing) do
begin
New(P);
P^ := ReadValue(SomeThing);
MyList.Add(P);
// etc...
当然在列表不再使用的阶段要对每个值调用Dispose().
使用匿名变量,可以容易的阐述通过类型指针操作内存.两个指针类型不同,执行同一块内存,可以显示出不同的值:
program InterpretMem;
{$APPTYPE CONSOLE}
var
PI: PInteger;
PC: PAnsiChar;
begin
New(PI);
PI^ := $006D654D; // Bytes $4D $65 $6D $00
PC := PAnsiChar(PI); // Both point to same address now.
Writeln(PI^); // Write integer.
Writeln(PC^); // Write one character ($4D).
Writeln(PC); // Interpret $4D $65 $6D $00 as C-style string.
Dispose(PI);
Readln;
end.
PI 将内存存储单元填充为$006D654D (7169357).下图(注意地址纯粹是虚构的):

PC 指向了同一块内存(由于基本类型不同,不能直接进行赋值,必须进行类型转换).但PC 指向一个AnsiChar,因此如果调用PC^, 获取到的是一个AnsiChar, ASCII字符值为$4D或'M'.
PC 是特殊情况,尽管是PAnsiChar类型, 由于实际是指向AnsiChar的指针,处理起来和其他类型指向稍有不同.在其他文章中解释another article.PC,如果没有降低引用,通常看做是指向以#0结尾的字符串,调用Writeln(PC) 将$4D $65 $6D $00字节显示为'Mem'.
当思考指针问题,尤其是复杂指针,我都准备一页纸和钢笔或铅笔,绘制如本文所见的图.变量的地址也是伪造的(并不是32位的,而是像30000,40000, 40004, 40008 和 50000便于理解就好).
坏指针
适当使用指针是很有用而且灵活的.但一旦出错将是一个大问题.这也是很多人尽量避免使用指针的原因.这里描述常见错误.
未初始化指针
指针是变量,可其他变量一样需要初始化,或赋予其他指针值,或使用New或 GetMem 等等:
var
P1: PInteger;
P2: PInteger;
P3: PInteger;
I: Integer;
begin
I := 0;
P1 := @I; // OK: using @ operator
P2 := P1; // OK: assign other pointer
New(P3); // OK: New
Dispose(P3);
end;
例如如果简单的声明PInteger,但没有初始化,指针包含了一个随机字节值,其指向了随机的内存区域.
如果访问这个随机的内存地址,会发生令人厌恶的事情.如果这个内存地址不在当前应用程序预留范围内,获取一个非法访问(Access Violation)错误,程序崩溃.但如果内存在应用程序预留范围,并写了数据,可能修改了不应修改的数据.如果数据在程序的其他部分稍后使用,会导致程序的数据错误.这样的错误很难查找.
事实上,如果获取到AV或其他类型的明显错误,是值得高兴的(除了硬盘损坏).应用程序崩溃不好,但问题很容易定位和修改.但对于错误数据和结果,问题更加糟糕,可能没有注意到或很久才爆发.因此使用指针必须及其谨慎.要细致的检查未初始化的指针.
旧指针
旧指针是以前有效的指针,但后来过时了.经常因为指针指向的内存区域被释放和重用.
经常发生旧指针的情况是内存被释放,但指针仍旧被使用.为避免这种情况,有些程序员在释放内存后总将指针设置为nil.并在访问内存前检查其是否为nil.换句话说,nil是指针不可用的标志.这是一种途径,但并不总有效.
另一种常见情况是多个指针执行同一个内存区域,然后用其中的一个指针释放内存.即使将那个指针置为nil,其他指针还是指向了这块被释放的内存.如果幸运报非法指针错误,但具体会发生什么事情是不确定的.
第三,相似的问题是指向不稳定的数据,例如,数据会随时消失.最大的错误是在函数中返回一个指向局部数据的指针.一旦例程结束,数据消失,局部变量不再存在.典型(愚蠢)的范例:
function VersionData: PChar;
var
V: array[0..11] of Char;
begin
CalculateVersion(V);
Result := V;
end;
V位于过程栈.这是每个运行时函数用来存放局部变量和参数,以及敏感的函数返回地址的地方.结果值指向V (PChar 可以直接指向数组,见提及的article).VersionData 结束后,栈被另一个运行的例程改变,无论CalculateVersion计算的结果是什么都以过时,指针指向了同一栈位置的新内容.
同样的问题还有Pchar指向一个字符串,请见article about PChars.指针指向动态数组元素也是一个经典问题,因为动态数组变小或调用SetLength后会被移动.
使用错误的基本类型
事实上指针可以指向任意内存存储单元,两个不同类型的指针可以指向同一个区域,意味着可以按不同方式存取同一个内存区域.使用指向Byte(^Byte)的指针,可以按字节修改整数或其他类型的内容.
但也可能会写覆盖(overwrite)或读覆盖(overread).例如,如果用整数指针去访问存储一个字节的内存区域,将会写4个字节,而不仅仅是Byte类型的单字节,还有其后的3个字节,因为编译器将这连续的4个字节看做是一个整数.同样读取这个字节,也会多读3个字节:
var
PI: PInteger;
I, J: Integer;
B: Byte;
begin
PI := PInteger(@B);
I := PI^;
J := B;
end;
J 有正确的值,因为编译器会填充0将单字节扩展成为一个整数(4字节).但变量I则不同,其包括一个字节,以及其后的3个字节,组成了未定义的值.
指针允许不通过变量本身来设置变量的值.这可能在调试过程中很疑惑.知道一个变量的值错误,但不知道哪里的代码修改了变量,因为其是通过指针设置的.
所有者和孤儿
指针不但有不同的基本类型,还有不同的所有者语义.如果使用New或GetMem,或其他特定例程申请内存,你就是内存的所有者.很好,如果要持有这块内存,需要将指针保存到一个安全的地方.这个指针是唯一可访问这块内存的途径,如果其中的地址丢失,就无法在访问或释放这块内存了.一个规则是申请的内存必须被释放,因此你有责任照顾好他.设计良好的程序必须考虑到这些.
理解所有者是很重要的.拥有内存的人必须负责释放内存.可以找代理来执行这个任务,但必须确保执行正确..
一个常见的错误是使用指针指向一块分配的内存,而后又将这个指针指向另外一个内存块.指针指向第一个内存块又再次指向了另外一个内存块,原来的内存块丢失.已经没有办法找回第一个申请到的内存块.内存块成为了孤儿.已无法再次访问并处理他.这也叫做内存泄露.
这是摘自Borland的新闻组中的范例代码:
var
bitdata: array of Byte;
pbBitmap: Pointer;
begin
SetLength(bitdata, nBufSize);
GetMem(pbBitmap, nBufSize);
pbBitmap := Addr(bitdata);
VbMediaGetCurrentFrame(VBDev, @bmpinfo.bmiHeader, @pbBitmap, nBufSize);
事实上,这个代码有几个冲突的地方. SetLength为bitdata分配字节.出于某种原因程序员使用GetMem为pbBitmap分配了同样数量的字节.而后将pbBitmap指向了另外一个内存地址,导致由分配GetMem的内存无法被访问.( pbBitmap是唯一访问的途径,但现在不在指向他了).换句话说,内存泄露了.
事实上,还有几个错误. bitdata 是一个动态数组,获取bitdata的地址只是得到了一个指针的地址,而不是缓冲区中第一个字节的地址(更多信息参见下面的动态数组).而且,由于pbBitmap也是指针,在函数调用时使用@操作符传递参数是错误的.
正确的代码如下:
var
bitdata: array of Byte;
pbBitmap: Pointer;
begin
if nBufSize > 0 then
begin
SetLength(bitdata, nBufSize);
pbBitmap := Addr(bitdata[0]);
VbMediaGetCurrentFrame(VBDev, @bmpinfo.bmiHeader, pbBitmap, nBufSize);
end;
或者:
var
bitdata: array of Byte;
begin
if nBufSize > 0 then
begin
SetLength(bitdata, nBufSize);
VbMediaGetCurrentFrame(VBDev, @bmpinfo.bmiHeader, @bitdata[0], nBufSize);
end;
看起来是很严重的问题,但是在复杂代码中很容易出现.
注意指针不必一定执行自己的内存块.指针通常用来遍历数组(如下),或操作结构体中的成员.如果没有为其分配内存,就不必负责对内存块进行控制.可以看做是用完就失效的临时变量.
指针运算和数组
You can either have software quality or you can have pointer arithmetic, but you cannot have both at the same time. — Bertrand Meyer
Delphi allows some simple manipulations of a pointer. Of course you can assign to them, and compare them for equality (if P1 = P2 then) or inequality, but you can also increment and decrement them, usingInc and Dec. The neat thing is that these increments and decrements arescaled by the size of the base type of the pointer. An example (note that I set the pointer to a fake address. As long as I don't access anything with it, nothing bad will happen):
program PointerArithmetic;
{$APPTYPE CONSOLE}
uses
SysUtils;
procedureWritePointer(P: PDouble);
begin
Writeln(Format('%8p', [P]));
end;
var
P: PDouble;
begin
P := Pointer($50000);
WritePointer(P);
Inc(P); // 00050008 = 00050000 + 1*SizeOf(Double)
WritePointer(P);
Inc(P, 6); // 00050038 = 00050000 + 7*Sizeof(Double)
WritePointer(P);
Dec(P, 4); // 00050018 = 00050000 + 3*Sizeof(Double)
WritePointer(P);
Readln;
end.
The output is:
00050000
00050008
00050038
00050018
The utility of this is to provide sequential access to arrays of such types. Since (one-dimensional) arrays contain consecutive items of the same type — i.e. if one element is at addressN, then the next element is at address N+SizeOf(element) —, it makes sense to use this to access items of an array in a loop. You start with the base address of the array, at which you can access the first element. In the next iteration of the loop, you increment the pointer to access the next element of the array, and so on, and so forth:
program IterateArray;
{$APPTYPE CONSOLE}
var
Fractions: array[1..8] of Double;
I: Integer;
PD: ^Double;
begin
// Fill the array with random values.
Randomize;
for I := Low(Fractions) to High(Fractions) do
Fractions[I] := 100.0 * Random;
// Access using pointer.
PD := @Fractions[Low(Fractions)];
for I := Low(Fractions) to High(Fractions) do
begin
Write(PD^:9:5);
Inc(PD); // Point to next item
end;
Writeln;
// Conventional access, using index.
for I := Low(Fractions) to High(Fractions) do
Write(Fractions[I]:9:5);
Writeln;
Readln;
end.
Incrementing a pointer is, at least on older processors, probably slightly faster than multiplying the index with the size of the base type and adding that to the base address of the array for each iteration.
In reality, the effect of doing it this way is not nearly as big as you might expect. First, modern processors have special ways of addressing the most common cases using an index, so there is no need to update the pointer too. Second, the compiler will generally optimize indexed access into the pointer using version anyway, if this is more beneficial. And in the above, the gain found by using a slightly more optimized access is largely overshadowed by the time it takes to perform the Write().
As you can see in the program above, you can easily forget to increment the pointer inside the loop. And you must either usefor-to-do anyway, or use another way or counter to terminate the loop (which you must then also decrement and compare manually). IOW, the code using the pointer is generally much harder to maintain. Since it is not faster anyway, except perhaps in a very tight loop, I would be very wary of using that kind of access in Delphi. Only do this if you have profiled your code and found pointer access to be beneficial and necessary.
Pointers to arrays
But sometimes you only have a pointer to access memory. Windows API functions often return data in buffers, which then contain arrays of a certain size. Even then, it is probably easier to cast the buffer to a pointer to an array than to use Inc or Dec. An example:
type
PIntegerArray = ^TIntegerArray;
TIntegerArray = array[0..65535] of Integer;
var
Buffer: array of Integer;
PInt: PInteger;
PArr: PIntegerArray;
...
// Using pointer arithmetic:
PInt := @Buffer[0];
for I := 0 to Count - 1 do
begin
Writeln(PInt^);
Inc(PInt);
end;
// Using array pointer and indexing:
PArr := PIntegerArray(@Buffer[0]);
for I := 0 to Count - 1 do
Writeln(PArr^[I]);
...
end;
Delphi 2009
In Delphi 2009, pointer arithmetic, as usable for the PChar type (andPAnsiChar and PWideChar), is now also possible for other pointer types. When and where this is possible is governed by the new$POINTERMATH compiler directive.
Pointer arithmetic is generally switched off, but it can be switched on for a piece of code using {$POINTERMATH ON}, and off again using {$POINTERMATH OFF}. For pointer types compiled with pointer arithmetic (pointer math) turned on, pointer arithmetic is generally possible.
Currently, besides PChar, PAnsiChar and PWideChar, the only other type for which pointer arithmetic is enabled by default is thePByte type. But switching it on for, say, PInteger would simplify the code above considerably:
{$POINTERMATH ON}
var
Buffer: array of Integer;
PInt: PInteger;
...
// Using new pointer arithmetic:
PInt := @Buffer[0];
for I := 0 to Count - 1 do
Writeln(PInt[I]);
...
end;
{$POINTERMATH OFF}
So there is no need for the declaration of special TIntegerArray andPIntegerArray types to be able to access the type as an array anymore. Alternatively, instead of PInt[I], the (PInt + I)^ syntax could have been used, with the same result.
Apparently, in Delphi 2009, the new pointer arithmetic doesn't work as intended for pointers togeneric types yet. Whatever type the parametric type is instantiated as, indices are not scaled bySizeOf(T), as expected.
References
Many types in Delphi are in fact pointers, but pretend not to be. I like to call these typesreferences. Examples are dynamic arrays, strings, objects and interfaces. These types are all pointers behind the scenes, but with some extra semantics and often also some hidden content.
Multi-dimensional dynamic arrays
What distinguishes references from pointers is:
References are immutable. You can not increment or decrement a reference. References point to certain structures, but never into them, like for instance the pointers that point into an array, in the examples above.
References do not use pointer syntax. This hides that they are in fact pointers, and makes them hard to understand for many, who do not know this, and therefore do things with them they would better not do.
Do not confuse such references with C++'s reference types. These are different in many ways.
动态数组
在Delphi4之前,动态数组还不是语言的一个特性,但存在这个概念.动态数组是运行时分配的内存块,并通过指针进行管理.动态数组可以增长或压缩.这意味着需要重新分配指定大小的内存块,原来内存块中的内容需要拷贝到新的内存块中,原来内存块被释放掉,指针指向新的内存块.
Delphi中的动态数组(如array of Integer)类型也是这样的.但由运行时附件的代码来管理内存的读取和分配.如下的内存存储单元指针指向的地址有两个附加的域:分配的元素数量和引用数量.
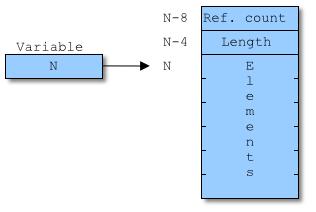
如果如上图所示,N是动态数组变量的地址,那么引用数量(reference count)的地址就是N-8,分配的元素数量(length指示器)是N-4.第一个元素的地址是N.
每增加一个引用(如赋值,参数传递等),引用计数就加一,每次解除引用(如离开变量的作用域,或包含动态数组成员的对象被释放,或指向动态数组的变量指向了其他动态数组或nil)引用计数就减一.
使用低层次例程Move或FillChar或其他例程如TStream.Write存取动态数组经常出错.对于一个正常的数组(为区别于动态数组,将其叫做静态数组),变量与内存块等价的.而对于动态数组,情况就不是这样的了.因此如果一个例程想要按内存块的方式存取数组中的元素,就不能引用动态数组变量,而是需要使用动态数组中的第一个元素.
var
Items: array of Integer;
...
// Wrong: address of Items variable is passed
MyStream.Write(Items, Length(Items) * SizeOf(Integer));
...
// Correct: address of first element is passed
MyStream.Write(Items[0], Length(Items) * SizeOf(Integer));
注意上面代码中, Stream.Write 使用无类型的var 参数,也是引用传值.下面会进行讨论.
多维动态数组
上面讨论的是一维动态数组.动态数组也可以是多维的.但只是语法层面上的,事实上不是的.多维动态数组实际上是一个指向另外一维数组的一维数组.
假如有如下声明:
type
TMultiIntegerArray = array of array of Integer;
var
MyIntegers: TMultiIntegerArray;
现在看起来声明了一个多维数组,而且可以通过MyIntegers[0, 3]的方式存取其中的元素.但是声明的类型应该这样读(语法层面上):
type
TMultiIntegerArray = array of (array of Integer);
或者更加明确的描述为:
type
TSingleIntegerArray = array of Integer;
TMultiIntegerArray = array of TSingleIntegerArray;
可见, TMultiIntegerArray 事实上是一个指向TSingleIntegerArray的一维数组.这样TMultiIntegerArray存储区域就不是按行和列排列的连续内存块,实际上是不定长的数组,如每个元素都指向了另一个数组,每个子数组都有不同的大小.因此对于
SetLength(MyIntegers, 10, 20);
(将分配10个TSingleIntegerArrays ,每个子数组有20个整数,表面上是一个矩形数组), 可以存取和修改每个子数组:
SetLength(MyIntegers, 10);
SetLength(MyIntegers[0], 40);
SetLength(MyIntegers[1], 31);
// etc...
字符串
Should array indices start at 0 or 1? My compromise of 0.5 was rejected without, I thought, proper consideration. — Stan Kelly-Bootle
字符串在很多方面都与动态数组相同.也有引用计数,有相同的内部结构,一个引用计数和指示其中存储的字符串数据的长度(在同样的偏移量上).
不同之处在语法和语义上.不能将字符串设置为nil,可以设置为'' (空字符串)来清空他.字符串也可是一个常量(引用计数是-1,运行时例程中将其作为一个特殊值对其进行增减或释放字符串).第一个元素的索引是1,而动态数组的第一个元素索引是0.
字符串更多信息见article about PChars and strings.
对象
对象— 更确切的说是类的实例,编译器不会管理其生命周期.其内部结构很简单.每个类实例的0偏移量处(相对于每个引用的指针执行的地址)有一个指针指向VMT表.其中包含指向类中的每个虚方法的指针.这个表的负偏移量中是关于类的其他信息.对此不作过多介绍.每个类只有一个VMT表(而不是每个对象).
实现了接口的类也有一个指向含有接口中被实现的方法表的指针,每个被实现的接口对应一个.这个表在负偏移量中也有一些额外的信息.这些偏移量处的对象指针指向与基类相关域的信息.编译器知道具体细节.
在VMT指针和接口表指针后面,是对象的域,与结构体相似.
对象的RTTI数据和其他类的信息从对象的这些引用中获取,如VMT指针指向的VMT表中等.编译器知道如何获取其余的数据,通常通过包含其他结构体指针的复杂结构体,甚至会循环引用来获得.
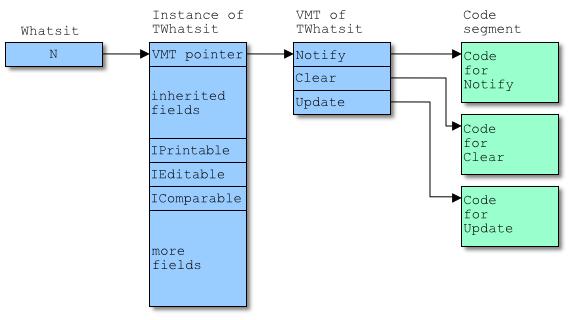
下例中,假设如下声明:
type
TWhatsit = class(TAncestor, IPrintable, IEditable, IComparable)
// other field and method declarations
procedure Notify(Aspect: TAspect); override;
procedure Clear; override;
procedure Edit;
procedure ClearLine(Line: Integer);
function Update(Region: Integer): Boolean; virtual;
// etc...
end;
var
Whatsit: TWhatsit;
begin
Whatsit := TWhatsit.Create;
对象布局如下图:
接口
接口实际上上方法的集合.在内部,他们是指向一个指向了代码的指针数组.假如有如下声明:
type
IEditable = interface
procedure Edit;
procedure ClearLine(Line: Integer);
function Update(Region: Integer): Boolean;
end;
TWhatsit = class(TAncestor, IPrintable, IEditable, IComparable)
public
procedure Notify(Aspect: TAspect); override;
procedure Clear; override;
procedure Edit;
procedure ClearLine(Line: Integer);
function Update(Region: Integer): Boolean; virtual;
// etc...
end;
var
MyEditable: IEditable;
begin
MyEditable := TWhatsit.Create;
接口,实现对象,实现类和方法的关系如下:
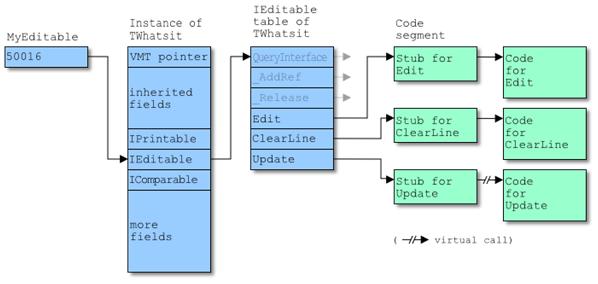
MyEditable 指向了由TMyClass.Create创建对象中的IEditable指针.注意MyEditable 不是指向对象的起始地址,而是有一个偏移量.MyEditable指向对象中的一个指向指针列表的指针,其中包括接口中的每个方法实现.代码会调整Self 指针(事实上指向了MyEditable) 指向一个对象的起始地址(通过在传递的指针中减去对象中IEditable的偏移量,然后调用真正的方法).这是类实现的接口中方法的存根.
例如,假设实例的地址是50000, TWhatsit实现的IEditable接口在实例中指针偏移量是16.那么MyEditable指向50016. 50016处的IEditable 指针指向了在类中实现的接口方法表(例如在30000),而后指向方法的存根(如在60000).存根知道由Self传递的值在50016,减去16得到50000.只是实现接口的对象地址.存根而后通过将50000作为Self的地址调用真实的函数.
上图为简化忽略的QueryInterface, _AddRef和_Release的存根.
知道为什么需要用铅笔盒纸张了吧? ;-)
引用参数
引用参数通常叫做var 参数,但out 参数也是引用参数.
引用参数在实际传参时并不会将真正的值传递给例程,而是传递参数地址.例如:
procedure SetBit(var Int: Integer; Bit: Integer);
begin
Int := Int or (1 shl Bit);
end;
或多或少等价于下面的代码:
procedure SetBit(Int: PInteger; Bit: Integer);
begin
Int^ := Int^ or (1 shl Bit);
end;
不同之处:
没有使用指针语法.使用参数名称自动进行对参数解引用,即使用参数名称就可操作目标变量,而不是指针.
引用参数不能被修改.使用参数名称来执行目标变量,不能将其指向其他地址,或对其增减操作.
必须传递有地址的变量,例如,一个实际的内存存储单元需要做一些变换.因此对于整型的引用参数,不能传递为17, 98765,或 Abs(MyInteger). 必须是一个变量(包括数组中的元素,对象或结构体中的成员等).
实参必须与声明的参数类型相同,如,对声明为TObject的参数不能传递为TEdit.为避免这个问题需要声明无类型引用参数(untyped reference parameters).
语法上使用引用参数要比使用指针参数简单.但需要注意一些潜规则.传递指针,增加了一级间接引用.换句话说如果使用指针P指向一个整数,要传递参数必须转换为P^:
var
Int: Integer;
Ptr: PInteger;
Arr: array of Integer;
begin
// Initialisation of Int, Ptr and Arr not shown...
SetBit(Ptr^, 3); // Ptr is passed
SetBit(Arr[2], 11); // @Arr[2] is passed
SetBit(Int, 7); // @Int is passed
无类型参数
无类型参数也是引用参数,但可以是var, const或out.可以传递任意类型的参数,简化了可以接受任意大小和类型参数的例程编写,但是这也需要有机制传递参数的类型信息,或作为类型无关的例程.访问参数时必须进行类型转换.
内部无类型参数也是作为指针传递的.如下两个范例中,第一个通用例程可以填充任意大小的缓冲区,而参数Buffer的类型并不重要:
// Example of routine where type doesn't matter
procedure FillBytes(var Buffer; Count: Integer;
Values: array of Byte);
var
P: PByte;
I: Integer;
LenValues: Integer;
begin
LenValues := Length(Values);
if LenValues > 0 then
begin
P := @Buffer; // Treat buffer as array of byte.
I := 0;
while Count > 0 do
begin
P^ := Values[I];
I := (I + 1) mod LenValues;
Inc(P);
Dec(Count);
end;
end;
end;
第二个TTypedList 的子类TIntegerList中的方法:
function TIntegerList.Add(const Value): Integer;
begin
Grow(1);
Result := Count - 1;
// FInternalArray: array of Integer;
FInternalArray[Result] := Integer(Value);
end;
可见,使用指针必须传递一个实参地址,即使参数已经是需要的指针了.而且,间接引用级别增加.
要存取引用目标,可以简单的作为正常的引用参数使用,但必须进行类型转换,编译器指定如何对指针进行解引用.
注意间接引用级别.如果需要使用FillBytes函数初始化动态数组,不能传递变量,而是需要传递数组中第一个元素.事实上,也可传递静态数组的首地址.因此如果要将数组作为无类型引用参数的实参进行传递,最后传递第一个元素而不是数组本身,除非要故意的访问错误的动态数组.
数据结构
指针很广泛的用于数据结构中,如链接列表,树和层等.在此不作讨论.需要说明的是高级的结构没有指针和引用是无法实现的,虽然很多语言(Java)官方说不使用指针.要了解更多结构的信息请阅读相关专题的文档.
如下是简单的数据结构图表,非常依赖于指针的链接列表:

如果使用这样的结构,通常都是在类内部进行了封装,使用指针可以减少类内部的实现难度,但不会将指针暴露在公共接口中.指针很强大,但很难驾驭,尽量避免使用.
结论
这里给出了很多指针的知识面.另一方面,使用带箭头的图表对理解复杂指针或接口变量,对象,类和代码间的关系很有帮助.绘制的图都是用于理解非常复杂的指针.
本文要阐述的是指针无处不在,即使没有看到他们.但不能滥用,理解指针可以更好的理解下层机制,可以避免很多错误.
希望对于大家有所帮助.本文一定不是很全面,需要改进之处请e-mail.
Rudy Velthuis
https://blog.csdn.net/henreash/article/details/7368088