先看一张图,对DRF的各个APIView,Mixin,Viewset等有个基本印象:
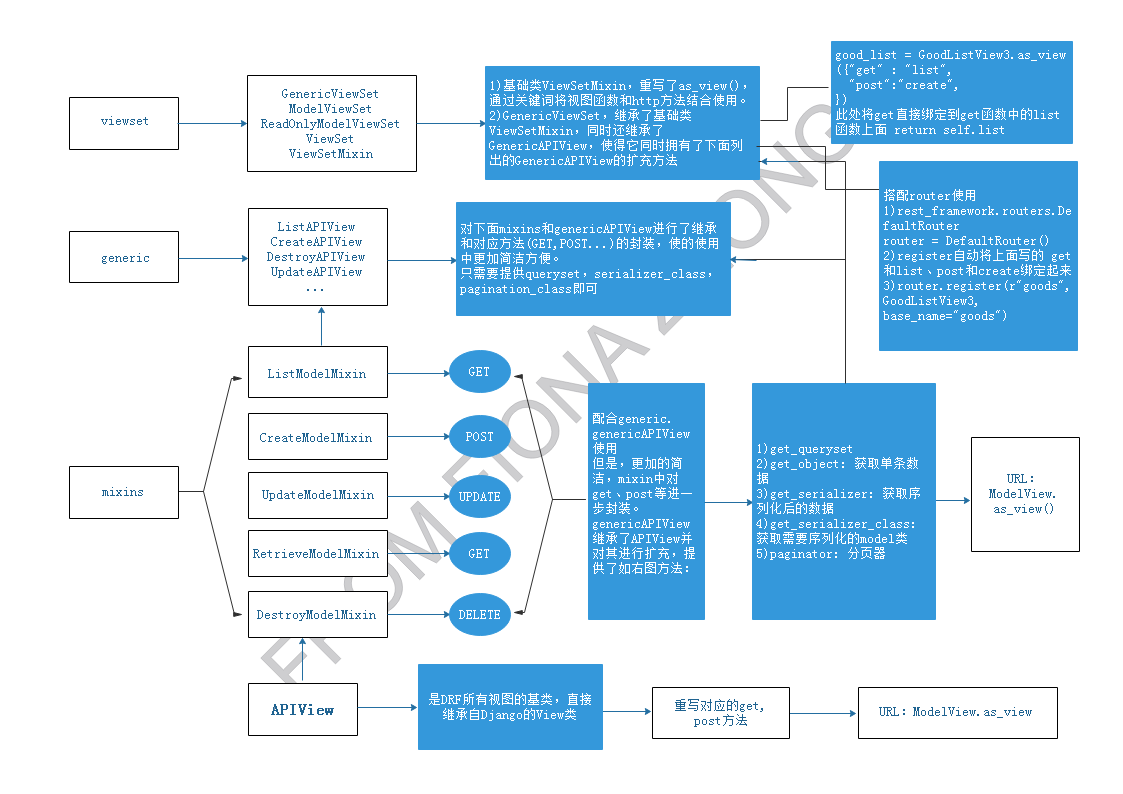
具体使用方法:
1、APIView:
DRF 的API视图 有两种实现方式:
一种是基于函数的:@api_view
一种是基于类的:APIView,APIView是Restframework提供的所有视图的基类,继承自Django的View父类
1)@api_view
使用@api_view装饰器,使得我们此处的Request不在是Django标准的HttpRequest,而是restframework的Request。
默认情况下,只有GET请求会被接收,它也允许我们自己配置函数允许接收的请求类型
@api_view():默认只接收GET请求
@api_view(http_method_names=['GET']):指明接收的请求类型
@api_view(['GET', 'POST']):接收get post请求
@api_view(['GET','POST'])
def Snippet_list(request):
if request.method=="GET":
pass
elif request.method == "POST":
pass
2)APIView
APIView是基于类的装饰器,显然,类视图更符合面向对象的原则,它支持GET POST PUT DELETE等请求类型,且各种类型的请求之间,有了更好的分离
在进行dispatch分发之前,会对请求进行身份认证,权限检查,流量控制。
支持定义的属性:
authentication_classes=():列表或元组,身份认证类
permission_classes=():列表或元组,权限检查类
throttle_classes=():列表或元组,流量控制类
class Snippet_list(APIView):
def dispatch(self, request, *args, **kwargs):
# 请求到来之后,都需要执行dispatch方法,dispatch根据请求方式的不同,分别触发对应的get post, put等方法
return super().dispatch(request, *args, **kwargs)
def get(self, request, pk, format=None):
snippet = Snippets.objects.get(pk=pk)
serializer = SnippetSerializer(snippet, many=True)
return Response(serialzer.data)
def post(self, request):
serializer = SnippetSerializer(data = request.data)
if serializer.is_valid():
serializer.save()
return Response(serializer.data, status=status.HTTP_201_CREATED)
return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)
def delete(self, request, pk, format=None):
snippet = Snippets.object.get(pk=pk)
snippet.delete()
return Response(status=status.HTTP_204_NO_CONTENT)
配置url:
urlpatterns = [
url(r"^snippets/(?P<pk>[0-9]+)$", Snippet_list.as_view()),
]
2、mixins
使用基于类的视图的一个最大的好处就是我们可以灵活的选择各种View,使我们的开发更加的简洁
mixins里面对应了ListModelMixin,CreateModelMixin,RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin
这些Mixin方法,对我们上面APIView中重写的GET POST PUT DELETE进行了封装,使得我们的代码更加简洁
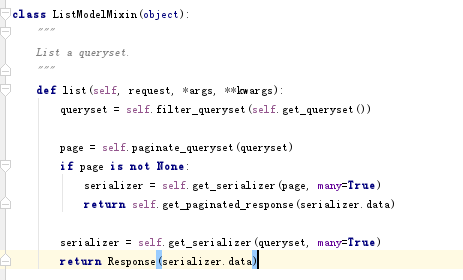
下面是使用mixin的例子:
GenericAPIView继承了APIView,通过GenericViewSet来构建我们的视图,然后组合ListModelMixin和CreateModelMixin来实现我们上面的代码功能
基类提供了核心的功能,ListModelMixin和CreateModelMixin提供了.list()和.create()函数,下面我们将get和post与.list和.create绑定起来
class snippet_list(mixins.ListModelMixin, generic.GenericAPIView):
queryset = Snippet.objects.all()
serializer_class = SnippetSerializer
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)
3、使用generic
我们上面使用mixin的代码,已经非常简洁了,但是restframework给我们提供了一组混合的generic视图,可以使我们的代码 大大简化
GenericAPIView:继承自APIView,增加了对列表视图或者详情视图可能用到的通用支持方法。通常使用时,可搭配一个或者多个Mixin扩展类
支持定义的属性:
列表视图与详情视图通用:queryset(视图的查询集), serializer_class(视图使用的序列化器)
列表视图专用:pagination_classes(分页控制类),filter_backends(过滤控制)
详情页视图专用:lookup_field(查询单一数据库对象时使用的条件字段,默认为pk)
提供的方法:
通用:
1)get_queryset(self):返回视图使用的查询集,是获取数据的基础,默认返回queryset,可以重写:
def get_queryset(self):
user = self.request.user
return user.accounts.all()
2)get_serializer_class(self):返回序列化器,默认返回serializer_class,可以重写,如:
def get_serializer_class(self):
if self.request.user.is_staff:
return AllAccountSerializer
return BasicAccountSerializer
3)get_serializer(self, *args, **kwargs):返回序列化器对象
详情视图使用:
get_object(self):返回详情视图所需的模型类数据对象,默认使用lookup_field参数来过滤queryset
该方法默认使用APIView提供的check_object_permissions方法检查当前对象是否有权限被访问
class SnippetDetail(GenericAPIView):
queryset = Snippets.objects.all()
seriazlier_class = SnippetSerializer
def get(self, request, pk):
snippet = self.get_object()
serializer = self.get_serializer(snippet)
return Response(serialzier.data)
url:url(r"^snippet/?P<pk>[0-9]+/$", SnippetDetail.as_view())
五个扩展类:generics.ListAPIView, generics.CreateAPIView, generic.RetrieveAPIView, generic.UpdateAPIView, generic.DestroyAPIView,它们会继承GenericAPIView和mixin对应的视图

上面可以看到generics.ListAPIView里面做的事情,它替我们继承了mixins.ListModelMixin和GenericAPIView,还重写了get方法,所以我们直接继承generic.ListAPIView,代码就会更简洁,
只需要设置一下queryset和serializer_class即可,如下:
class snippet_list(generics.ListAPIView):
queryset = Snippet.objects.all()
serializer_class = SnippetSerializer
4、视图集ViewSet
使用视图集ViewSet,可以将一系列逻辑相关的动作放到一个类中。
list():提供一组数据
retrieve():提供单个数据
create():创建数据
destroy():删除数据
update():修改数据
ViewSet主要是和路由搭配使用,将我们通常使用的get, post等和方法和ViewSet实现的action如list(), create()等对应上。
action属性:
在视图集中,我们可以通过action对象属性来确定当前请求视图集时的action动作是哪个
def get_serializer_class(self):
if self.action == "create":
return SnippetCreateSerializer
else:
return SnippetListSerializer
url配置:
urlpatterns = [
url(r"^snippet/$", SnippetViewSet.as_view({"get":"list", "post":"create"})),
url(r"^snippet/?P<pk>[0-9]+/$", SnippetViewSet.as_view({"get":"retrive"})),
]
上面url配置,是我们手动的将请求方式和action动作对应起来,其实restframework也已经帮我对应好了,它是通过Router模块来完成的,我们只需要使用router将对应的视图注册即可。
from rest_framework.routers import DefaultRouter
router = DefaultRouter()
router.register(r"snippet", SnippetViewSet)
urlpatterns = [
url(r"^", include(router.urls))
]
5、Django restframework 过滤器
如过滤文章阅读量小于100的:
class ArticleViewSet(mixins.ListModelMixin, viewsets.GenericViewSet):
def get_queryset(self):
read_nums = self.query_params.get("readNums", 0)
if read_nums:
return Article.objects.filter(read_nums__lt=int(read_nums))
return Article.objects.all()
上面这种方式,如果过滤字段少的话,可以方便使用,但是如果过滤字段多,那代码量就会很繁复了。如果还想要用简洁的代码实现大量的过滤逻辑,就需要用到其他方法,如django-filter
pip install django-filter,并将django-filter加入到INSTALLED_APPS中。
如:
from django_filters.rest_framework import DjangoFilterBackend
class ArticleViewSet(mixins.ListModelMixin, viewsets.GenericViewSet):
queryset = Article.objects.all()
serializer_class = ArticleSerialzier
filter_backends = (DjangoFilterBackend, )
filter_fields = ("name", "title")
这种写法相对于上面第一种写法就简单很多了,但是如果我们想要查询阅读数量大于10,小于100的文章要怎么办呢?所以这种写法还是有他的局限性,要实现这种情况的过滤,需要我们自定义过滤器:
新建filters.py
import django_filters
class ArticleFilter(django_filters.rest_framework.FilterSet):
title= django_filters.CharFilter(lookup_expr='icontains')
readNums = django_filters.NumberFilter(lookup_expr="gte")
class Meta:
model = Article
fields = ["min_readers","readNums", "clickNums"]
说明:
上面:model:Article---指出该类是为Article 这个model定义的过滤类
lookup_expr------指出过滤条件,是包含,还是大于或是其他,后面会想起说明
fields----------------指定了支持过滤的字段,如果fields中指定了字段,但是没有指定过滤方法,则表示精确查询
view中使用:
class SnippetViewset(mixins.ListModelMixin, viewsets.GenericViewSet):
queryset = Article.objects.all()
serializer_class = ArticleSerializer
filter_backends = (DjangoFilterBackends, )
filter_class = ArticleFilter
多表过滤:
class Book(model.Model):
name = model.CharField(max_length = 50)
class Author(model.Model):
name = model.CharField(max_length=20)
book = model.ForeignKey(Book)
例如上面的作者和书是一对多的关系,一个人可以写多本书。那么我们想要通过书本的名字去查询它的作者,要怎么做呢?
class AuthorFilter(django_filters.rest_framework.FilterSet):
book__name = django_filters.CharFilter(lookup_expr='icontains')
class Meta:
model = Author
fields = ["book__name"]
在View中使用:
按照上面的单表查询的View写法也是可以的,这里我们通过另一种重写list的方式来完成,旨在说明自定义分页的写法。
class AuthorViewSet(mixins.ListModelMixin, viewsets.GenericViewSet):
queryset = Author.objects.all()
serializer = AuthorSerializer
def list(self, request, *args, **kwargs):
object = AuthorFilter(request.query_params, queryset=self.queryset)
# 过滤后查询出的数据
filterRecords = object.qs.count()
# 前端传过来的参数:当前第几页
curP = int(request.query_params.get("p", 0))
# 前端传过来的参数:每页有几条数据
size = int(request.query_params.get("s", 0))
if curP and size:
start = (curP-1)*size
length = size
else:
start = 0
length = filterRecords
# 通过调用过滤器的返回值的qs来处理自定义分页,有兴趣的话可以去django.db.model.query.py中去看看
object = object.qs[start:(start+length)]
serializer = self.get_serializer(object, many = True)
return Response(serializer.data)