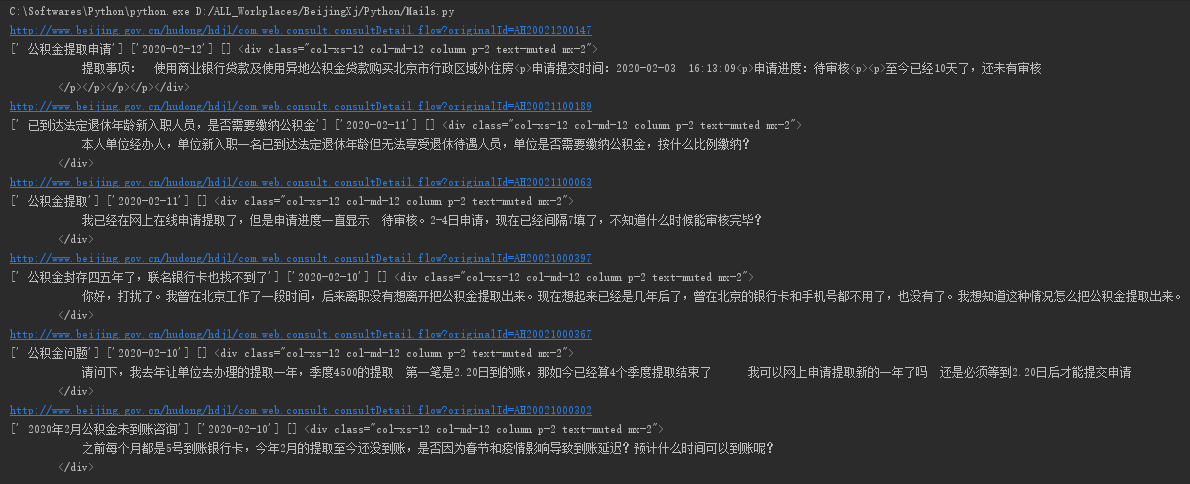
在爬取详细信息页面中,又遇到了问题,就是标签内的信息爬取,用re的正则表达式没有找到解决办法,只能又去网上搜索解决办法
用bs4来解决,用
soup = BeautifulSoup(text,"html.parser")#解析text中的HTML
来进行分析,虽说这样会有标签信息附着,从网上找到解决办法,
第一种方法
调用find(text=True).strip()
第二种方法
调用stripped_strings
第三种方法
.get_text().lstrip().rstrip()
个人感觉第三种很好用,在实践之后特意添加
经过测试,不是很理想,对于简单的,只有div标签的很容易,对于第一种,好多p标签的就不好用了,正在寻找更加实用的代码
for add in ad:
r = add
address_ = "http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId=%s" % add
print(address_)
# 爬取子页面的网页
html2 = requests.get(address_,headers = head2).text
reqname = re.findall(r'<div class="col-xs-10 col-sm-10 col-md-10 o-font4 my-2"><strong>(.*?)</strong></div>',html2)
reqtime = re.findall(r'<div class="col-xs-5 col-lg-3 col-sm-3 col-md-3 text-muted ">时间:(.*?)</div>',html2)
reqcontent = re.findall(r'<div class="col-xs-12 col-md-12 column p-2 text-muted mx-2">(.*?)</div>',html2)
# resname = re.findall(r'<strong>[官方回答]:</strong>(.*?)</div>',html2)
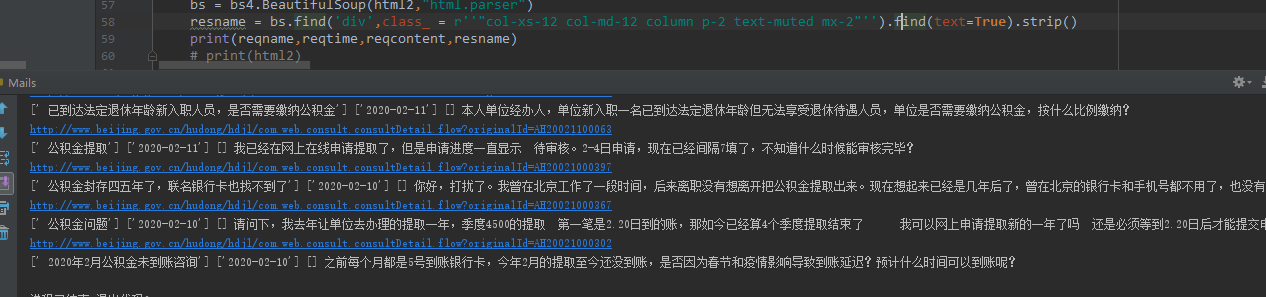
bs = bs4.BeautifulSoup(html2,"html.parser")
resname = bs.find('div',class_ = r''"col-xs-12 col-md-12 column p-2 text-muted mx-2"'')
print(reqname,reqtime,reqcontent,resname)
# print(html2)