一、什么是神经网络
神经网络模型(KNN)来源于生物体的神经系统,是一组连接的输入/输出单元,每个连接都与一个权重相关联。神经网络模式可以学习数据的特点,训练的数据不同,产生的模型不同。
应用场景:不知道用什么数学模型合适;知道应用什么模型但不知道模型复杂度时可以使用。比如要做分类问题,但属于非线性的切分,此时想用LR或SVM但又不知道用什么样的特征工程可以实现非线性切分,这个时候就可以用到神经网络。神经网络可以完成分类、回归、聚类等问题。
优点:对未经训练的数据的模式分类能力强,能够模拟很强的非线性决策边界及关系,当缺乏属性与类之间联系的知识时,可以使用它们。同时它也不像大多数决策树算法,非常适合连续值的输入和输出。
缺点:需要很长的训练时间;解释性差,人们很难解释神经网络中学习的权重和“隐含单元”的符号含义。
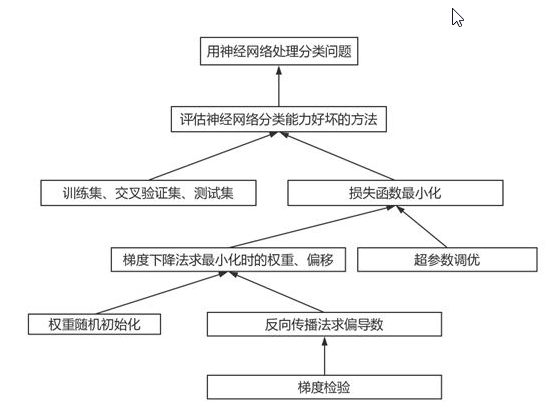
二、神经网络的构成
感知器:从一个神经元,到另一个神经元之间的传递,经过一个线性变换,再经过一个非线性变换。Z是一些输入值的线性变换,Z=WX+b,b为偏置项,X为输入的信号值。g(z)是传递函数,对Z做了一个非线性变换,该函数可以是sigmoid、Relu、tanh等,可以理解成控制信号传递强弱,另外如果不加g函数,中间无论加多少个隐藏层也都是线性变换。
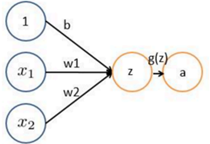
添加少量隐藏层,加入多个神经元,构成浅层神经网络(SNN)
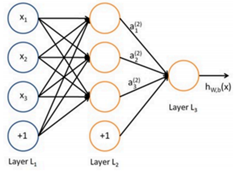
增多中间层,由此得到深度神经网络(DNN)
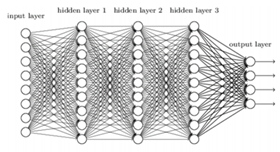
三、神经网络空间切分原理
神经网络对于非线性的切分问题,要优于LR和SVM,例如下面图中例子,如果用一条直线无法完成分类,需要两条直线分类器。而神经网络可以在第一层完成一次输入后,通过第二层的类似于计算机的and操作,只有当X1,X2同时为完成两个线性分类器的与操作,从而实现非线性切分。同样,神经网络也可以完成or操作。
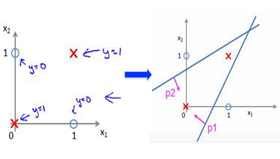
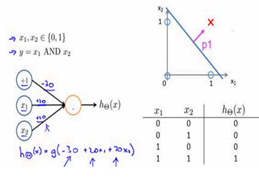
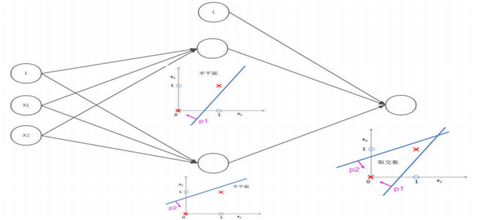
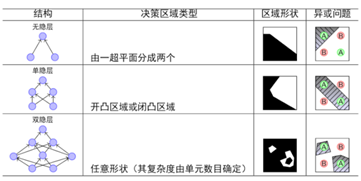
当无隐藏层,只是个感知器时,类似于线性分类器LR和SVM,由一个超平面分成两个;含有单个隐藏层时,可以完成“与”操作,决策区域可以是开凸区域或闭凸区域;而含有多个隐藏层时,通过对线性分类器的“与”和“或”的组合,完美的对空间区域切分,完成分类。
神经元的表达力与过拟合:理论上说单隐层神经网络,只要隐藏的神经元个数足够多,可以构成多个线性分类器,可以逼近任何连续函数,完成分类,但是这种效果远远弱于多隐藏层神经网络。但是,需要注意,如果不是图像或语音等复杂数据,对于人工神经网络,3层神经网络效果优于2层,但如果把层数再不断增加(4,5,6层),对于最后的结果就没有那么大帮助了。过多的隐层和神经元节点会带来过拟合问题。但是不要试图通过降低神经网络参数量来减缓过拟合,用正则化或者dropout。
四、BP神经网络
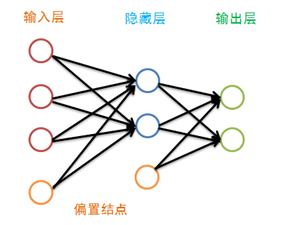
神经网络有很多种:前向传输网络、反向传输网络、递归神经网络、卷积神经网络等。本文介绍基本的反向传输神经网络,BP 神经网络中的 BP 为 Back Propagation 的简写。神经网络每一次的输出都可以追溯到上一层输入,直到第一层,由此而来BP神经网络。在BP神经网络中,只有相邻的神经层的各个单元之间有联系,除了输出层外,每一层都有一个偏置结点(有些地方翻译为偏倚,偏置结点是为了描述训练数据中没有的特征,偏置结点对于下一层的每一个结点的权重的不同而生产不同的偏置):
该机器学习算法,依旧要定义一个损失函数,根据这个损失函数最小化,去求每层的权重和b,隐藏层的个数K也是未知参数。首先,正向传播求损失,如果是回归问题,损失函数为离差平方和最小;如果是分类问题,损失函数为交叉熵(求exi/sum(exi)(概率向量)与[1,0,0..]的KL距离)。假设只有三层感知器时,回归问题的损失函数可以做如下推导。可以看到最后得出的损失函数十分复杂,是一个嵌套函数的形式。由于这个lossfunction是非凸的,不能用梯度下降GD,但可以用SGD随机梯度下降,一个一个样本丢进来做梯度更新,不一定能找到全局最低点,但能找到接近最低点的低点。BP神经网络之所以叫反向传播神经网络,因为对损失函数求导时,要追溯到对前面的函数一层一层求导。反向传播回传误差,根据误差信号修正每层的权重。

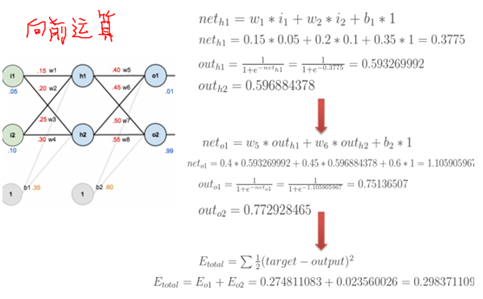
具体的算法,可以看下图中的例子,把每一步的过程讲的很清楚,来自于寒小阳老师的课件。1.先是随机假定参数w和b,g(x)为sigmoid函数,求出各部分的输入、输出值。
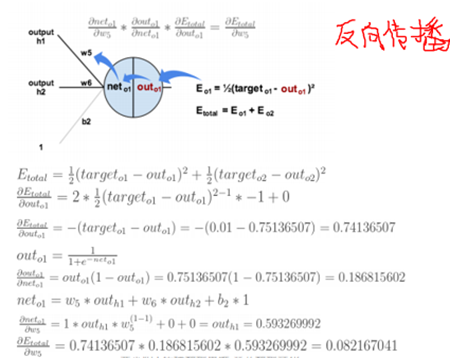
2.反向传播,求出各个部分的偏导,求出最后一层中误差对于分别对于w5,w6,w7,w8的偏导。
3.通过梯度下降,先更新参数w5,w6,w7,w8;再更新前一层的参数w1,w2,w3,w4。

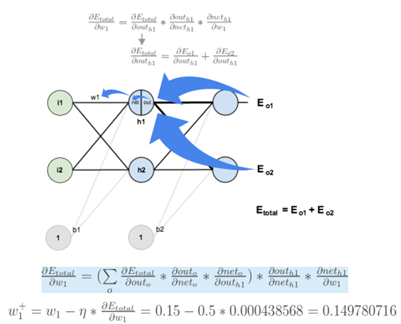
通过更新权值和偏倚的方式,以反映误差的传播,不断调整,处理每一个样本都有更新权重和偏倚,直到:设置最大迭代次数,比如使用数据集迭代100次后停止训练;计算训练集在网络上的预测准确率,达到一定门限值后停止训练。
五、神经网络使用
神经网络用的是标准数据的转置。
神经网络一般将样本分为训练集、测试集和验证集(用于调整参数)。
神经网络中需要求解的参数包括权重w,偏置项b。可以调整的超参数包括,,隐藏层节点数,神经网络层数,训练次数、梯度下降过程的步长,用于随机梯度下降法的最小样本数(mini_batch_size)等等。超参数是影响所求参数最终取值的参数,是机器学习模型里面的框架参数,可以理解成参数的参数,它们通常是手工设定,不断试错调整的,或者对一系列穷举出来的参数组合一通进行枚举(网格搜索)来确定。
每层的神经元的个数可以考虑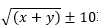 左右,x为输入个数,y为输出的个数。
左右,x为输入个数,y为输出的个数。
下图来自龙心尘老师博客,写的很详细http://blog.csdn.net/longxinchen_ml/article/details/50082873#comments